
생성적 AI는 화가 나게 만드는 괴로운 발전으로 가장 잘 설명될 수 있습니다. 2022년 말에 처음 출시된 ChatGPT는 자연어의 품질에 대해 현혹되고 광활한 놀라움을 줬습니다. 그 이후로 그 제품에 대한 다수의 업데이트와 경쟁 제품이 등장했습니다.
하지만 초기의 흥분은 기술에 대한 다수의 좌절로 바뀌었습니다. 이러한 모델의 출력을 조절하는 것은 어려운 것으로 보이며, 환각 때문에 생성물의 내용이 항상 신속하지만 신뢰할 수 없다는 것이 문제입니다. 마감일 때문에 내용이 뒤늦어지고, 모델은 특정 요청에 대한 배경지식이 부족하기 때문에 대답이 종종 올바르지 않거나 유용하지 않게 일반적일 수 있습니다, 특히 조직이나 비즈니스 설정에서.
검색 증강 생성(RAG)은 큰 언어 모델을 더 효과적으로 사용하는 방법입니다. 비용이 크게 들지 않고 간단한 워크플로우를 사용하여, 모델에 관련된 맥락 정보를 제공하고 주어진 정보를 기반으로 답변하거나 주어진 정보를 우선시하여 반응하도록 제한할 수 있습니다. 이러한 방식으로, 큰 언어 모델의 실제 가치가 발휘됩니다 — 컨텐츠의 자동 자연어 요약기로서, 환각과 같은 원치 않는 행동은 최소화되거나 아예 제거될 수 있습니다.
위의 내용을 번역하겠습니다.
이를 설명하기 위해 저는 통계 교재 Regression Modeling Handbook에 관한 질문에 답변하는 RAG 애플리케이션의 최소 버전을 만들었던 기술적 자습서를 제작했습니다. 이 자습서의 끝에서는 교재에 있는 내용만을 기반으로 질문을 할 수 있는 간단한 파이프라인을 만들었을 것입니다. 그래서 이것은 귀하의 질문에 답변하기 위해 제 통계 지식만을 사용하는 제 AI 버전과 같습니다.
이 자습서는 제 교재를 포함한 모든 자료가 오픈 소스로 제공되기 때문에 완전히 재현 가능합니다. 심지어 제가 사용하는 LLM도 오픈 소스인데요 (Google의 Gemma-7b LLM, 그것이 Gemini 제품의 기초입니다). 그러나 주의할 점이 있습니다: 저는 극도로 고사양의 기계인 MacBook M1 Max with 128GB RAM을 사용하고 있으므로 Gemma를 로컬에서만 실행할 수 있습니다. 만약 귀하가 그러한 고사양 기기를 가지고 있지 않다면 클라우드 자원을 사용하거나 chatGPT와 같은 호스팅된 LLM의 API를 사용해야 할 것입니다.
Retrieval Augmented Generation (RAG) 개요
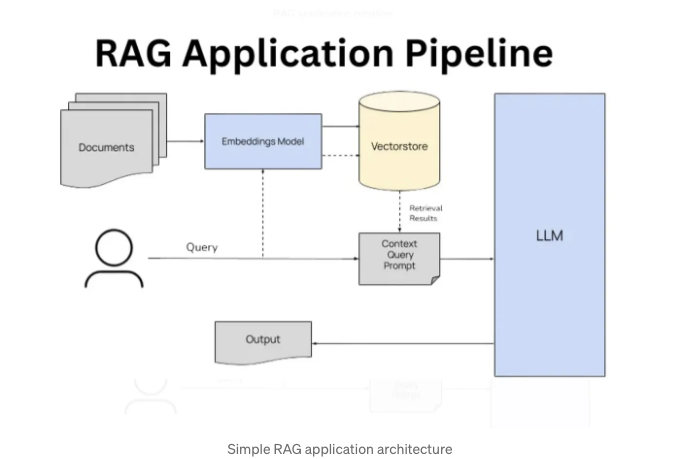
전형적인 LLM 상호작용에서 사용자는 직접 LLM에 프롬프트를 보내고 LLM의 훈련 세트에 기반한 응답을 받게 됩니다. 일반적인 작업에는 유용하지만 전문적인 지식이나 맥락이 필요한 경우 응답은 대개 만족스럽지 않을 수 있습니다.
RAG의 아이디어는 프롬프트가 전문 지식 데이터베이스를 방문하여 몇 가지 관련 문서를 가져와 LLM에 전달하는 것입니다. 프롬프트는 LLM이 동반된 문서를 기반으로만 답변하도록 제한된 프롬프트로 구성될 수 있으며, 이를 통해 보다 맥락에 맞는 응답의 품질을 보장할 수 있습니다.
위 다이어그램에 나타난 아키텍처는 두 가지 구성 요소로 간주할 수 있습니다:
- 정보 검색 구성 요소는 문서 저장소에서 프롬프트와 가장 유사한 문서를 찾아 추출합니다. 이는 벡터 데이터베이스를 사용하여 문서 유사성을 판별하는 방식으로 이루어집니다.
- LLM 구성 요소는 원래 프롬프트와 일치하는 문서를 사용하여 새로운 프롬프트를 작성하고 이를 우리 LLM에 보내 응답을 유도합니다.
이 튜토리얼에서는 Python을 사용하여 이 구조의 최소 예제를 만들 것입니다. 전체 Jupyter 노트북은 여기에서 찾을 수 있어요.
문서를 가져오고 준비하기
문서 저장소에는 교과서 내용이 포함될 것이며, 해당 교과서는 이 Github 저장소에서 오픈 소스 형태로 제공됩니다. 이 책은 14장과 텍스트, 코드 및 수학 공식이 포함된 섹션으로 구성되어 있으며, 각각이 마크다운 문서에서 생성됩니다.
먼저 필요한 몇 가지 패키지를 설치할 것입니다.
import torch
from langchain_community.document_loaders import DataFrameLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from transformers import AutoTokenizer, AutoModelForCausalLM
from dotenv import load_dotenv
from huggingface_hub import login
import os
import pandas as pd
이제 교과서의 모든 14 장의 텍스트를 가져와서 Pandas 데이터프레임에 저장할 겁니다:
import requests
# 장(chapter)은 다음과 같은 이름을 가진 Rmd 파일들입니다.
chapter_list = [
"01-intro",
"02-basic_r",
"03-primer_stats",
"04-linear_regression",
"05-binomial_logistic_regression",
"06-multinomial_regression",
"07-ordinal_regression",
"08-hierarchical_data",
"09-survival_analysis",
"10-tidy_modeling",
"11-power_tests",
"12-further",
"13-solutions",
"14-bibliography"
]
# 각 장의 텍스트를 가져오는 함수 생성
def get_text(chapter: str) -> str:
# Rmd 파일이 저장된 Github의 URL
github_url = f"https://raw.githubusercontent.com/keithmcnulty/peopleanalytics-regression-book/master/r/{chapter}.Rmd"
result = requests.get(github_url)
return result.text
# 각 장의 URL을 순회하며 텍스트 내용을 가져오기
book_text = []
for chapter in chapter_list:
chapter_text = get_text(chapter)
book_text.append(chapter_text)
# 데이터프레임에 작성
book_data = dict(chapter = list(range(14)), text = book_text)
book_data = pd.DataFrame.from_dict(book_data)
현재, 저는 길이가 상당히 긴 14개의 문서를 가지게 되었습니다. 앞으로 생각해보면, LLM에 보낼 모든 문서는 그 문맥 창에 맞게 맞춰져야 합니다. 현재 문서의 길이에서는 이를 제어할 수 없으므로, 이러한 문서를 더 많은 짧은 문서로 분할해야 할 필요가 있습니다.
그러나 무작위로 나눌 수는 없어요. 의미론적으로 분할해야 해요. 이렇게 하면 개별 문서가 어디서든 갑자기 잘려서 의미가 낯설지 않고 문서 전체가 의미론적으로 완성될 거예요. langchain Python 패키지의 멋진 기능을 사용할 거에요. 내 문서들을 1000단어로 제한하고 그 사이에 최대 150단어의 중복이 허용되도록 할 거예요.
# 문단을 의미론적으로 1000의 최대 길이로 분할
loader = DataFrameLoader(book_data, page_content_column="text")
data = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=150)
docs = text_splitter.split_documents(data)
# 몇 개의 문서가 나왔나요?
len(docs)
## 578
내 14개의 원본 문서가 578개의 작은 문서로 분할되었어요. langchain의 문서 형식이 어떻게 생겼는지 확인하기 위해 첫 번째 문서를 살펴보죠:
# 예상대로 문서가 보이는지 확인하기 위해 문서를 살펴봅시다
docs[0]
## Document(page_content="`r if (knitr::is_latex_output()) '\\\\mainmatter'`\n\n# The Importance of Regression in People Analytics {#inf-model}\n\nIn the 19th century,
## when Francis Galton first used the term 'regression' to describe a statistical phenomenon (see Chapter \\@ref(linear-reg-ols)), little did he know how important that
## term would be today. Many of the most powerful tools of statistical inference that we now have at our disposal can be traced back to the types of early analysis that
## Galton and his contemporaries were engaged in. The sheer number of different regression-related methodologies and variants that are available to researchers and practitioners
## today is mind-boggling, and there are still rich veins of ongoing research that are focused on defining and refining new forms of regression to tackle new problems.",
## metadata={'chapter': 0})
문서 개체에 페이지 내용 키와 관심 대상 텍스트가 포함되어 있음을 알 수 있습니다. 또한 메타데이터 키도 포함되어 있지만 우리에게는 관심이 없습니다.
나의 문서를 포함하는 벡터 데이터베이스 설정하기
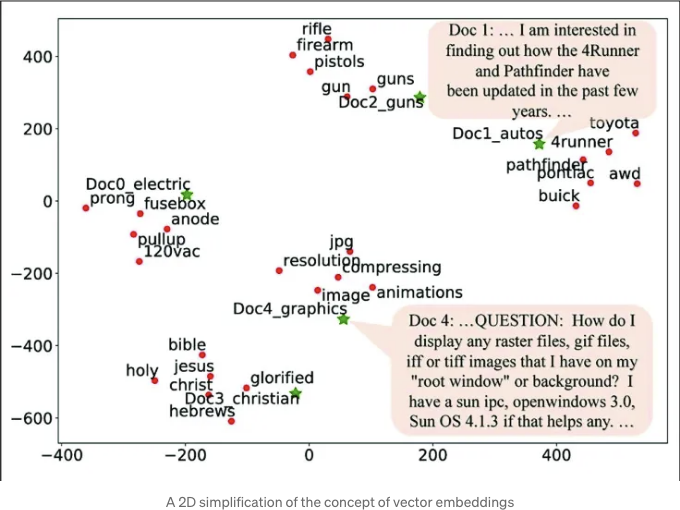
적절한 길이의 문서를 보유하게 되었으므로, 이제 해당 문서를 벡터 데이터베이스에 로드해야 합니다. 벡터 데이터베이스는 텍스트를 원본 형식으로 저장하는데 더불어 임베딩으로도 저장합니다. 임베딩은 대규모의 부동 소수점 수 배열로, 대형 언어 모델이 언어를 처리하는 데 기본적인 역할을 합니다. 다차원 공간에서 '근접한' 임베딩을 가진 단어, 문장 또는 문서는 콘텐츠 면에서 서로 밀접한 관련성을 가질 것입니다. 임베딩 개념의 2D 그래픽 단순화된 다이어그램은 위의 도표를 참조하십시오.
제가 프롬프트를 제출하면, 벡터 데이터베이스는 프롬프트의 임베딩을 사용하여 포함된 문서들 중에서 가장 가까운 임베딩을 찾게 될 거예요. '가장 가까운'을 정의하는 방법에는 여러 가지 옵션이 있어요. 이 경우에는 코사인 유사도를 사용할 거에요. 코사인 유사도는 두 벡터 사이의 각도의 코사인을 사용하여 거리를 결정해요. 코사인 유사도가 높을수록 두 문서가 관련성이 높다고 볼 수 있어요.
이 작업을 쉽게 하기 위해 저는 chromadb Python 패키지를 사용할 거에요. 이 패키지를 사용하면 로컬 컴퓨터에 벡터 데이터베이스를 설정할 수 있어요. 먼저 데이터베이스를 설정하고 임베딩을 생성할 때 사용할 언어 모델과 거리 측정 방법을 정의해야 해요. 이를 위해 표준이고 효율적인 언어 모델을 선택할 거에요.
import chromadb
from chromadb.utils import embedding_functions
from chromadb.utils.batch_utils import create_batches
import uuid
# ChromaDB 설정
CHROMA_DATA_PATH = "./chroma_data_regression_book/"
EMBED_MODEL = "all-MiniLM-L6-v2"
COLLECTION_NAME = "regression_book_docs"
client = chromadb.PersistentClient(path=CHROMA_DATA_PATH)
# 코사인 유사도를 거리 측정 방법으로 사용하여 DB 활성화
embedding_func = embedding_functions.SentenceTransformerEmbeddingFunction(
model_name=EMBED_MODEL
)
collection = client.create_collection(
name=COLLECTION_NAME,
embedding_function=embedding_func,
metadata={"hnsw:space": "cosine"},
)
이제 문서를 로드할 준비가 되었어요. 벡터 데이터베이스는 한 번에 로드할 수 있는 문서의 제한이 있어요. 제 경우에는 몇 백 개의 문서밖에 없어서 괜찮을 것 같지만, 그래도 안전하게 하기 위해 일괄 로드를 설정하겠어요.
# DB에 텍스트 뭉치를 일괄적으로 작성합니다
batches = create_batches(
api=client,
ids=[f"{uuid.uuid4()}" for i in range(len(docs))],
documents=[doc.page_content for doc in docs],
metadatas=[{'source': './handbook_of_regression_modeling', 'row': k} for k in range(len(docs))]
)
for batch in batches:
print(f"크기가 {len(batch[0])}인 일괄 처리를 추가합니다")
collection.add(ids=batch[0],
documents=batch[3],
metadatas=batch[2])
## 크기가 578인 일괄 처리를 추가 중
한 번에 한 개의 일괄 처리만이 필요했지만, 더 많은 문서 세트로 시도할 경우 위의 코드를 사용하여 여러 개의 일괄 처리를 로드할 수 있습니다.
이제 문서 저장소가 설정되었습니다. 이제 테스트할 차례입니다. 쿼리에 유사한 문서를 반환하는지 확인해보겠습니다. 통계적 질문을 하고 세 개의 가장 가까운 매칭 문서를 요청하겠습니다.
results = collection.query(
query_texts=["어떤 방법을 추천하시겠습니까?"],
n_results=3,
include=['documents']
)
results
# {'ids': [['371eeda2-c01f-420b-80c6-2b61894d0069',
# '94fc3891-4b37-49b9-a797-e73a11eec739',
# '3360431f-6857-47ac-a329-af10b6528c61']],
# 'distances': None,
# 'metadatas': None,
# 'embeddings': None,
# 'documents': [['# Proportional Odds Logistic Regression for Ordered Category Outcomes {#ord-reg}',
# "# Multinomial Logistic Regression for Nominal Category Outcomes\n\n`r if (knitr::is_latex_output()) '\\\\index{multinomial logistic regression|(}'`\n이전 장에서 우리는 로지스틱 함수를 사용하여 이항 또는 이분적 결과를 모델링하는 방법을 살펴보았습니다. 이 장에서는 결과가 어떤 순서도 없는 여러 범주를 가질 때 이를 어떻게 확장하는지 살펴보겠습니다. 결과가 이 명목적 범주형 형태를 갖추면 방향감이 없습니다. '더 좋은' 또는 '더 나쁜'과 같은 개념도 없고 '더 높은' 또는 '더 낮은'과 같은 개념도 없습니다. 다만 '다른' 것 뿐입니다.\n\n## 언제 사용해야 하나요?\n\n### 다항 로지스틱 회귀에 대한 직관\n\n이전 장에서 공부한 이항 또는 이분적 결과는 사실 두 가지 범주를 갖추는 명목적 결과입니다. 원칙적으로 우리는 이미 이 문제를 공부할 기본 기술을 갖추고 있습니다. 하지만 우리가 만들고자 하는 종류의 추론에 따라 문제에 접근하는 방식이 다를 수 있습니다.",
# '사실, 서열 결과의 추론적 모델링에 대해 다양한 알려진 방법이 있으며, 이 모두는 이전 장에서 다룬 선형, 이항 및 다항 로지스틱 회귀 이론을 기반으로 합니다. 이 장에서는 가장 흔히 채택되는 방법에 초점을 맞출 것입니다: *비례오즈*(proportional odds) 로지스틱 회귀. 비례오즈 모델(가끔은 제한된 누적 로지스틱 모델이라고도 함)은 해석하기 쉬운 장점이 있지만 근본적인 가정을 중요한 확인 없이 사용할 수 없습니다. \n\n## 언제 사용해야 하나요?\n\n### 비례오즈 로지스틱 회귀에 대한 직관 {#ord-intuit}']],
# 'uris': None,
# 'data': None}
<!-- TIL 수평 -->
<ins class="adsbygoogle"
style="display:block"
data-ad-client="ca-pub-4877378276818686"
data-ad-slot="1549334788"
data-ad-format="auto"
data-full-width-responsive="true"></ins>
<script>
(adsbygoogle = window.adsbygoogle || []).push({});
</script>
저는 꽤 잘 되어 있는 것 같아요! 이제 정보 검색 레이어를 완료했네요. 이제 LLM 레이어로 넘어가는 시간이에요.
## 내 컴퓨터에 구글의 Gemma-7b-it LLM 설정하기
Gemma-7b-it은 구글의 Gemini를 위한 70억 개 파라미터 지침 조정 버전의 기초 모델입니다. 이 모델은 약 20GB 크기로 Huggingface에서 사용할 수 있어요. 모델을 다운로드하고 사용하기 위해서는 약관에 동의하고 액세스 키를 받아야 해요. 이 크기의 모델을 사용하려면 상당히 강력한 CPU, GPU 및 RAM이 필요할 거예요.
먼저 모델에 접근하여 다운로드할 거에요. 처음으로 이를 수행할 때는 시간이 좀 걸릴 수 있지만, 한 번 다운로드되어 캐시에 저장되면 빨리 로드될 거예요.
<!-- TIL 수평 -->
<ins class="adsbygoogle"
style="display:block"
data-ad-client="ca-pub-4877378276818686"
data-ad-slot="1549334788"
data-ad-format="auto"
data-full-width-responsive="true"></ins>
<script>
(adsbygoogle = window.adsbygoogle || []).push({});
</script>
# 내 토큰을 사용하여 Huggingface에 로그인합니다.
load_dotenv()
login(token=os.getenv("HF_TOKEN"))
# Gemma-7b-it 다운로드하기
model = AutoModelForCausalLM.from_pretrained("google/gemma-7b-it")
tokenizer = AutoTokenizer.from_pretrained("google/gemma-7b-it", padding=True, truncation=True, max_length=512)
이제 테스트해 봅시다. 이 모델은 대화 형식으로 모델과 사용자 간의 대화 형식으로 프롬프트를 받는 것을 좋아합니다. 다음은 권장하는 프롬프트 형식입니다:
prompt = """
<start_of_turn>user
뉴멕시코에서 무슨 음식을 먹어봐야 할까요?<end_of_turn>
<start_of_turn>model
"""
이제 이 프롬프트를 Gemma가 이해할 수 있는 임베딩으로 변환하고, Gemma에게 응답 생성을 요청하고, 해당 응답을 텍스트로 디코딩하고, Gemma가 제공한 새로운 부분을 잘라냅니다.
<!-- TIL 수평 -->
<ins class="adsbygoogle"
style="display:block"
data-ad-client="ca-pub-4877378276818686"
data-ad-slot="1549334788"
data-ad-format="auto"
data-full-width-responsive="true"></ins>
<script>
(adsbygoogle = window.adsbygoogle || []).push({});
</script>
# 프롬프트를 임베드합니다
input_ids = tokenizer(prompt, return_tensors="pt")
# 답변을 생성합니다
outputs = model.generate(**input_ids, max_new_tokens=512)
# 답변을 디코드합니다
tokenizer.decode(outputs[0], skip_special_tokens=True).split('model\n', 1)[1]
# "뉴멕시코는 독특한 Native American, 스페인, 멕시코 영향을 혼합한 독특한 요리로 유명합니다. 여기 랜드 오브 엔찬트먼트에서 꼭 먹어봐야 할 음식 목록이 있습니다:\n\n**전통적인 Native American 음식:**\n\n* **인디언 타코:** 고기(흔히 양 또는 소), 콩, 치즈, 상추, 토마토 및 빨간 고추 가루가 들어간 옥수수 토르티야.\n* **칠레스 엔 노갓:** 빨간색과 녹색 칠레, 감자, 채소가 들어간 맛있는 소스로 쌓인 요리.\n* **소파이피야스:** 종종 꿀이나 잼과 함께 제공되는 바삭한 튀긴 도우 구이.\n* **포솔레:** 콘 토르티야와 빨간 고추 가루로 제공되는 풍미 있는 수육이 들어간 요리.\n\n**스페인과 멕시코 영향:**\n\n* **해치 칠레:** 해치, 뉴멕시코에서 재배된 녹색과 빨간색 칠레는 독특한 맛과 맵기로 유명합니다.\n* **빨간색과 녹색 칠레 스튜:** 빨간색과 녹색 칠레, 채소, 고기를 넣고 끓여 만든 푸짐한 스튜.\n* **까르네 아도바다:** 빨간 고추 가루로 절여진 천천히 굽는 소고기.\n* **비스코치토스:** 시나몬과 설탕이 묻힌 바삭한 튀긴 과자.\n* **소파피야스:** 과일, 꿀 또는 치즈가 들어간 튀긴 도우로 만든 달콤한 또는 짠 간식.\n\n**다른 꼭 먹어봐야 할 음식:**\n\n* **녹색 칠레 치즈버거:** 빨간 대신 녹색 칠레가 들어간 클래식 치즈버거 개량 버전.\n* **블루 콘:** 짙은 파란색의 독특한 옥수수 종류로, 주로 토르티야와 다른 요리에 사용됩니다.\n* **터콰즈 아이스크림:** 터콰즈색 아이스크림 파우더로 만든 상쾌한 아이스크림.\n\n**추가 팁:**\n\n* **매운맛에 대해 고려하세요:** 뉴멕시코 요리는 매운 정도로 유명합니다. 맵지 않은 음식에 익숙하지 않다면 온순한 버전을 요청하세요.\n* **현지 레스토랑을 시식하세요:** 뉴멕시코에는 전통 요리를 제공하는 많은 훌륭한 현지 레스토랑이 있습니다.\n* **음식 축제를 방문하세요:** 뉴멕시코에는 연중 음식 축제가 많이 열립니다.\n* **현지 맥주를 꼭 맛보세요:** 뉴멕시코에는 번창하는 크래프트 맥주 씬이 있습니다."
<!-- TIL 수평 -->
<ins class="adsbygoogle"
style="display:block"
data-ad-client="ca-pub-4877378276818686"
data-ad-slot="1549334788"
data-ad-format="auto"
data-full-width-responsive="true"></ins>
<script>
(adsbygoogle = window.adsbygoogle || []).push({});
</script>
def ask_question(question: str, model: AutoModelForCausalLM = model, tokenizer: AutoTokenizer = tokenizer, collection: str = COLLECTION_NAME, n_docs: int = 3) -> str:
# Find close documents in chromadb
collection = client.get_collection(collection)
results = collection.query(
query_texts=[question],
n_results=n_docs
)
# Collect the results in a context
context = "\n".join([r for r in results['documents'][0]])
prompt = f"""
<start_of_turn>user
통계학과 사람들 분석에 적용된 분야에 대한 전문가입니다.
여기 질문이 있습니다: {question}\n\n 다음 정보를 참조하여만 답해주세요: {context}.<end_of_turn>
<start_of_turn>model
"""
# Generate the answer using the LLM
input_ids = tokenizer(prompt, return_tensors="pt")
# Return the generated answer
outputs = model.generate(**input_ids, max_new_tokens=512)
return tokenizer.decode(outputs[0], skip_special_tokens=True).split('model\n', 1)[1]
## 나를 AI 버전으로 테스트하기
이제 교재에 써 놓은 지식을 기반으로 응답하는지 확인하기 위해 몇 가지 질문을 해보겠습니다.
ask_question("순서대로 범주형 결과를 모델링하는 데 어떤 방법을 추천하시겠습니까? 그리고 그 이유는 무엇인가요?")
<!-- TIL 수평 -->
<ins class="adsbygoogle"
style="display:block"
data-ad-client="ca-pub-4877378276818686"
data-ad-slot="1549334788"
data-ad-format="auto"
data-full-width-responsive="true"></ins>
<script>
(adsbygoogle = window.adsbygoogle || []).push({});
</script>
이렇게 답하는 것 같아요. 또 다른 것을 해보죠:
ask_question('Proportional Odds 회귀분석을 사용할 때 주의해야 할 점은 무엇인가요?')
## Proportional Odds 회귀분석을 사용할 때 주의해야 할 점은 다음과 같습니다:\n\n
## * **Proportional Odds 가정 검정:** 모델을 실행하기 전에 데이터에 적합한지 확인하기 위해 Proportional Odds 가정을 테스트해야 합니다. 가정이 실패하면 순서형 결과에 대한 대안 모델을 고려해야 합니다.\n
## * **변수 제거:** 가정이 실패하면 결과에 영향을 미치지 않는 변수를 제거할 수 있습니다. 그러나 이를 하는 것이 적합한지 여부는 전반적인 모델 적합도에 대한 영향에 매우 의존합니다.\n
## * **대안 모델:** 변수 제거에 대해 편안하지 않다면, 순서형 결과에 대한 대안 모델을 고려해야 합니다. 가장 일반적인 대안 모델로는 누적 로짓 모델, 순위 기반 모델, 기준 기반 모델 등이 있습니다.'
다시, 제가 한 말 같네요. 그러면 교재에 다루지 않는 주제에 대해 물어본다면 어떨까요?
ask_question('물리학의 표준 모델은 무엇인가요?')
## 교재에는 물리학의 표준 모델에 대한 정보가 제공되지 않았기 때문에 이 질문에 대답할 수 없습니다.'
<!-- TIL 수평 -->
<ins class="adsbygoogle"
style="display:block"
data-ad-client="ca-pub-4877378276818686"
data-ad-slot="1549334788"
data-ad-format="auto"
data-full-width-responsive="true"></ins>
<script>
(adsbygoogle = window.adsbygoogle || []).push({});
</script>
좋아요! 그것이 내가 할 것처럼 그 자리에 머물러 있네요.
## 그래서 우리가 배운 것은 무엇인가요?
AI Keith를 만드는 것이 재미있었을 뿐만 아니라, 이것은 LLM의 능력을 활용하되 맥락 정보로 보완하고 망상하는 경향을 통제할 수 있는 간단한 아키텍처를 보여줍니다. 이는 지식 검색에 상당한 응용 가능성이 있으며, 큰 지식 저장소의 검색을 요약하는 길을 제공하는 이 아키텍처는 가치가 있습니다.
AI Keith에 대해서는, 곧 오픈할 계획이 없습니다. 우선 이 예제는 너무 소규모이고, 이러한 아키텍처를 프로덕션에 호스팅하고 항상 사용 가능하게 유지하려는 시도는 비용이 너무 많이 들어 사용 이유를 정당화하기 힘들 것입니다. 하지만 더 큰 규모의 상황에서의 가능성을 보시게 되기를 희망합니다.
<!-- TIL 수평 -->
<ins class="adsbygoogle"
style="display:block"
data-ad-client="ca-pub-4877378276818686"
data-ad-slot="1549334788"
data-ad-format="auto"
data-full-width-responsive="true"></ins>
<script>
(adsbygoogle = window.adsbygoogle || []).push({});
</script>
AI Keith에 대해 어떻게 생각하시나요? RAG 아키텍처를 다뤄보신 적이 있나요? 자유롭게 의견을 남겨주세요!