![]()
샘플 eBook 챕터(무료): 링크
Teachable.com에서 eBook: $22.50 링크
Amazon.com에서 프린트 버전: $65 링크
이전 장인 “시계열 모델링 기법의 진행 과정”에서 우리는 단순 이동 평균, 계절적 추세 분해, ARIMA, 칼만 필터, 상태 공간 모델의 연결을 조사했으며 그 후에 RNN/LSTM/GRU까지 살펴보았습니다. 이 장에서는 RNN/LSTM에서 Temporal Fusion Transformers 및 Lag-Llama를 포함한 Transformer 기반 모델로 학습을 이어나갈 것입니다.
오늘날의 많은 대형 언어 모델은 시계열 RNN/LSTM의 뿌리를 갖고 있으며 논문 “Attention is all you need”의 Transformer 프레임워크와 관련이 있습니다. RNN/LSTM에서 Transformer로 연결되는 여러 중요한 이정표가 있습니다. 시퀀스-투-시퀀스 모델링, 어텐션 메커니즘, 그리고 셀프-어텐션 메커니즘(셀프-어텐션과 어텐션은 다르다는 점에 유의해야 합니다). 언급된 각 알고리즘마다 하나의 장을 할애할만한 가치가 있지만, 이 장은 한 혁신에서 다른 혁신으로의 연결을 살펴보고자 합니다. 어느 것에서 다른 것으로 진화하며 우리는 혁신에 대해 새로운 시각을 가질 것이며 앞으로의 작업에 영감받을 것입니다. 또한 대형 언어 모델(LLMs)이 시계열 RNN/LSTM 모델에서 비롯되었기 때문에 왜 우리가 특히 LLMs를 바로 시계열 모델링에 사용하지 않아도 되는지 알아볼 것입니다. Transformer 모델을 시계열 모델링에 적용하기 위해 무엇을 해야 하는지 설명하겠습니다. 이 장에서는 다음을 다룰 것입니다:
- RNN/LSTM에서 시퀀스-투-시퀀스(Seq2Seq) 학습으로
- 어텐션 메커니즘
- 셀프-어텐션 메커니즘
- Transformer 모델
- Transformer에서 Temporal Fusion Transformer로
- 시계열을 위한 대규모 기본 모델의 필요성
- Lag-Llama - 오픈소스 시계열 기본 모델
RNN/LSTM에서 시퀀스-투-시퀀스(Seq2Seq) 모델로
2000년대에 처음 보이스 번역 장치를 구매했어요. 번역 품질은 그저 괜찮았지만 한국과 파리로 여행하는 데 도움이 되었어요. 번역 품질이 더 좋아진다면 서로 다른 언어를 구사하는 세계 사람들이 쉽게 소통할 수 있게 도울 것입니다. 지난 20년 동안 많은 연구자들이 이와 같은 전 세계적인 응용 프로그램을 해결하기 위해 노력해 왔어요. 초기 알고리즘인 "통계 기계 번역 (SMT)"과 "숨겨진 마르코프 모델 (HMMs)"은 n-gram, 구문 기반 기능, 정렬 기능과 같은 수작업 기능을 사용하여 한 언어에서 다른 언어로 텍스트를 번역했어요. 이러한 전통적인 알고리즘은 수작업 기능이 필요하며 종종 유연하지 못하고 훈련하기 어려워요. 언어 번역에서 또 다른 과제는 원본 문장과 대상 문장 사이의 길이 차이에 있어요. 아래의 영어 문장과 프랑스어, 이탈리아어 번역을 보겠어요:
- 영어 (15 단어): “After finishing work, I often make a detour to the chocolate shop for some treats.”
- 프랑스어 (16 단어): “Après avoir fini le travail, je fais souvent un détour par la chocolaterie pour quelques friandises.”
- 이탈리아어 (18 단어): “Dopo aver finito il lavoro, spesso faccio un giro di sosta al negozio di cioccolato per qualche dolcetto.”
이러한 길이의 차이는 언어 번역이 기계적인 일대일 번역보다 의미적 이해력이 필요하다는 것을 보여줍니다.
Ilya Sutskever, Oriol Vinyals 및 Quoc V. Le이 2014년에 "Neural Networks를 사용한 Sequence to Sequence Learning" 논문을 발표했을 때 번역 솔루션이 크게 발전했어요 [1]. 그들의 신경망 프레임워크는 일반적인 유연성을 제공하며 수작업 기능이나 특별한 기능이 필요하지 않아요. 무엇보다도, Seq2Seq는 다양한 길이 문제를 효과적으로 해결할 수 있어요. Seq2Seq는 입력 시퀀스를 "컨텍스트 벡터"로 인코딩하는 인코더 네트워크와 이 벡터로부터 출력 시퀀스를 생성하는 디코더 네트워크로 구성되어 있어요. 이 전략은 입력 시퀀스와 대상 시퀀스를 아주 잘 분리시킵니다. (그림 1)을 참조해 보세요.
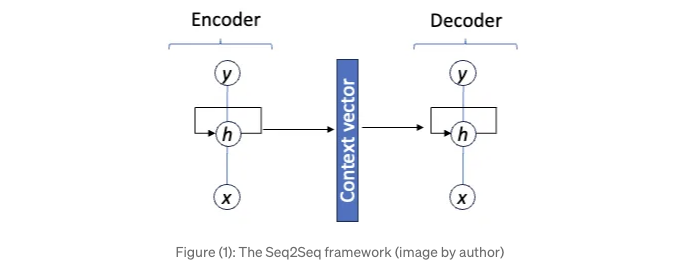
인코더 RNN과 디코더 RNN의 펼침 표현이 포함된 그림 (2)입니다. 컨텍스트 벡터는 입력 시퀀스의 의미적인 의미를 포착합니다. Seq2Seq 모델은 정보를 해석하여 다른 언어로 번역하기 위한 방법으로 생각할 수 있습니다.
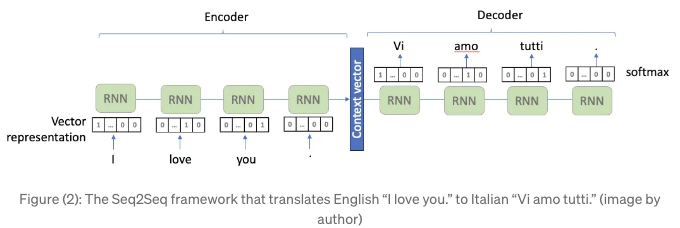
RNN/LSTM은 시계열 모델링 도구이며 이제는 언어 모델링 도구로 활용되고 있습니다. 언어 데이터와 시계열 데이터 사이에 기본적인 차이가 있습니다. 언어 데이터는 단어와 문장부호이고, 시계열 데이터는 숫자 값입니다. 언어 데이터는 신경망 알고리즘에 피드하기 위해 숫자 벡터 표현으로 변환되어야 합니다. 출력 또한 단어가 되도록 디코딩되어야 합니다. 논문 [1]에서는 입력 데이터로 16만개의 자주 사용되는 단어를 사용했습니다. 단어 "I"는 "I"의 요소 위치가 1.0이고 그렇지 않으면 0.0인 16만 길이의 벡터가 됩니다. 마찬가지로, 단어 "love"는 다른 16만 길이의 벡터로 "love"의 요소 위치가 1.0이 되고 그렇지 않으면 0.0이 됩니다. 텍스트 표현에 대한 자세한 설명은 Kuo (2023)의 "The Handbook of NLP with Gensim" [3]에서 찾아볼 수 있습니다.
그림(2)에서 RNN 블록들이 하는 일은 무엇인가요? 이들은 이전 숨겨진 상태 ht-1과 새로운 입력 xt의 가중 평균을 계산하고, 편향을 더합니다. 가중치와 편향은 모델의 보물이라고 할 수 있습니다. RNN 블록들의 가중치와 편향은 "I", "love", "you"와 같은 다른 입력 벡터 표현과는 무관하게 항상 동일합니다. 위의 RNN 프레임워크는 모든 RNN 블록을 연결하는 하나의 숨겨진 상태를 가지고 있습니다. 긴 문장의 경우 잘 알려진 사라지는 그래디언트 문제가 발생합니다. 사라지는 그래디언트 문제는 Long Short-Term Memory로 해결됩니다. 여기서 내용을 반복하지 않고, 이전 챕터 "시계열 모델링 기법의 진화"를 참조하시면 사라지는 그래디언트 문제와 LSTM이 문제를 해결하기 위해 장기기억을 위한 하나, 단기기억을 위한 다른 하나의 숨겨진 경로를 생성하는 과정이 설명되어 있습니다. 그림(3)은 LSTM 블록으로 RNN 블록을 대체합니다.
이제 가중치와 편향에 집중해 봅시다. 단어의 위치와 무관하게 모두 동일하다는 사실은 너무 제한적으로 보입니다. 예를 들어, "love"와 "."가 동일한 가중치와 편향을 갖는 것은 자연스럽지 않고 제한적으로 보입니다. 모든 말소통이 마법 같으며 많은 내재적 함축을 가질 수 있습니다. 문장을 인코딩하기 위해 LSTM 세트만 사용하는 것은 많은 정보를 잃을 수 있습니다.
입력의 더 다양한 변형을 캡처하기 위해, 연구자들은 Figure (4)의 검은 LSTM과 빨간 LSTM과 같이 두 번째 세트의 LSTM을 추가합니다. 모든 검은 LSTM은 동일한 가중치와 편향을 가지고 있으며, 모든 빨간 LSTM은 동일한 가중치와 편향을 가지고 있는데 이는 검은 LSTM과 다릅니다. 따라서 두 세트의 LSTM은 입력 벡터의 변형을 캡처하기 위해 두 세트의 단기 메모리와 장기 메모리를 가지고 있습니다. 필요하다면 더 많은 층의 LSTM을 추가할 수 있습니다. 이 개념은 나중에 "Multi-head"로 불리는 Transformer 모델에서 차용되었음을 기억하세요.
Figure (2)에서 컨텍스트 벡터와 디코더에 대해 이야기해 봅시다. 컨텍스트 벡터는 디코더의 초기값을 제공합니다. 디코더는 LSTM 블록으로 구성되어 있습니다. 디코더의 모든 LSTM은 동일한 가중치와 편향을 가지고 있지만, 인코더의 LSTM들과는 다릅니다. 각 LSTM은 소프트맥스 함수를 통해 디코딩 될 단어나 구두점이 될 벡터를 전달할 것입니다. 문장이 고정 길이보다 짧은 경우, [EOS] (문장의 끝) 심볼이 채워집니다. 따라서 Seq2Seq는 소스와 타겟 문장의 길이에 대처할 수 있습니다.
Seq2Seq의 혁신을 알았으니, 이제 두 번째 특징인 주의 메커니즘에 대해 알아봅시다.
문장을 듣게 되면, 우리는 중요한 키워드에 주의를 기욽하지 않고 있습니다. "일을 끝내고 나면 종종 초콜릿 가게에 들르러 간다"라는 문장을 들을 때, "일을 끝낸 후"와 "초콜릿 가게"라는 키워드를 파악합니다. 이 특별한 주의는 입력 문장의 일부에 초점을 맞춘 주의 메커니즘입니다. Seq2Seq도 마찬가지로 작동합니다. 해당 단어들에 더 많은 주의를 기울여 해당 단어들을 대상 언어로 변환합니다.
그림(3)의 "단일 파이프라인" 아키텍처의 주요 단점은 인코더가 입력 문장 전체를 하나의 숨겨진 상태 벡터 ht로 표현해야 한다는 것입니다. 이는 모든 정보를 숨겨진 상태 ht로 압축해야 하므로 정보 손실을 초래할 수 있습니다. 더욱이, 디코더는 단일 벡터에서 정보를 해석해야 합니다. Seq2Seq 모델의 맥락에서 주의 메커니즘을 소개한 중요한 논문 중 하나는 2015년 Dzmitry Bahdanau, Kyunghyun Cho 및 Yoshua Bengio가 공동으로 "바다나우 등의 연구팀이 발표한" "Neural Machine Translation by Jointly Learning to Align and Translate"입니다. 그들은 디코더가 각 디코딩 단계에서 입력 시퀀스의 관련 부분에 초점을 맞출 수 있도록 주의 메커니즘을 설계했습니다. 이 작업은 주의 메커니즘을 통해 시퀀스 투 시퀀스 모델링의 이후 발전을 위한 기초를 마련했습니다.
이미지
그림(5)은 왼쪽의 단일 파이프라인 아키텍처가 오른쪽의 주의 메커니즘으로 대체된 것을 보여줍니다. 디코딩하는 동안 각 시간 단계마다, 디코더는 이전 숨겨진 상태 및 이전에 생성된 토큰을 기반으로 숨겨진 상태(gt)를 생성합니다. 그런 다음 주의 메커니즘은 입력 시퀀스의 각 위치에 대해 주의 가중치를 계산합니다. 이 가중치는 각 입력 토큰이 현재 디코딩 단계에 대해 얼마나 관련성 또는 중요성이 있는지 나타냅니다. 주의 가중치를 사용하여 컨텍스트 벡터가 계산되고 인코더 상태의 가중 합으로 계산됩니다. 그런 다음 이 컨텍스트 벡터가 현재 디코더 상태와 결합되어 현재 시간 단계의 출력 토큰을 생성합니다.
중요한 요점을 요약해봅시다. 인코딩은 정보를 읽거나 받아들이는 것과 같습니다. 디코딩은 이를 사용자의 자신의 말로 표현하는 것과 같습니다. 우리가 단어로 말할 때, 우리는 읽은 내용 중 일부 중요한 단어에 더 많은 주의를 기울이고 그에 따라 묘사할 수 있습니다. 주의 메커니즘은 모델이 출력 순서를 생성할 때 입력 순서의 일부에 서로 다른 가중치를 할당할 수 있도록 합니다.
특수한 유형의 주의 메커니즘인 셀프-어텐션은 보다 효과적임이 입증되었습니다. 이것이 무엇인지 알아봅시다.
주의에서 셀프-어텐션으로
셀프-어텐션은 내부 주의라고도 불리는 특정 유형의 주의 메커니즘입니다. "셀프"라는 용어는 셀프-어텐션이 외부 문장에 주의를 기울이는 것이 아닌 같은 문장 내에서 내부적으로 작동한다는 점을 강조합니다. 이 메커니즘은 다양한 자연어 처리 작업에서 매우 효과적임이 입증되었습니다. 이는 “Attention is All You Need”(2017) [2]라는 고전적 논문에서 제안되었습니다.
(6)번 그림은 인기 있는 오픈 소스 앱 bertviz (https://github.com/jessevig/bertviz)에 의한 자기 주의 예제를 보여줍니다. "토끼는 빨리 뛰었고, 거북이는 천천히 기어갔다"라는 문장에서 "토끼"라는 단어는 "뛰었고"와 더 관련이 있고, "거북이"라는 단어는 "기어갔다"와 연관이 있습니다. 단어 사이의 선의 두께는 관계의 강도를 나타냅니다. "토끼"라는 단어가 나오면 "뛰었고"를 예측할 확률이 높으며, 마찬가지로 "거북이"는 "기어갔다"를 예측할 가능성이 높습니다.

자기 주의를 계산하려면 입력 임베딩을 쿼리 벡터, 키 벡터, 밸류 벡터의 세 종류로 변환합니다. 이러한 변환은 일반적으로 모델의 학습 파라미터인 선형 프로젝션으로 이루어집니다. 같은 문장의 각 토큰에 대해 주의 점수는 그 토큰의 쿼리 벡터와 문장의 모든 토큰의 키 벡터 사이의 내적을 계산함으로써 구합니다.
쿼리, 키, 밸류 벡터에 대해 설명이 필요할 것 같네요. 하나씩 설명해보죠.
- 쿼리 벡터(Query Vectors): 쿼리 벡터는 학습된 선형 변환을 거친 후의 입력 시퀀스의 토큰(보통 단어 또는 하위 단어)를 나타냅니다. 입력 시퀀스 내 각 토큰은 해당하는 쿼리 벡터를 생성합니다. 이러한 쿼리 벡터는 키 벡터와 비교되어 각 토큰이 얼마나 주목을 받아야 하는지를 결정하는 주의 점수를 산출합니다. 예를 들어, "모던 시계열 예측 기법"이라는 쿠오(Kuo)의 책을 찾기 위해 도서관에 있는 상황을 상상해보세요. 여러분의 쿼리 벡터는 검색을 시작하는 질문처럼 작용합니다. 찾고자 하는 것을 좀 더 좁혀주는 역할을 합니다. 예를 들어, 쿼리 벡터는 "쿠오의 '모던 시계열 예측 기법' 책을 찾을 수 있는 곳은 어디인가요?"와 같을 것입니다.
- 키 벡터(Key Vectors): 쿼리 벡터와 비슷하게, 키 벡터는 다른 학습된 선형 변환을 거친 후의 입력 시퀀스의 토큰을 나타냅니다. 이들은 주의 메커니즘에 대한 참조 역할을 합니다. 주의 메커니즘은 각 쿼리 벡터와 각 키 벡터 간의 유사성을 계산하여 입력 시퀀스 내 각 토큰의 관련성이나 중요성을 결정합니다. 키 벡터는 도서관의 서로 다른 책장에 붙어 있는 라벨과 같이 생각할 수 있습니다. 각 라벨(키 벡터)은 그 특정 섹션에 무엇이 들어있는지 알려줍니다. 질문(쿼리)을 하면, 모델은 이러한 키 벡터를 사용하여 어떤 도서관 섹션에 주목해야 하는지 판단합니다. 따라서, 만약 여러분의 쿼리가 시계열에 관한 것이라면, 키 벡터는 도서관의 시계열 책 섹션의 라벨 역할을 합니다.
- 값 벡터(Value Vectors): 값 벡터는 공부한 선형 변환을 거친 후의 입력 토큰들의 또 다른 표현입니다. 이러한 벡터들은 각 토큰과 연관된 실제 정보를 저장합니다. 주의 계산 중에 쿼리 벡터와 키 벡터를 비교하여 얻은 주의 점수는 값 벡터들에 가중치를 부여하는 데 사용됩니다. 값 벡터의 가중합은 주의 메커니즘의 출력을 제공합니다. 도서관 비유를 계속하자면, 값 벡터는 책 자체와 같습니다. 여러분이 관심 있는 실제 정보를 담고 있습니다. 모델이 여러분의 질문(쿼리 벡터)을 기반으로 어떤 도서관의 "시계열" 책 섹션(키 벡터)을 찾으면, 그 안에 있는 쿠오의 "모던 시계열 예측 기법" 책(값 벡터)을 읽게 됩니다.
트랜스포머 모델
트랜스포머 모델은 주의 메커니즘을 기반으로 한 구조로 자연어 처리 작업을 혁신적으로 변화시켰습니다. 아래는 트랜스포머 아키텍처를 보여주는 그림입니다.
- 입력 임베딩: 트랜스포머 모델의 입력은 토큰화된 입력 시퀀스로 구성됩니다. 각 토큰은 처음에는 Figure (2)에 설명된 대로 고정 차원 벡터로 표현됩니다.
- 위치 인코딩: "나는 아이스크림을 좋아해"와 같은 문장이 있다고 가정해봅시다. 트랜스포머 모델에서는 "나", "좋아해", "아이스크림"을 개별 단어로만 이해하는 것이 아니라 "나"가 먼저 오고, 그 다음에 "좋아해", 그리고 "아이스크림"이 온다는 것도 이해해야 합니다. 문장을 읽을 때, 단어 자체뿐만 아니라 문장 내 순서에 따라 의미를 자연스럽게 이해합니다. 비슷하게, 트랜스포머 모델에서는 각 단어나 토큰의 위치에 대해 모델에게 알려주는 방법이 필요합니다. 위치 인코딩은 시퀀스 내 각 단어나 토큰에 부착된 작은 태그처럼, 모델에게 시퀀스 내 위치에 대해 알려주는 역할을 합니다. 따라서 트랜스포머는 입력을 더 잘 이해하기 위해 단어 자체와 이러한 위치 태그를 함께 사용할 수 있습니다.
- 다중 헤드 셀프 어텐션 메커니즘: 우리는 이미 이전 섹션에서 "셀프 어텐션"을 배웠습니다. 이는 동일한 문장 내 일부 부분에 주의를 기울이는 것을 의미합니다. 그렇다면 "다중 헤드"는 무엇을 의미할까요? Figure (3)에서 이미 이 아이디어를 볼 수 있습니다. 여기서도, 한 번만 어텐션을 계산하는 대신 모델은 병렬로 여러 번 어텐션을 계산할 수 있으며, 각각은 학습된 선형 투영 세트를 갖습니다. 이러한 병렬 계산을 "어텐션 헤드"라고 합니다.
- 완전 연결 피드 포워드 네트워크: 이것은 표준 신경망입니다. "완전 연결"이란 한 층의 각 뉴런이 다음 층의 각 뉴런에 연결되어 있는 것을 의미합니다. "피드 포워드"는 피드백 루프 없이 네트워크를 통해 데이터가 흐르는 것을 나타냅니다.
Figure (6)의 오른쪽에 있는 디코더 스택은 인코더 스택과 유사하지만 인코더의 출력에 주의를 기울이는 추가적인 셀프 어텐션 레이어가 포함되어 있습니다. 이는 디코더가 출력 시퀀스를 생성하는 동안 입력 시퀀스의 관련 부분에 집중할 수 있게 합니다. 마지막 레이어는 목표 어휘에 대한 출력 확률 분포를 생성하기 위한 소프트맥스 함수입니다.
위의 내용 외에도 모델은 표준 역전파 및 아담 옵티마이저를 사용한 확률적 경사 하강법을 사용하여 훈련됩니다. 훈련 중에 인코더와 디코더는 예측된 시퀀스와 목표 시퀀스 사이의 크로스 엔트로피 손실을 최소화하기 위해 함께 훈련됩니다.
트랜스포머에서 시계열 퓨전 트랜스포머(TFT)로!
Transformer 아키텍처는 원래 기계 번역 및 질문 응답과 같은 순차 대 순차 작업을 위해 설계되었습니다. 시계열 모델링에 적응하기 위해서는 Transformer 아키텍처를 수정하여 시계열 데이터의 시간 종속성을 처리할 수 있어야 합니다. 이는 위치 부호화를 추가하거나 반복을 통합하거나 Transformer 아키텍처의 변형을 사용하는 것을 포함합니다. 몇 가지 고려해야 할 사항을 나열해 보겠습니다:
첫째, 시계열은 종종 여러 시간 단계에 걸쳐 범주화된 복잡한 시간 패턴과 종속성을 보입니다. 상당한 수정 없이 Transformer 모델은 시간 패턴을 효과적으로 포착하지 못할 수 있습니다. 둘째, 시계열 데이터에는 캘린더 관련 기능이 있습니다. 캘린더 관련 기능은 표준 Transformer 아키텍처로 명시적으로 포착되지 않을 수 있습니다. 셋째, 시계열 데이터는 변수 길이를 가질 수 있습니다. 다양한 길이의 입력을 처리하기 위해 Transformer 아키텍처를 적응하는 것은 추가 수정이나 기술이 필요합니다. 넷째, 시계열에서 예측 불확실성이 필요합니다. 언어 모델은 일반적으로 이를 갖고 있지 않습니다.
위와 같은 이유로 연구자들은 Transformer 모델을 시계열 모델링에 더 효과적으로 사용하기 위해 적응 및 확장을 탐구해 왔습니다. 중요한 이정표 모델은 Temporal Fusion Transformer (TFT)입니다. 2020년에 Bryan Lim, Sercan O ̈. Arık, Nicolas Loeff, Tomas Pfister가 "Temporal Fusion Transformers for Interpretable Multi-horizon Time Series Forecasting"라는 선구적 논문을 발표하여 다중 시리즈 및 다중 기간 시계열 모델링에 대해 제안했습니다.
여러 시계열 데이터의 특징을 얻는 방법부터 시작해 보겠습니다. 시계열 데이터는 현재 및 늦춰진 값 사이의 시간적 패턴을 가집니다. 또한 캘린더 관련 정보도 포함하고 있습니다. 캘린더 기능은 일주일의 날짜나 월의 주와 같은 것들인데, 미래에도 결정적입니다. 그래서 TFT는 네 가지 종류의 특징을 만듭니다. 이전 장 "Amazon's DeepAR for RNN/LSTM"의 Walmart 매장 판매 데이터를 사용하여 네 가지 특징 그룹을 설명하겠습니다.
- (특징 그룹 1) 상점의 과거 공변량: 상점 i의 과거 판매 yt-1, yt-2, … 이며 t시간까지만 알려진 시간 변동적 데이터입니다.
- (특징 그룹 2) 상점 매출에 영향을 미치는 기타 데이터: 날씨나 소비자 지수와 같은 데이터로, t시간까지만 알려진 시간 변동적 정보입니다.
- (특징 그룹 3) 요일, 월 중 주차, 공휴일과 같은 달력 특징들.
- (특징 그룹 4) 시간과 무관한 특징들으로, 시간과 관련이 없는 상점 ID나 지역과 같은 특징들입니다.
TFT는 데이터 내에서 복잡한 시계열 종속성을 포착하기 위해 self-attention 메커니즘을 활용합니다. 시계열 데이터의 시간적 성격을 포착하기 위해, 저자들은 시간 인코딩 기술을 소개하였습니다. 이러한 기술들은 모델이 입력 시퀀스에 시간 관련 정보를 통합하여 시간적 패턴과 추세를 더 잘 포착할 수 있게 합니다. 시계열의 자기회귀적 패턴을 알기 위해, TFT는 다중 시계열 예측을 생성하기 위한 자기회귀 메커니즘을 활용합니다.
Transformer 아키텍처 외에도, TFT를 매력적인 선택지로 만드는 여러 기여 요소가 있습니다. TFT의 주요 기여 중 하나는 해석 가능성에 중점을 둔 점입니다. 저자들은 입력 특징과 시간 요소의 중요성을 강조하는 attention 메커니즘을 소개하였으며, 이는 예측을 더 해석 가능하고 사용자에게 투명하게 만듭니다. TFT는 예측과 함께 불확실성의 추정치를 제공하여 불확실성 하에 의사 결정을 내릴 수 있게 합니다. 각 예측에 관련된 불확실성을 측정함으로써, 모델은 더 신뢰할 수 있는 예측을 제공하고 위험 관리 전략을 안내할 수 있습니다. TFT는 다중 시점 예측을 생성할 수 있으며, 여러 시점 다음의 미래 값을 예측합니다. 마지막으로, TFT는 효과적으로 누락된 또는 희소한 데이터를 처리하도록 설계되었습니다. 불완전한 데이터로부터 학습하고 일부 관측치가 누락된 상황에서도 예측을 수행할 수 있으며, 이는 실제 시계열 데이터셋에서 흔한 일입니다.
이번 개요 챕터에서는 TFT에 대해 깊이 파헤치지 않을 예정입니다. 다음 챕터 "해석 가능한 시계열 예측을 위한 Temporal Fusion Transformer"에서 TFT 아키텍처와 시각화에 대해 자세히 알아보겠습니다.
왜 대규모 기본 모델을 사용해야 할까요?
대규모 기본 모델은 일반적인 용도로 대량의 데이터를 기반으로 훈련됩니다. 특정 작업에 맞게 세밀하게 조정할 수도 있습니다. 언어 모델에서는 GPT-2 (2019), GPT-3 (2020), chatGPT (2022), GPT-4 (2023), T-5 (2019), Flan-T5 (2022), BERT (2018), RoBERTa (2019), DeBERTa (2019), DistilBERT (2020), 그리고 MPT-7B-StoryWriter-65k+ 등을 들어본 적이 있을 겁니다. 이러한 모델들은 언어의 세세한 부분에 대해 효과적으로 학습하며, 문법, 의미, 맥락을 이해합니다. "The data that those large language models were built on" [6]라는 글에서는 책, 기사, 인터넷 게시물과 같은 데이터 원본을 자세히 설명하여 모델을 훈련시킨 것을 살펴볼 수 있습니다.
대규모 기본 모델이 시계열 데이터에 중점을 두는 이유는 무엇일까요? 이곳에서 몇 가지 좋은 동기를 제시해보겠습니다. 사전 훈련된 시계열 기본 모델은 재무, 의료, 천문학과 같은 다양한 시계열 데이터를 이미 훈련받아 일반적인 패턴을 인식할 수 있습니다. 그들은 세세한 조정 없이 보지 못한 시계열 데이터의 패턴을 인식할 수 있습니다. 그들의 유연성으로 인해 서로 다른 산업의 데이터 유형, 샘플링 빈도 및 예측 기간을 처리할 수 있습니다. 시계열의 기본 모델은 작업별 모델 개발의 필요성을 줄이고 배포 속도를 높일 수 있습니다. 또 다른 장점은 예측 해석이 가능하다는 점입니다. 많은 대규모 기본 모델은 이미 해석 가능성 매커니즘을 통합하여 사용자가 모델이 어떻게 예측하고 예측하는지를 이해할 수 있도록 도와줍니다.
Lag-Llama— 오픈 소스 시계열 기본 모델
Lag-Llama 모델은 LLaMA 모델의 디코더 부분을 기반으로 하며 다양한 시계열 데이터 코퍼스에서 학습되었습니다. 이 모델은 단변량 확률적 예측을 위한 범용적인 기본 모델입니다. "Lag"를 LLaMA에 접두사로 추가한 이유는 시계열의 지연 항을 공변량으로 사용하기 때문입니다. Lag-Llama는 선형성이나 정상성을 가정하지 않고 시간 의존성을 잡기 위해 과거 시계열 값의 지연된 특징을 사용합니다.
시계열 데이터와 언어 데이터에는 차이가 있습니다. 현재 및 지연된 시계열 값에는 시간 패턴이 있습니다. 또한 시계열 데이터에는 주 단위, 월 단위 등과 같은 달력 관련 정보가 있습니다. 따라서 Lag-Llama는 입력을 지연된 공변럇 (t=1, 7, 14, 21, …, 𝛕) 및 도표(8)에 나와 있는 것과 같이 달력 관련 기능으로 활용합니다. 시계열 데이터는 입력을 인코딩하는 방식이 매우 다르기 때문에 Lag-Llama가 LLaMA 모델의 디코더 부분을 사용하는 이유입니다.
Lag-Llama는 확률적 출력을 학생 t-분포에서 추출한 결과로 근사합니다. 따라서 학생 t-분포의 세 매개변수, 즉 자유도, 평균 및 척도를 모델링합니다. "시계열 확률적 예측을 위한 몬테칼로 시뮬레이션"이라는 이전 챕터에서 학생 t-분포에 대해 공부했습니다. 학생 t-분포를 이해하기 위해 해당 챕터를 참조할 수 있습니다. Lag-Llama에는 다른 분포도 포함시킬 수 있습니다.
라그-라마는 LLaMA를 기반으로 하며, LLaMA는 Transformer 모델을 기반으로 합니다. 다음 장 "시계열 예측을 위한 오픈 소스 Lag-라마 튜토리얼"에서는 디코드 전용 트랜스포머 기반 아키텍처 LLaMA를 살펴볼 예정입니다.
학습된 데이터 소스를 이해해봅시다. 라그-라마는 에너지, 교통, 경제, 자연, 대기 품질 및 클라우드 운영과 같은 다양한 도메인의 27개 시계열 데이터셋 코퍼스를 사용합니다. 학습 데이터의 다양성에는 주파수, 각 시리즈의 길이, 예측 길이, 여러 시리즈 수 등이 포함됩니다. 이러한 다양한 데이터 소스는 라그-라마가 명시적으로 학습되지 않은 새로운 시계열을 모델링할 수 있게 합니다. 이를 제로샷 학습이라고 합니다. 제로샷 학습은 모델이 학습 중에 이전에 본 적이 없는 클래스를 인식하도록 학습되는 새로운 학습 접근 방법입니다.
요약
이 장에서는 RNN/LSTM부터 Temporal Fusion Transformer 및 Lag-라마로 이어지는 시계열 모델링 기술의 진화를 살펴보았습니다. Seq2Seq 모델, 어텐션 메커니즘, 셀프 어텐션 메커니즘 및 트랜스포머 모델에 대해 다루었습니다. 언어 트랜스포머 모델이 시계열에 효과적이지 않을 수 있는 이유를 설명했습니다. 그리고 시계열 인코딩 기술을 통합하고 해석 가능성과 불확실성 추정을 강조하는 Temporal Fusion Transformer(TFT)를 소개했습니다. 마지막으로, 단일 변수 확률적 시계열 예측을 위해 설계된 오픈 소스 기본 모델인 Lag-라마를 소개했습니다.
앞으로의 몇 장에서는, 해석 가능성을 위해 시계열 모델을 시각화하는 방법을 포함한 Temporal Fusion Transformer를 배우게 될 것입니다. Lag-Llama를 활용하여 시계열 모델을 구축하는 방법도 알아볼 거에요.
참고 자료
- [1] Sutskever, I., Vinyals, O. & Le, Q. V. (2014). 신경망을 이용한 시퀀스 대 시퀀스 학습. 신경정보처리시스템 발전(p./pp. 3104–3112)
- [2] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł. & Polosukhin, I. (2017). 어텐션 이 필요한 모든 것. 신경정보처리시스템 발전(p./pp. 5998–6008).
- [3] Kuo, C. (2023). Gensim으로 NLP 핸드북: 텍스트 데이터 내에서 숨겨진 패턴, 테마 및 가치있는 통찰력 발굴하기. Packt Publishing. ISBN-13: 978–1803244945
- [4] Bahdanau, D., Cho, K., & Bengio, Y. (2014). 맞추고 번역하기 위해 공동 학습하는 신경 기계 번역. CoRR, abs/1409.0473.
- [5] Lim, Bryan & Arık, Sercan Ö. & Loeff, Nicolas & Pfister, Tomas, 2021. “해석 가능한 멀티-호라이즌 시계열 예측을 위한 Temporal Fusion Transformer,” 예측 국제 저널, Elsevier, vol. 37(4), pages 1748–1764.
- [6] Kuo, C., (2023). 대형 언어 모델이 구축된 데이터. Medium.com
- [7] Rasul, K., Ashok, A., Williams, A.R., Khorasani, A., Adamopoulos, G., Bhagwatkar, R., Bilovs, M., Ghonia, H., Hassen, N., Schneider, A., Garg, S., Drouin, A., Chapados, N., Nevmyvaka, Y., & Rish, I. (2023). Lag-Llama: 확률론적 시계열 예측을 위한 기점 모델로 향하여.
- [8] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., Rodriguez, A., Joulin, A., Grave, E. & Lample, G. (2023). LLaMA: 열리고 효율적인 기반 언어 모델 (arxiv:2302.13971을 인용하십시오)
- [9] Chowdhery, A., Narang, S., Devlin, J., Bosma, M., Mishra, G., Roberts, A., Barham, P., Chung, H.W., Sutton, C., Gehrmann, S., Schuh, P., Shi, K., Tsvyashchenko, S., Maynez, J., Rao, A., Barnes, P., Tay, Y., Shazeer, N.M., Prabhakaran, V., Reif, E., Du, N., Hutchinson, B.C., Pope, R., Bradbury, J., Austin, J., Isard, M., Gur-Ari, G., Yin, P., Duke, T., Levskaya, A., Ghemawat, S., Dev, S., Michalewski, H., García, X., Misra, V., Robinson, K., Fedus, L., Zhou, D., Ippolito, D., Luan, D., Lim, H., Zoph, B., Spiridonov, A., Sepassi, R., Dohan, D., Agrawal, S., Omernick, M., Dai, A.M., Pillai, T.S., Pellat, M., Lewkowycz, A., Moreira, E., Child, R., Polozov, O., Lee, K., Zhou, Z., Wang, X., Saeta, B., Díaz, M., Firat, O., Catasta, M., Wei, J., Meier-Hellstern, K.S., Eck, D., Dean, J., Petrov, S., & Fiedel, N. (2022). PaLM: 경로로 언어 모델링 확장. J. Mach. Learn. Res., 24, 240:1–240:113.
- [10] Shazeer, N.M. (2020). GLU 변형은 트랜스포머를 개선시킵니다. ArXiv, abs/2002.05202.
- [11] Su, J., Lu, Y., Pan, S., Wen, B., & Liu, Y. (2021). RoFormer: 회전 위치 임베딩이 추가된 향상된 트랜스포머. ArXiv, abs/2104.09864.
- [12] Zhang, B., & Sennrich, R. (2019). 평균 제곱근 레이어 정규화. ArXiv, abs/1910.07467.
샘플 eBook 장(chapter) (무료): 여기를 클릭해주세요
- 이노베이션 프레스 주식회사 스태프 여러분께 감사드립니다. 아름다운 형식으로 책을 재현하여 즐거운 독서 경험을 선사해 주셨습니다. 전 세계 독자들에게 책을 배포하기 위해 Teachable 플랫폼을 선택했습니다. Teachable.com에서 신용카드 거래는 안전하고 비밀리에 처리됩니다.
Teachable.com의 eBook: $22.50 https://drdataman.teachable.com/p/home
Amazon.com의 인쇄판: $65 https://a.co/d/25FVsMx
- 인쇄판은 유광 표지, 컬러 인쇄, 아름다운 Springer 글꼴 및 배치를 채택하여 즐거운 독서를 제공합니다. 7.5 x 9.25인치의 포털 크기는 여러분의 책장에 있는 대부분의 책과 잘 어울립니다.
- "이 책은 시계열 분석 및 예측 분석, 이상 탐지에 대한 깊은 이해를 증명하는 책입니다. 독자들이 현실 세계의 문제에 대처하기 위한 필수 기술을 갖추게 도와줍니다. 데이터 과학 분야로의 직군 전환을 원하는 사람들에게 특히 가치 있습니다. Kuo는 전통적이고 혁신적인 기술에 대해 상세히 탐구합니다. 최신 경향과 발전을 반영하기 위해 신경망 및 다른 고급 알고리즘에 대한 논의가 통합되어 있습니다. 이를 통해 독자들은 기존 방법뿐만 아니라 데이터 과학 분야의 가장 최신이자 혁신적인 기술과 상호작용할 준비가 되어 있습니다. Kuo의 생동감 넘치는 글쓰기 스타일로 책의 명료함과 접근성이 향상되었습니다. 그는 복잡한 수학적 및 통계적 개념을 분명하게 풀어내어 엄밀성을 희생하지 않으면서도 접근하기 쉽게 만들었습니다."
현대 시계열 예측: 예측 분석 및 이상 탐지
Chapter 0: 서문
Chapter 1: 소개
Chapter 2: 비즈니스 예측을 위한 Prophet
장 3: 튜토리얼 I: 추세 + 계절성 + 휴일 및 이벤트
장 4: 튜토리얼 II: 추세 + 계절성 + 휴일 및 이벤트 + 자기회귀(AR) + 지연 회귀자 + 미래 회귀자
장 5: 시계열 데이터의 변곡점 탐지
장 6: 시계열 확률 예측을 위한 몬테카를로 시뮬레이션
7장: 시계열 확률 예측을 위한 분위 회귀
8장: 시계열 확률 예측을 위한 적합 예측
9장: 시계열 확률 예측을 위한 회귀를 준수하다
10장: 자동 ARIMA!