개요
Extract, Transform, and Load (ETL)은 다양한 소스에서 데이터를 추출하고 적절한 형식으로 변환한 다음 추가적인 분석을 위해 목적지 데이터베이스나 데이터 웨어하우스에로드하는 작업을 의미합니다. 이 블로그 포스트에서는 Python을 사용하여 실무 ETL 프로젝트를 수행하는 과정에 대해 알아보겠습니다.

단계 1: 필요한 라이브러리 가져오기
아래는 Markdown 형식으로 변경한 내용입니다.

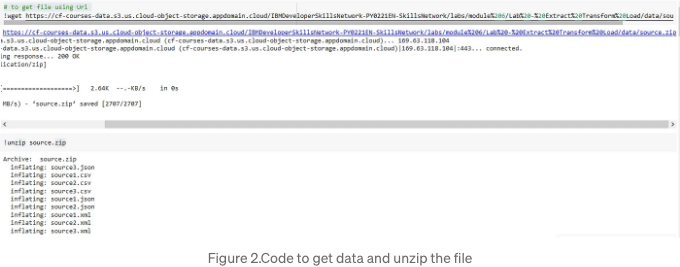
저희 ETL 파이프라인의 첫 번째 단계는 데이터가 포함된 파일에서 데이터를 추출하는 것입니다. 우리는 pandas 라이브러리를 사용하여 파일을 DataFrame으로 읽을 것입니다.


단계 4: 데이터 변환
다음 단계는 추출된 데이터를 대상 파일로로드하기 위한 원하는 형식으로 변환하는 것입니다. 이는 데이터 정리, 누락된 값 처리 및 데이터 유형 변환을 포함할 수 있습니다.
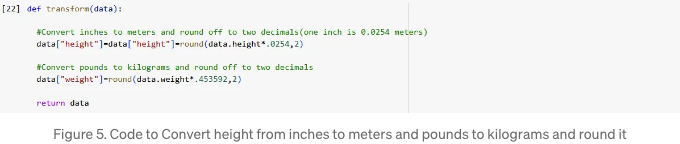
단계 4: 데이터 로드
마지막 단계는 변환된 데이터를 대상 파일로로드하는 것입니다.

결론:
이 프로젝트의 주요 목표는 간단한 ETL 파이프라인을 만들고 자동화하는 실용적인 가이드를 제공하는 것입니다. 이를 통해 이 프로젝트는 데이터 엔지니어링 스킬을 향상시키는 실용적인 방법을 제공하는 데 기대합니다.
하지만 여기서 모험이 끝나는 건 아닙니다. 데이터는 다양한 분석 목적으로 사용될 수 있으며 사용자 행동에 대한 가치 있는 통찰을 제공합니다.