PDF (Portable Document Format) 파일은 다양한 형식과 일관된 포맷팅을 가지고 있어 문서 공유와 보존에 널리 사용됩니다. 텍스트 콘텐츠 외에도 PDF 파일에는 종종 가치 있는 이미지가 포함되어 있습니다. 이러한 이미지를 추출하고 위치 (x와 y 좌표), 너비, 높이와 같은 관련 정보를 검색함으로써 이미지 분석, 조작, 그리고 다양한 프로젝트에 통합하는 많은 가능성을 발견할 수 있습니다. 이 블로그 포스트에서는 Python을 사용하여 PDF 파일에서 이미지와 이미지 정보를 추출하는 방법을 알아보겠습니다.
- Python으로 PDF에서 이미지 추출하기
- Python으로 PDF에서 이미지 정보 추출하기
Python을 사용하여 PDF로부터 이미지 및 이미지 정보 추출하는 라이브러리
Python에서 PDF 파일로부터 이미지와 이미지 정보를 추출하기 위해 Spire.PDF for Python을 사용할 것입니다. 이 라이브러리는 Python 애플리케이션 내에서 PDF 파일을 생성, 읽기, 편집, 변환할 수 있도록 설계된 기능이 풍부하고 사용자 친화적인 라이브러리입니다.
다음 pip 명령어를 사용하여 PyPI에서 Spire.PDF for Python을 설치할 수 있어요:
pip install Spire.Pdf
이미 Spire.PDF for Python을 설치 했고 최신 버전으로 업그레이드 하고 싶다면, 다음 pip 명령어를 사용해 주세요:
pip install --upgrade Spire.Pdf
더 자세한 정보를 원하시면, 이 공식 설명서를 확인하실 수 있어요: VS Code에서 Python용 Spire.PDF 설치 방법.
Python에서 PDF 이미지 추출하기
Spire.PDF for Python의 PdfImageHelper 클래스를 사용하면 PDF 파일 내 이미지를 쉽게 다룰 수 있어요.
PDF 파일에서 이미지를 가져오려면 PdfImageHelper.GetImagesInfo(page: PdfPageBase) 함수를 사용할 수 있어요. 이 함수는 PDF 페이지의 이미지를 나타내는 PdfImageInfo 객체 목록을 반환할 거예요. PdfImageInfo 객체를 얻으면 PdfImageInfo.Image.Save() 함수를 사용하여 각 이미지를 파일로 저장할 수 있어요.
아래 코드는 Python 및 Spire.PDF for Python을 사용하여 PDF 파일에서 이미지를 추출하는 방법을 보여줍니다:
from spire.pdf.common import *
from spire.pdf import *
def extract_images_from_pdf(pdf_path, output_dir):
"""
PDF 파일에서 모든 이미지를 추출하여 지정된 출력 디렉토리에 저장합니다.
Args:
pdf_path (str): PDF 파일 경로
output_dir (str): 추출된 이미지가 저장될 디렉토리
"""
# PdfDocument 객체 생성 및 PDF 파일 로드
doc = PdfDocument()
doc.LoadFromFile(pdf_path)
# PdfImageHelper 객체 생성
image_helper = PdfImageHelper()
image_count = 1
# PDF의 모든 페이지에 대해 반복
for page_index in range(doc.Pages.Count):
# 현재 페이지의 이미지 정보 가져오기
image_infos = image_helper.GetImagesInfo(doc.Pages[page_index])
# 이미지 추출 및 저장
for image_index in range(len(image_infos)):
# 이미지 가져오기
image = image_infos[image_index].Image
# 출력 파일 이름 지정
output_file = os.path.join(output_dir, f"Image-{image_count}.png")
# 이미지 저장
image.Save(output_file)
image_count += 1
# PdfDocument 객체 닫기
doc.Close()
# 사용 예시
extract_images_from_pdf("Sample.pdf", "C:/Users/Administrator/Desktop/Images")
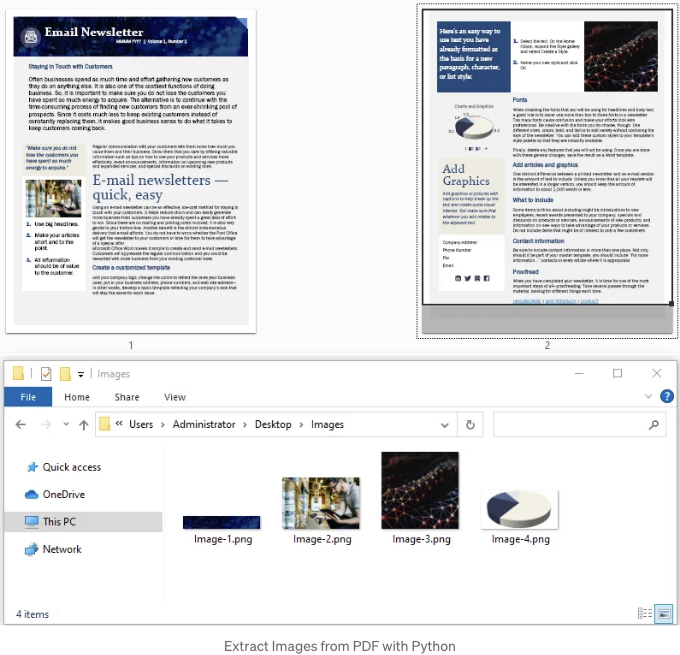
Python을 사용하여 PDF에서 이미지 정보 추출하기
PDF에서 이미지의 정보를 추출하기 위해서는 PdfImageInfo.Bounds.X, PdfImageInfo.Bounds.Y, PdfImageInfo.Bounds.Width 및 PdfImageInfo.Bounds.Height 속성을 사용할 수 있습니다.
아래 코드는 Python과 Spire.PDF for Python을 사용하여 PDF 파일에서 이미지의 위치 (x 및 y 좌표), 너비 및 높이와 같은 이미지 정보를 추출하는 방법을 보여줍니다:
from spire.pdf.common import *
from spire.pdf import *
def print_pdf_image_info(pdf_path):
"""
PDF 파일에서 이미지에 대한 정보를 출력합니다.
Args:
pdf_path (str): PDF 파일의 경로.
"""
# PdfDocument 객체를 만들고 PDF 파일을 로드합니다
doc = PdfDocument()
doc.LoadFromFile(pdf_path)
# PdfImageHelper 객체를 만듭니다
image_helper = PdfImageHelper()
# PDF의 모든 페이지를 반복합니다
for page_index in range(doc.Pages.Count):
page = doc.Pages[page_index]
# 현재 페이지에 대한 이미지 정보를 가져옵니다
image_infos = image_helper.GetImagesInfo(page)
# 이미지 정보를 출력합니다
for image_index, image_info in enumerate(image_infos):
print(f"페이지 {page_index + 1}, 이미지 {image_index + 1}:")
print(f" 이미지 위치: ({image_info.Bounds.X}, {image_info.Bounds.Y})")
print(f" 이미지 크기: {image_info.Bounds.Width} x {image_info.Bounds.Height}")
# PdfDocument 객체를 닫습니다
doc.Close()
# 사용 예
print_pdf_image_info("Sample.pdf")
결론
이 블로그 포스트에서는 Python을 사용하여 PDF 파일에서 이미지를 추출하는 방법을 보여주었습니다. 또한 Python을 사용하여 PDF 파일에서 이미지의 위치 (x 및 y 좌표), 너비 및 높이와 같은 이미지와 관련된 세부 정보를 추출하는 방법도 설명되었습니다.
관련 주제
- Python을 사용하여 PDF에서 텍스트 읽거나 추출하기 — 포괄적인 안내서
- Python을 사용하여 PDF 테이블을 텍스트, Excel 및 CSV로 추출하기
- Python을 사용하여 PDF 양식 데이터 추출하기
- Python을 사용하여 PDF를 압축하거나 파일 크기 줄이는 5가지 방법
- Python을 사용하여 PDF 파일 자르기 방법