
몇 달 전에 리서치 프로젝트를 진행하면서 시계열을 다루는 문제를 해결해야 했어요.
이 문제는 상당히 간단했어요:
Machine Learning 애호가들에게는 "Hello World"를 작성하는 것과 같은 느낌이죠. 이 문제는 "forecasting"이라는 이름으로 커뮤니티에서 매우 잘 알려진 문제입니다.
기계 학습 커뮤니티는 시계열 데이터의 다음 값을 예측하는 데 사용할 수 있는 많은 기술을 개발했습니다. 일부 전통적인 방법에는 ARIMA/SARIMA 또는 푸리에 변환 분석과 같은 알고리즘이 포함되어 있으며, 더 복잡한 알고리즘에는 컨볼루션/순환 신경망 또는 슈퍼 유명한 "Transformer" (ChatGPT의 T는 transformers를 나타냅니다)이 있습니다.
예측 문제는 매우 잘 알려진 문제이지만, 제약 조건이 있는 예측 문제에 대해 다루는 것은 덜 흔한 것일 수 있습니다. 무엇을 의미하는지 설명해 드릴게요.
일련의 매개변수 X와 시간 단계 t가 있는 시계열 데이터가 있다고 가정해 봅시다. 표준 시간 예측 문제는 다음과 같습니다:
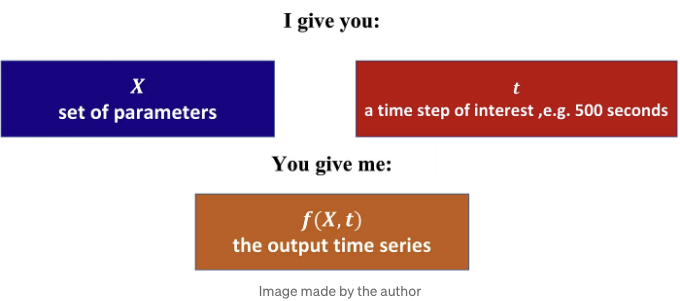
우리가 직면한 문제는 다음과 같습니다:
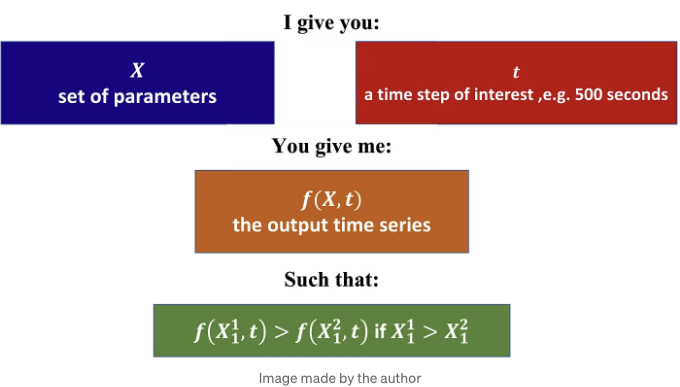
따라서 입력 매개변수가 d 차원이라고 가정할 때, 저는 차원 1을 위한 함수가 단조적이 되기를 원합니다. 그렇다면 어떻게 처리해야 할까요? 어떻게 "단조적" 시계열을 예측할 수 있을까요? 이 문제에 대한 설명은 XGBoost를 사용할 것입니다.
이 블로그 포스트의 구조는 다음과 같습니다:
- XGBoost에 대해: XGBoost가 무엇에 대해, 기본 아이디어가 무엇인지, 장단점은 무엇인지 몇 줄로 설명하겠습니다.
- XGBoost 예제: XGBoost 코드를 설명하겠습니다. Python 설명부터 장난감 예제까지를 포함하여요.
- XGBoost의 명확성을 갖춘 예제: XGBoost를 실제 예제로 테스트하겠습니다.
- 결론: 이 블로그 포스트에서 언급된 내용에 대한 요약을 제시하겠습니다.
1. XGBoost에 대해
1.1 XGBoost의 아이디어
XGBoost의 XG는 extreme gradient(부스팅)을 의미합니다. "gradient boosting" 알고리즘은 "예측자 체인"을 사용하려고 합니다. 입력 행렬 X 및 해당 출력 y가 주어지면, 아이디어는 여러 예측자가 있습니다. 첫 번째 예측자는 입력 X로부터 직접 해당 출력 y를 찾으려고 합니다. 이야기의 끝. 아니요, 농담이에요 🤣
첫 번째 예측기는 “약한 예측기”라고 불리는 것을 목표로 합니다. 이는 예측된 y1과 실제 출력 y 사이에 무시할 수 없는 차이가 있는 것을 의미합니다. 두 번째 예측기는 첫 번째 예측의 오류를 보정하는 것을 목표로 하므로 X에서 y로 이동하는 것이 아니라 y2 = y-y1로 이동하는 것으로 훈련됩니다. 이 작업은 예측기의 수인 N번 반복되며, 아래 이미지에 나타난 바와 같습니다:
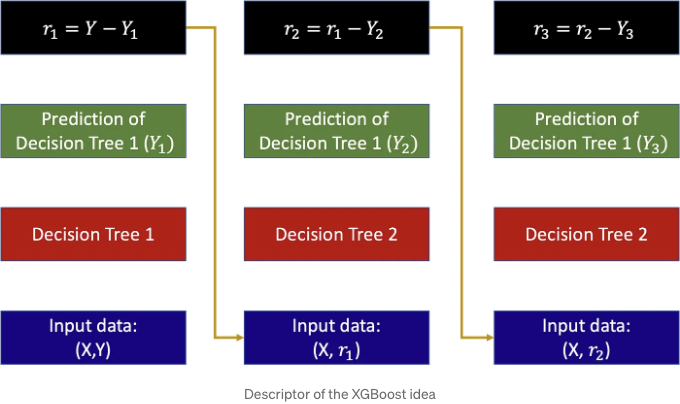
각 예측기는 의사 결정 트리(decision tree)입니다. 의사 결정 트리에 대한 설명을 할 때마다, 나는 그것을 게임 “guess who”에 비유하여 설명합니다. 그 게임은 다음과 같이 진행됩니다.
각 플레이어가 일부 캐릭터 얼굴로 가득 찬 게시판을 가진 “guess who”의 클래식 게임을 하는 상황을 상상해보세요. 각 캐릭터는 머리카락 색상, 눈동자 색상, 안경, 모자 등과 같은 구별 가능한 특징을 가지고 있습니다. 목표는 이러한 특징들에 대한 예/아니오 질문을 통해 상대방의 비밀 캐릭터를 추측하는 것입니다. 각 질문은 답변과 맞지 않는 후보를 없애줄 뿐 아니라, 가능성을 좁히며 마침내 확신을 갖고 비밀 캐릭터를 추측할 수 있도록 도와줍니다.
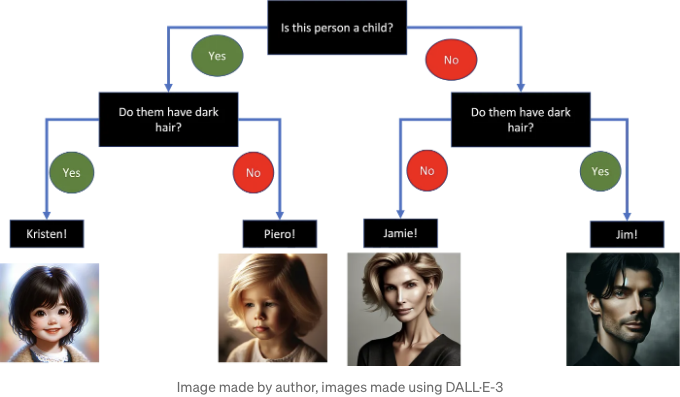
As you can see, the structure resembles an upside-down tree, starting from the leaves (bottom) and extending to the root (top).
Each predictor corresponds to one of these trees. If you are pondering the difference between classification and regression, you are correct. The example I showcased, for simplicity, focuses on a classification problem. However, if you substitute "Kristen" with a real number like "0.47462", you will shift to a regression problem. It's that straightforward.
The XGBoost algorithm cleverly utilizes all these decision trees to "boost" the prediction of the preceding tree. It's called "extreme" because a plethora of intermediate optimization steps have been undertaken by the talented scientists who developed the algorithm, which you can explore here.
학습 파트는 항상 손실 함수 최소화 + 오버피팅 방지를 위한 정규화 항이 포함됩니다. 파라미터로는 잎의 수, 트리의 깊이 및 트리의 분할 지점이 있습니다. "트리의 분할 지점"이란 무엇을 의미하냐면요. 위 예제에서 "이 사람이 아이인가요?"와 같은 질문이 있습니다. 실제로는 연속적인 특성을 갖게 되어 "x_1이 분할 지점인가요?"와 같이 더 많이 사용하게 될 수 있습니다. 이는 분할 지점이 하나의 파라미터로 작용하게 되는 것입니다.
1.1 XGBoost 단조성
이제, XGBoost 알고리즘은 제공할 것이 많습니다:
- 오버피팅에 대한 일반적으로 강한 내구성을 보여줍니다. 의사결정 트리는 오버피팅 문제가 잘 알려져 있으며 이러한 앙상블 방법은 이를 극복하는 데 좋습니다.
- 저렴한 계산 복잡성을 다룰 수 있습니다. 그것을 하면서 오버피팅을 방지하는 것이 특히 명확하지 않습니다.
- 특성의 중요성 덕분에 여전히 설명 가능성을 제공합니다. 이를 통해 어떤 X의 파라미터가 예측에 중요한지 이해할 수 있습니다.
- 특정 특성에 대해 단조 함수로 응답을 하도록 선택할 수 있습니다.
예를 들어, 다음과 같은 함수가 있다고 가정해 봅시다:
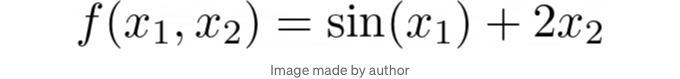
이 함수는 x2에 대해 단조적입니다. x1과 x2가 주어졌을 때 XGBoost를 사용하여 f(x1, x2)의 결과를 예측하려고 한다고 상상해 봅니다. 이제 현실에서 f(x1, x2)는 알려지지 않았습니다 (그렇지 않으면 기계 학습을 하지 않고 휴가를 가기위해 플로리다로 비행을 갈 것입니다), 하지만 x2에 대해 단조적이라는 점을 알거나 원할 수 있습니다. 실제로 저는 다른 양과 관련하여 단조적임을 알고 있던 물리량이 있었던 적이 있습니다. XGBoost의 구조를 수정하여 해당 특징에 대한 요구 사항을 충족시킬 수 있습니다. 우리의 경우, x2에 대한 단조적 행동을 강제하는 예측을 할 수 있습니다.
좋아요. 이제 이걸 버텨내셨으면 좋겠네요. 이제 재미있는 부분으로 넘어갑시다. 😅
2. 코딩
2.1 장난감 데이터셋
결정 트리가 나를 많이 성장시키고, 나의 첫 번째 머신러닝 코드 중 하나였으니까 많은 감정을 불러일으켰어요. 조금 바보 같게 들릴지 몰라도, 조금은 감정적이 느껴져요 ❤️
하지만 솔직히 이 코드는 굉장히 간단합니다. 그러니 더 이상 말이 필요 없이, 바로 시작해 봅시다. 두 가지 예제를 보여 드릴 건데, 첫 번째 예제는 1차원으로, 이 모든 것이 어떻게 작동하는지 설명하는 겁니다. 이것은 우리가 XGBoost를 사용해 예측하고자 하는 대상 함수 f입니다:
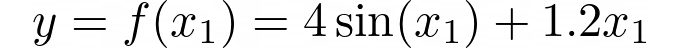
이것이 플롯입니다.
이제 XGBoost의 실용적인 구현이 문서에 단어별로 자세히 나와 있습니다. 제가 모든 부분을 알려드릴 필요는 없지만, 이 경우에 어떻게 작동하는지 보여드리고 싶습니다. 이는 온라인에서 찾을 수 있는 어떤 SkLearn 모델과 다를 바 없습니다.
쉽죠. 이제 실제 테스트를 해봅시다.
2.2 실제 데이터셋
위의 예제는 xgboost 코드의 구조를 보여줍니다. 그러나, 우리가 구축한 장난감 데이터셋에는 몇 가지 제한 사항이 있습니다:
- 너무 간단하다 (1 차원) 그리고 완전히 근거없이 만들어진 데이터셋이다.
- 우리는 데이터셋을 섞었기 때문에 예측적으로 사용하지 않았다.
- 우리는 모노토닉 제약 조건을 사용하지 않았다 (내가 약속한 것).
그래서, 실제 비즈니스를 시작해 볼까요? 저는 델리 데이터의 데이터셋인 이 데이터셋을 사용했습니다. 이 데이터셋은 두 개의 csv 테이블 (DailyDelhiClimateTrain.csv와 DailyDelhiClimateTest.csv)으로 구성되어 있습니다.
Pandas를 사용하여 데이터를 가져와서 5개의 행을 표시했습니다. 날짜, 습도, 풍속, 평균 기압 및 평균 온도와 같이 5개의 열이 있습니다. 하나의 합리적인 문제는 다음과 같을 수 있습니다:
그리고 이 문제에 대해 잘 다루는 블로그 포스트가 있습니다. 우리는 한 단계 더 나아가려고 합니다. 우리는 이 다른 열인 "City_Index"를 추가할 것입니다. 이 City_Index는 뉴델리보다 더 덥거나 더 추운 다른 도시가 있다는 사실을 모방할 것입니다. 세계의 다른 부분별로 도시 지수를 그룹화하는 것처럼*:
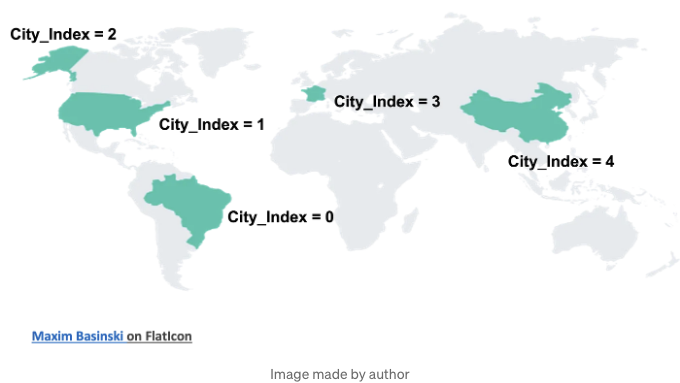
이제 City_Index=1이 mean_temp의 기본 값이 되도록 만들 것입니다. City_Index = 2는 목표 값으로 2mean_temp를 가져오도록 만들 것이고, City_Index=9는 목표 값으로 9mean_temp를 가져오도록 할 것입니다. 이는 다른 변수를 모두 고정시킨다면 City_Index가 단조 변수가 될 수 있다는 것을 의미합니다:
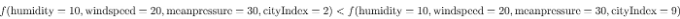
실제로 이것은 로스엔젤레스, 캘리포니아의 온도가 앵코리지, 알래스카의 온도보다 항상 높다는 것을 의미합니다 (알래스카에 있는 도시를 몰라서 구글링했어요).
우리는 "City_Index" 변수와 이 두 함수를 통해 이를 할 것입니다:
이제 우리는 이를 할 것입니다:
- 새로운 City_Index 변수를 사용하여 증강된 데이터 세트를 생성합니다.
- 데이터를 훈련 및 검증 세트로 분할합니다.
- City_Index에서 단조성을 강제하여 시계열 XGBoost 예측기를 훈련하는 데 훈련 데이터를 사용하고 훈련된 모델을 사용하여 다음 값을 예측합니다.
그리고 이렇게 테스트해 봅니다:
그리고 이것이 우리의 예측 결과입니다:
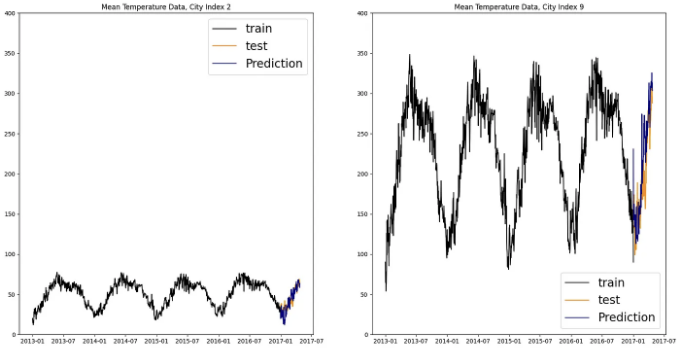
몬토닉성은 params_constraints에서 확인할 수 있습니다. Params constraints 벡터는 우리가 몬토닉성을 유지하고 싶은 특성을 제외한 모든 특성을 0으로 설정한 벡터입니다. 이제 알 수 있듯이, 다른 모든 특성을 고정하고 City_Index를 변경하면 몬토닉한 동작을 볼 수 있습니다:
완벽하게 몬토닉합니다. 거의 선형적이기도 하죠 (우리가 사전에 특정한 것). 이것은 XGBoost 대 ARIMA, SARIMA 또는 다항 회귀를 사용하는 차이를 보여줍니다: XGBoost를 사용하면 명시적인 몬토닉 동작을 부여할 수 있습니다.
3. 결론
여기에서 우리가 한 작업을 요약해 드릴게요:
-
저희는 예보 작업을 수행하되 보존하고 싶은 일부 단조 특성이 있는 문제를 소개했습니다. 이러한 경우에는 ARIMA나 RNN과 같은 고급 방법이 단조성을 깨뜨릴 수 있습니다.
-
간단히 말해, "추측 누구?" 예제를 사용하여 XGBoost 아이디어를 소개했고, 부스팅 알고리즘이 선택할 수 있는 의사 결정 트리를 수정하여 단조성을 강제할 수 있다는 점을 확인했습니다.
-
우리는 XGBoost를 장난감 예제에서 사용하여 구문이 작동하는 방식을 기본적으로 이해했습니다.
-
기후변화 데이터를 사용하여 예보 연구를 수행했으며, 기본적인 예보 이상의 작업을 수행했습니다. 'City_Index'라는 새로운 특성에 단조적으로 증가하는 값을 부과함으로써, City_Index 특성에 대해 예측된 온도가 단조적이어야 한다는 가정에 기반하여 온도를 예측했습니다.
4. 저에 대해!
다시 한 번 시간 내주셔서 감사합니다. 정말 감사드려요 ❤
내 이름은 Piero Paialunga이고 난 이 사람이야:

저는 시내티 대학교 항공우주공학부 박사 후보이자 Gen Nine의 머신러닝 엔지니어입니다. 블로그 글과 Linkedin에서 AI 및 머신러닝에 대해 이야기합니다. 만약 글이 마음에 드시고 머신러닝에 대해 더 알고 싶으시다면:
A. 제가 모든 이야기를 게시하는 Linkedin에서 팔로우하세요. B. 뉴스레터를 구독하세요. 새로운 이야기에 대한 업데이트를 제공하며 의문이나 궁금증이 있을 때 연락해 모든 수정을 받아볼 수 있습니다. C. 추천 회원이 되어 "월간 최대 이야기 수" 제한 없이 저 (그리고 수천 명의 다른 머신러닝 및 데이터 과학 최고 작가)가 제공하는 최신 기술에 대해 읽을 수 있습니다.
질문이 있거나 협업을 시작하려면 여기에 메시지를 남겨주세요: