프로젝트 개요
이 프로젝트는 Apache Airflow와 Amazon S3를 사용하여 end-to-end ETL (추출, 변환, 로드) 파이프라인을 개발하는 데 중점을 둡니다.
이 파이프라인은 OpenWeather API에서 날씨 데이터를 검색하여 구조화된 형식으로 변환하고 S3 버킷에로드합니다. 이 프로젝트를 완료하면 희망하는 빈도로 예약된 파이프라인을 실행할 수 있는 완전히 기능하는 파이프라인을 보유하게 됩니다.
프로젝트 구조
- 날씨 데이터 가져오기: OpenWeather API에서 날씨 데이터를 가져옵니다.
- 날씨 데이터 변환: API에서 가져온 데이터는 JSON 형식이며, 변환 작업은 JSON 개체에서 데이터프레임을 만들고 데이터프레임을 CSV 파일로 변환하는 작업을 포함합니다.
- S3에 데이터로드: 변환된 데이터를 S3 버킷에 저장합니다.
사전 준비 및 사용된 도구
- Apache Airflow: 워크플로우를 프로그래밍 방식으로 작성, 예약, 모니터링할 수 있는 강력하고 유연한 플랫폼입니다.
- OpenWeather API: 여러 도시의 날씨 데이터를 제공하는 서비스입니다.
- Amazon S3: Amazon Web Services (AWS)의 확장 가능한 객체 스토리지 서비스입니다.
- Pandas: 데이터 조작 및 분석을 위해 사용되는 Python 라이브러리입니다.
- Boto3: Python 개발자가 S3와 같은 Amazon 서비스를 활용하는 소프트웨어를 작성할 수 있게 해주는 AWS SDK for Python입니다.
- DAG 파일: Apache Airflow에서 작업 및 종속성을 정의하는 작업열로서 사용되는 중요한 개념인 Directed Acyclic Graph(DAG) 파일입니다.
구현
- API와 연결하여 데이터를 가져오는 DAG 스크립트를 작성하세요. 데이터는 데이터프레임에 저장됩니다. DAG 코드는 이 페이지의 맨 아래에서 찾을 수 있습니다.
- EC2 인스턴스를 생성하고 인스턴스를 시작하여 콘솔에 연결하세요. 저는 무료티어 AWS를 사용하여 이 인스턴스를 생성했습니다. 사양은 t2.micro 및 우분투 22 버전입니다.
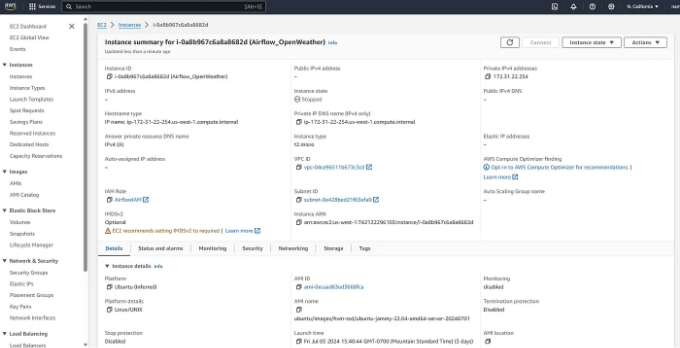
인스턴스가 실행되면 콘솔에 연결하여 다음을 설치하세요.
sudo apt-get update
sudo install python3-pip
sudo pip install requests pandas boto3 s3fs pyarrow apache-airflow
- 한 번 설치되면, Airflow가 올바르게 설치되었는지 확인하세요. airflow 명령어를 사용하여 확인하고 초기 로그인 자격 증명을 위해 스탠드얼론 명령어를 실행하십시오. 자격 증명을 복사하여 나중에 사용하세요.
airflow
airflow standalone
-
실행 중인 인스턴스에서 보안으로 이동하여 보안 그룹에 액세스하세요. 인바운드 규칙을 편집하고 새 역할을 생성하세요. "모든 트래픽", "IPv4 어디서나"로 설정하세요.
-
Airflow 서버와 스케줄러를 시작하세요.
에어플로우 스케줄러 및 에어플로우 웹서버 - 포트 8080
6. 공개 IP 주소를 복사하고 포트를 추가하세요. 예: 172.31.22.254:8080. 이로써 에어플로우 어플리케이션을 열 수 있습니다. 기본 자격 증명을 사용하여 로그인하고 마음에 드는 비밀번호로 재설정하세요.
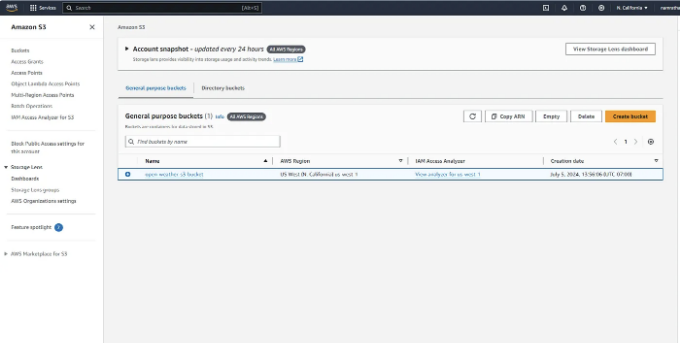
7. AWS에서 데이터를 저장할 S3 버킷을 만드세요. IAM 역할을 사용하여 권한을 조정하세요. 새 IAM 역할을 만들고 S3 및 EC2에 권한을 부여하세요.
8. DAG 파일에 관련 있는 S3 버킷 이름을 추가하고 저장하세요.
- 인스턴스 콘솔에서 서버를 중지하고 명령을 실행하세요. 이렇게 하면 airflow의 DAGs 폴더에 액세스할 수 있어요. 원하는 경우 DAG 파일을 추가하고 필요할 때 수정할 수 있어요.
airflow
cd airflow
ls
sudo nano airflow.cfg
DAGs 폴더에서 파일 이름을 조정하세요. 수정된 버퍼를 저장하고 종료하세요.
- 파일을 저장한 후 airflow 명령을 다시 실행하고 로그인하세요. 그러면 airflow 내에서 Dag 파일을 볼 수 있어요. 보이는 형태는 이렇습니다:
아래는 Markdown 형식으로 변경된 테이블입니다.
- 파일을 열어서 수동으로 실행할 수 있어야 합니다. Airflow의 내장 그래프 기능을 사용하여 DAG 파일의 상태를 모니터링할 수 있습니다. 초록 테두리는 성공적인 실행을 나타냅니다.
- 실행이 성공하면 데이터가 S3 버킷에 표시됩니다.
DAG 파일과 설명:
from datetime import datetime, timedelta
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
import requests
import pandas as pd
import boto3
from io import StringIO
# Configuration
API_KEY = 'xxxxxxxxxxxxxxxxxxxxxxxxxxx' # OpenWeather의 API 키
CITY = 'Arizona' # 날씨 데이터를 가져올 도시
S3_BUCKET = 'open-weather-s3-bucket' # 데이터가 저장될 S3 버킷 이름
S3_KEY = 'weather_data/weather.csv' # S3 오브젝트 키 (버킷 내 파일 경로)
# DAG를 위한 기본 인수
default_args = {
'owner': 'airflow', # DAG 소유자
'depends_on_past': False, # 작업 인스턴스는 과거 실행에 의존하지 않음
'start_date': datetime(2024, 7, 5), # DAG 시작 날짜
'email_on_failure': False, # 실패 시 이메일 알림 비활성화
'email_on_retry': False, # 재시도 시 이메일 알림 비활성화
'retries': 1, # 실패 시 재시도 횟수
'retry_delay': timedelta(minutes=5), # 재시도 간의 지연
}
# 스케줄러가 없는 DAG 정의
dag = DAG(
'OpenWeather_to_s3',
default_args=default_args,
description='날씨 데이터를 가져와 변환한 후 S3로 로드합니다.',
schedule_interval=None, # schedule_interval을 None으로 설정하여 스케줄러 비활성화
)
def fetch_weather_data():
"""OpenWeather API에서 날씨 데이터 가져오기"""
url = f"http://api.openweathermap.org/data/2.5/weather?q={CITY}&appid={API_KEY}" # 도시와 API 키를 포함한 API 엔드포인트
response = requests.get(url) # API에 GET 요청 보내기
data = response.json() # 응답을 JSON으로 변환
return data # 데이터 반환
def transform_weather_data(**kwargs):
"""가져온 날씨 데이터 변환하기"""
ti = kwargs['ti'] # 작업 인스턴스 가져오기
data = ti.xcom_pull(task_ids='fetch_weather_data') # XCom을 사용하여 'fetch_weather_data' 작업에서 데이터 가져오기
weather = {
'city': data['name'], # 도시 이름 추출
'temperature': data['main']['temp'], # 온도 추출
'pressure': data['main']['pressure'], # 기압 추출
'humidity': data['main']['humidity'], # 습도 추출
'weather': data['weather'][0]['description'], # 날씨 설명 추출
'wind_speed': data['wind']['speed'], # 풍속 추출
'date': datetime.utcfromtimestamp(data['dt']).strftime('%Y-%m-%d %H:%M:%S') # 타임스탬프를 읽기 가능한 날짜로 변환
}
df = pd.DataFrame([weather]) # 날씨 데이터를 판다스 DataFrame으로 변환
return df # DataFrame 반환
def load_data_to_s3(**kwargs):
"""변환된 데이터를 S3 버킷에 로드하기"""
ti = kwargs['ti'] # 작업 인스턴스 가져오기
df = ti.xcom_pull(task_ids='transform_weather_data') # XCom을 사용하여 'transform_weather_data' 작업에서 변환된 데이터 가져오기
csv_buffer = StringIO() # 인메모리 버퍼 생성
df.to_csv(csv_buffer, index=False) # DataFrame을 CSV로 버퍼에 작성
print(df) # DataFrame 출력 (선택 사항)
s3_resource = boto3.resource('s3') # boto3 S3 리소스 생성
s3_resource.Object(S3_BUCKET, S3_KEY).put(Body=csv_buffer.getvalue()) # CSV 데이터를 지정한 S3 버킷 및 키에 업로드
# PythonOperator를 사용하여 작업 정의
fetch_task = PythonOperator(
task_id='fetch_weather_data', # 작업 ID
python_callable=fetch_weather_data, # 호출 가능한 함수
dag=dag, # 작업이 속한 DAG
)
transform_task = PythonOperator(
task_id='transform_weather_data', # 작업 ID
python_callable=transform_weather_data, # 호출 가능한 함수
provide_context=True, # 호출 가능한 함수에 컨텍스트 제공
dag=dag, # 작업이 속한 DAG
)
load_task = PythonOperator(
task_id='load_data_to_s3', # 작업 ID
python_callable=load_data_to_s3, # 호출 가능한 함수
provide_context=True, # 호출 가능한 함수에 컨텍스트 제공
dag=dag, # 작업이 속한 DAG
)
# 작업 간 의존성 정의 (작업 실행 순서)
fetch_task >> transform_task >> load_task # 작업 실행 순서 설정: 가져오기 -> 변환 -> 로드
설명:
-
Imports 및 구성: 필요한 라이브러리를 import하고 구성 변수를 설정합니다.
-
기본 인수: DAG의 기본 인수를 정의합니다. 예를 들어, 소유자, 시작 날짜, 재시도 정책 등이 포함됩니다.
-
DAG 정의: DAG 개체를 설명과 일정 간격으로 생성합니다 (일정을 비활성화하려면 None으로 설정 가능합니다).
-
작업 함수: 사용할 Python 함수를 작업으로 정의합니다.
-
fetch_weather_data: OpenWeather API에서 날씨 데이터를 가져옵니다.
-
transform_weather_data: 가져온 데이터를 Pandas DataFrame으로 변환합니다.
-
load_data_to_s3: 변환된 데이터를 S3 버킷에 로드합니다.
- 작업 생성: PythonOperator를 사용하여 정의된 함수를 호출하는 작업을 생성합니다.
- 종속성 설정: 비트 시프트 연산자를 사용하여 작업을 실행할 순서를 정의하세요.