Langchain을 사용하지 않고 CSV 파일과 상호 작용하는 LLM 파이프라인
LangChain, LangGraph, LlamaIndex, CrewAI... 한 가지 도구에 익숙해지기 시작하면 또 다른 도구가 등장합니다. 이 도구들을 깎아내리거나 싫어하지는 않지만, 이 중 하나와 개발하는 것은 학습 곡선 때문에 진정으로 무섭고 당황스러울 수 있습니다. 이 도서관들을 배우는 것으로 끝내는 대신에 실제로 무언가를 구축하고 싶다면 낙담하기 쉬울 수 있습니다. LangChain은 훌륭하지만 정말 밀도있게 포장되어 있습니다. 문서 자체로는 Python용, JavaScript용 하나씩, 그리고 아마도 API를 위한 부모 문서가 있을 거라고 생각합니다. 그리고 Python 내에서도 비슷한 작업을 수행하는 여러 기능들이 있습니다. 이 모든 것은 좋지만, 코드에 충분한 제어권이 없습니다. 예를 들어, 이전 블로그에서 PDF를 바이트로 로더에 전달하려고 했지만, 함수는 파일 URL만 허용했기 때문에 제대로 수행할 수 없었습니다. 나에게 따르면, 무언가를 간단히 구축할 때 LangChain은 마지막 선택이어야 합니다. 항상 KISS (Keep it simple, stupid)를 지키세요.

음, 그들이 나가리키는 만큼 사악하지 않을 수도 있지만, 충분하지 않다고 판단된다면 먼저 원시적인 것을 시도한 다음에 더 고급 도구로 넘어가는 것이 항상 좋습니다.
이번 달은 상당히 바쁘게 보냈어요 (사실, 2022년 11월 이후 모든 달이 그랬어요) GPT-4o의 발매와 Gemini 업데이트가 두 날에 걸쳐 연이어 발표되면서요.

GPT-4o의 'ScarJo' - 아니, 'Sky' - 음성은 데모에서 영향을 주었는데, 이로 인해 인공지능 산업에 파도를 일으키고 구글 I/O의 Gemini 성능을 가려버렸어요. 솔직히 말해서, GPT는 항상 모든 LLM들보다 한 발 앞서 있을 거예요만 MVP 및 개인 프로젝트를 만들 때, 무료 티어를 제공하는 Gemini는 제 같은 가난한 개발자들에게 축복이예요. 최신 모델에 액세스할 수 있는 무료 티어로 API 제한 속도가 15 rpm로 정해져 있어요. 나쁘지 않죠?
ChatGPT의 무료 버전을 통해 이제 GPT-4o로 파일을 업로드할 수 있지만, 여전히 코드 해석기 없이 CSV나 엑셀 데이터를 해석할 수 없어요. 그래서 Gemini Flash의 능력을 테스트해보기 위해 제가 직접 CSV 해석기를 만들기로 결심했어요. Langchain을 사용하는 방법을 보여주는 많은 튜토리얼이 있지만, 저희는 처음 시작하는 사람들에게 특히 더 이해하기 쉬운 방법으로 처음부터 만들어볼 거예요.
파이프라인
내 말 믿어봐, 처음에는 약간 어려워 보일 수 있지만 정말 간단해. 기본 아이디어는 LLM에게 코드를 생성하도록 요청하는 것이야. 코드를 생성하려면 작업 중인 데이터셋에 대한 일부 컨텍스트를 제공해야 해.
1단계는 코드 생성을 다루는데, 데이터셋의 메타데이터를 제공하고, 내 경험에 따르면 head(), describe(), columns(), dtypes이 충분한 컨텍스트를 제공할 거야. LLM에 대한 경험이 있는 경우, RAG (Retrieval Augmented Generation)을 사용할 수 있는지 궁금할 수도 있어. RAG는 벡터 데이터베이스와 시맨틱 검색을 활용해 데이터 검색 후 그 결과를 쿼리와 함께 LLM에 삽입하는 것이야. 이는 텍스트 데이터와 잘 작동하지만 구조화된 또는 비구조화된 데이터의 분석에는 적합하지 않아. 왜냐하면 전체 데이터셋이 조각으로 나뉘어 컨텍스트를 제한하고 기능을 제한하기 때문이지. 예를 들어, 데이터셋에서 총 행의 수를 조회하고 싶다면 RAG로는 간단히 불가능해.
2단계에서는 1단계에서 생성된 코드를 실행하여 생성된 출력을 LLM에 제공하고 사용자 쿼리와 결합시킨다. 이를 통해 pandas 명령의 출력을 자연어로 변환하여 대화 경험을 향상시킬 수 있어.
표 태그를 Markdown 형식으로 변경해주세요.
대부분의 사람들이 하는 신입 실수 중 하나는 프롬프트에 가능한 모든 지시사항을 자세히 기술하는 것입니다. LLMs는 지능이 없으므로 모든 것을 지키지 않을 것이며(적어도 AGI가 달성될 때까지), 이 문제를 피하기 위해 다수의 기술과 전략이 개발되었습니다. 예를 들면 제로샷 프롬프팅, 사고 흐름, 퓨샷 프롬프팅 등이 있습니다. 이들이 멋지게 들리기는 하지만 실제로는 매우 기본적인 기술들입니다. 이미 이들에 대한 많은 문헌 자료가 있기 때문에 그것들에 대해서는 자세히 다루지 않겠습니다. 이 중에서 나에게 가장 효과적으로 작용한 것은 역할 기반 프롬프팅입니다. 역할 기반 프롬프팅에서는 쿼리하기 전에 LLM에게 역할을 할당합니다. 이는 원하는 결과를 달성하는 데 도움이 됩니다.
총 네 개의 프롬프트가 필요합니다: 두 개의 시스템 프롬프트와 두 개의 주요 프롬프트(각 단계별 시스템 프롬프트 + 주요 프롬프트). 시스템 프롬프트는 틀을 제공하여 인공지능이 특정 매개변수 내에서 작동하고 일관되고 관련성 있으며 원하는 결과와 일치하는 응답을 생성할 수 있도록하는 역할을 합니다.
단계 1
시스템 프롬프트
Main Prompt
The dataframe name is ‘df’. df has the columns 'cols' and their datatypes are 'dtype'. df is in the following format: 'desc'. The head of df is: 'head'. You cannot use df.info() or any command that cannot be printed. Write a pandas command for this query on the dataframe df: 'user_query'
If you provide me with the specific metadata values, I can help you generate the pandas command for the user query on the dataframe 'df'. Feel free to ask any questions!
응답 스키마
class Command(typing_extensions.TypedDict):
command: str
젬니 SDK에서 JSON 모드로 전환할 수 있습니다. 일관된 JSON 출력을 얻으려면 응답 스키마를 Python 클래스로 정의하고 LLM 응답 생성 함수의 매개변수로 전달하세요. Command 클래스에서 JSON은 하나의 key인 command와 문자열 값만을 가질 것입니다.
// 사용자 쿼리: "상위 5개 데이터를 보여줘"
{
"command": "df.head()"
}
단계 2
시스템 프롬프트
당신의 임무는 이해하는 것입니다. 사용자 쿼리와 응답 데이터를 분석하여 자연어로 된 응답 데이터를 생성해야 합니다.
주 프롬프트
사용자 쿼리는 'final_query'입니다. 명령의 출력은 'str(data)'입니다. 데이터가 'None'인 경우 '시작하려면 쿼리를 요청하세요'라고 말할 수 있습니다. 사용된 명령을 언급하지 마세요. 출력에 대한 자연스러운 언어의 응답을 생성하세요.
모두 함께 넣기
편리함을 위해 이 프로젝트에는 Streamlit을 사용할 것입니다. 이는 많은 시간을 절약해줄 것입니다. 이 프로젝트는 80%의 GenAI 응용 프로그램 내부를 이해하는 데 목표를 두고 있습니다. Python을 사용하여 사용자 정의 웹 애플리케이션을 구축하는 방법을 배우고 싶다면 제 블로그를 여기에서 읽어보세요.
데이터프레임 메타데이터
df = pd.read_csv(uploaded_file) head = str(df.head().to_dict()) desc = str(df.describe().to_dict()) cols = str(df.columns.to_list()) dtype = str(df.dtypes.to_dict())
시스템 프롬프트
Stage 1
model_pandas = genai.GenerativeModel('gemini-1.5-flash-latest', system_instruction="판다스와 함께 작업하는 전문 파이썬 개발자입니다. JSON 형식으로 사용자 쿼리를 위한 간단한 판다스 '명령'을 생성하는 것을 확인합니다. 'print' 함수를 추가할 필요는 없습니다. 명령을 생성하기 전에 열의 데이터 유형을 분석하세요. 불가능한 경우 'None'을 반환하십시오. ")
Stage 2
model_response = genai.GenerativeModel('gemini-1.5-flash-latest', system_instruction="태스크는 이해하는 것입니다. 사용자 쿼리를 분석하고 응답 데이터를 자연어로 생성하는 데 있어서 의무가 있습니다.")
메인 프롬프트
# Stage 1
final_query = f"데이터프레임 이름은 'df'입니다. df는 열 {cols}을 가지고 있으며 데이터 유형은 {dtype}입니다. df는 다음 형식으로 구성되어 있습니다: {desc}. df의 맨 위 데이터는 다음과 같습니다: {head}. df.info()나 출력할 수 없는 명령을 사용할 수 없습니다. 데이터프레임 df에 대한 이 쿼리에 대한 판다스 명령어를 작성해주세요: {user_query}"
# Stage 2
natural_response = f"사용자 쿼리는 {final_query}입니다. 명령어의 결과는 {str(data)}입니다. 데이터가 'None'인 경우 '시작하기 위해 쿼리를 요청하세요'라고 말할 수 있습니다. 사용된 명령을 언급하지 마세요. 결과에 대한 자연어 응답을 생성해주세요."
응답 생성
# Stage 1
response = model_pandas.generate_content(
final_query,
generation_config=genai.GenerationConfig(
response_mime_type="application/json",
response_schema=Command,
temperature=0.3
)
)
# Stage 2
bot_response = model_response.generate_content(
natural_response,
generation_config=genai.GenerationConfig(temperature=0.7)
)
temperature는 생성된 응답의 무작위성을 제어하는 데 사용됩니다. 높은 temperature는 더 창의적이고 다양한 응답을 생성하지만 실제 사용자 쿼리에서 벗어날 수 있습니다. 낮은 temperature는 더 일관된 몰입형 응답을 생성하지만 창의적이지 않을 수 있습니다. 그래서 제가 Stage 1에는 정확한 명령을 얻기 위해 낮은 temperature를 선택했고, Stage 2에는 답변이 지루하고 로봇적이지 않도록 더 높은 temperature를 선택했습니다. 달콤한 지점을 찾기 위해 실험해보세요.
팬더스 명령을 실행하려면 파이썬에서 exec() 함수를 사용할 것입니다. 이 함수를 통해 파이썬 코드를 동적으로 실행할 수 있습니다. exec() 함수와 관련된 보안 취약점을 알고 있지만, 이 경우에는 다른 방법이 없었습니다. exec() 함수를 더 안전하게 사용하기 위해 아키텍처를 개선하거나 더 많은 유효성 검사를 추가할 수 있습니다. 이 프로젝트는 개인 프로젝트이므로 그러한 조치를 취하지 않았습니다. 파이썬 코드를 안전하게 실행할 수 있는 라이브러리가 있는지 알고 계시다면 댓글 섹션에 알려주세요.
사용자 인터페이스
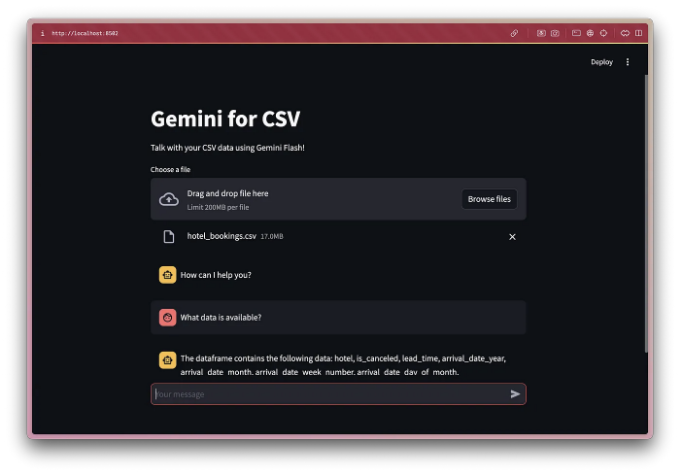
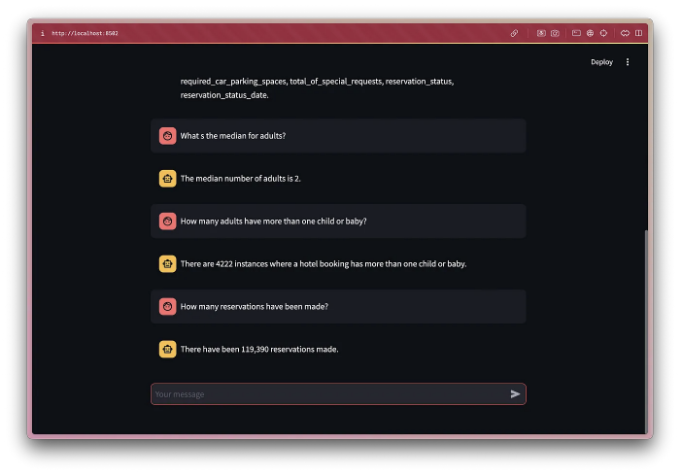
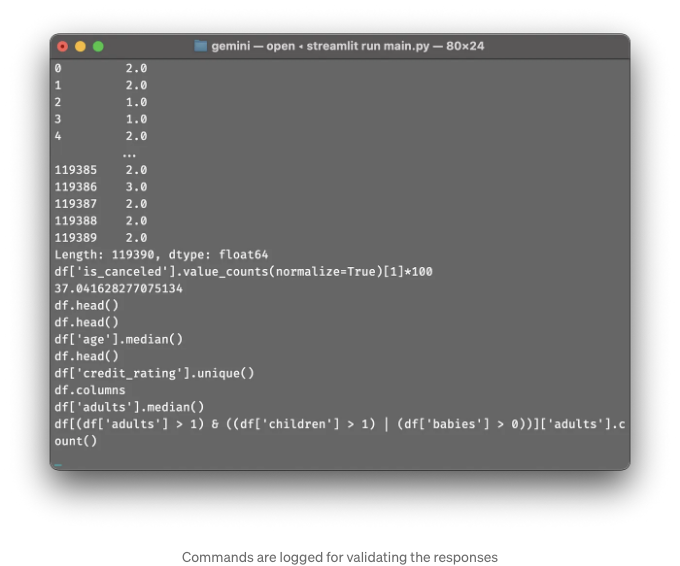
결론
항상처럼, 전체 과정을 가능한 한 쉽게 만들려고 노력했습니다. 여기까지 읽어주셨다면, 이것이 로켓 과학이 아님을 알 것입니다. 그냥 점을 이어주는 것이며, LLMs를 범용 API로 생각해야 합니다. 특정 방식으로 LLM을 트리거하면 어떤 작업이든 수행할 수 있는데, 이것은 다음 프로젝트를 위해 활용해야 할 핵심 요소입니다. 이 프로젝트는 혁신적이거나 새로운 것이 아닙니다 — ChatGPT의 코드 해석기는 유사한 아키텍처에서 작동합니다. 나는 이것이 매우 추상화되어 있어 처음 시작하는 사람들에게 흥미로울 것으로 보입니다. LLM에 메타데이터를 주입하여 코드를 생성하는 아이디어는 샤워 중에 떠올랐고, 꽤 잘 수행되었습니다.
Streamlit UI와 함께 전체 코드를 보려면 gist를 확인하세요. Streamlit에 대해 더 알고 싶다면 여기 블로그를 읽어보세요. 이 튜토리얼을 즐겁게 읽으셨다면, 기사에 박수를 👏 보내주시고 더 많은 콘텐츠를 위해 팔로우해주세요.