거래 결정 도구

맞춤 지수는 자산 구성 및 가중치에 대한 유연성과 제어를 제공하여 전통적인 지수와 비교했을 때 투자 전략을 더 잘 반영할 수 있는 고유한 기준을 제공합니다. 이 기사에서는 Python을 사용하여 맞춤 지수를 작성하는 방법을 안내하겠습니다.
왜 맞춤 지수를 사용해야 하나요?
- 유연성: 특정 투자 또는 거래 전략에 맞게 지수를 맞춤 설정할 수 있습니다.
- 통제: 자산 포함 및 가중 기준을 사용자 정의할 수 있습니다.
- 혁신: 투자 및 거래 모두에서 경쟁 우위를 제공할 수 있는 독특한 지수 개발
미국 달러 지수를 계산하는 이유
역사적 가격을 찾을 수 있는 모든 것에 대해 사용자 정의 지수를 만들 수 있지만, 이 글은 이미 존재하는 지수인 미국 달러 지수를 만들 것입니다.
제가 미국 달러(USD)를 선택한 이유는 우리가 사용자 정의 결과를 실제 지수와 비교하여 테스트할 수 있기 때문입니다.
제 2로 가장 중요한 건 통화를 선택했습니다. 외환 거래에서 외환 페어를 거래할 때 한 통화가 다른 통화와 비교됨을 볼 수 있습니다. 실제로 페어가 길어지면, 예를 들어 EURUSD가 있습니다. EUR이 강해지고 있는지, USD가 약해지고 있는지 확신할 수 없습니다. 이것은 통화 지수로만 제공될 수 있는 답변입니다.
사용자 정의 인덱스 생성 단계별 안내서
통화 데이터 처리 및 금융 데이터 가져오기를 위해 pandas, numpy 및 yfinance와 같은 필수 라이브러리를 가져와 시작합니다.
import pandas as pd
import json
import yfinance as yf
import mplfinance as mpf
그럼 해당 쌍의 딕셔너리와 내가 관심 있는 통화의 딕셔너리를 불러오세요(기사 맨 끝에 링크가 있습니다).
with open('currencies_weights.json') as f:
currencies = json.load(f)
with open('currencies_pairs.json') as f:
pairs = json.load(f)
통화는 심볼(예: EUR)과 해당 국가의 GDP(십억 달러)를 가장 중요하게 가지고 있어야 합니다. GDP를 선택한 이유는 가장 현실적인 측정값으로 보였습니다(결국 옳은 것으로 판명되었죠…). 그냥 하나의 통화로 표시되어야 한다는 점만 주의하면 됩니다. 예를 들어, 유로존 GDP는 USD로 표시되어야 하며 EUR이 아니어야 합니다. 이것이 가장 쉬운 방법인 것을 발견했는데, 로컬 통화로 GDP를 가지고 있고 이후 변환해야 하는 방법보다 편리합니다.
아래 for 루프를 사용하면 모든 쌍에 대한 1시간 가격을 다운로드하고, 우리 사랑하는 yfinance의 도움으로 이를 딕셔너리에 추가할 수 있습니다.
for pair in pairs:
pairs[pair]['df'] = yf.download(pairs[pair]['name'] + '=X', start='2023-01-01', end='2023-12-31', interval='1h')
가능한 가장 작은 시간 단위를 선택하여 데이터를 찾아야 큰 시간 단위(예: 4시간 또는 일일)의 캔들을 만들 수 있습니다. 그런 다음 야후 금융이 가끔 일부 날짜를 제공하지 않을 경우에도 데이터 프레임을 동기화합니다. API가 완전하고 적절한 데이터를 제공할 것이라고 확신하는 경우, 이 부분은 건너 뛰시기 바랍니다.
# 최소 및 최대 날짜 찾기
for pair in pairs:
mindate = min(pairs[pair]['df'].index)
maxdate = max(pairs[pair]['df'].index)
# 공통되지 않은 날짜 제외
for pair in pairs:
pairs[pair]['df'] = pairs[pair]['df'].loc[mindate:maxdate]
print(mindate, maxdate)
이제 계산할 통화의 지수와 이 통화를 포함하는 모든 통화에 대한 종가를 갖는 데이터 프레임을 생성하고 설정해야 합니다. 통화가 판매 쪽에 있다면 환율을 뒤집어서 모두 매수쪽으로 가져와야 합니다.
통화 = 'USD'
mydict = {}
# 해당 통화를 포함하는 쌍 필터링
for pair in pairs:
if 통화 in pairs[pair]['buycur']:
print("매수", pair)
mydict[pairs[pair]['sellcur']] = pairs[pair]['df']['Close']
elif 통화 in pairs[pair]['sellcur']:
print("매도", pair)
mydict[pairs[pair]['buycur']] = 1 / pairs[pair]['df']['Close']
df_currency = pd.DataFrame(mydict)
위 데이터프레임의 각 열(통화)에 대해 GDP를 사용하여 가중치 목록을 생성합니다.
weights = []
for col in df_currency.columns:
weights.append(currencies[col]['GDP'])
weights = [weight / sum(weights) for weight in weights]
이제 가중 폐장 가격을 생성하고 선택한 데이터프레임으로 재샘플링하는 마법이 일어납니다(원본보다 더 높아야 함).
# 데이터프레임 준비
df_index = df_currency.copy()
df_index = df_index.pct_change(fill_method=None)
df_index.dropna(inplace=True)
# 가중 평균 종가 계산
weights_df = pd.DataFrame(weights, index=df_index.columns, columns=['Weight'])
df_index[currency] = df_index.dot(weights_df['Weight']).cumsum(axis=0)*1000
df_index[currency] = df_index[currency].round(6)
# 인덱스를 일별로 다시 샘플링
df_index = df_index[currency].dropna()
ohlc = df_index.resample('D').ohlc()
ohlc.dropna(inplace=True)
여기까지입니다. ohlc 데이터프레임에는 일별 미국 달러 지수의 캔들 정보가 포함되어 있습니다.
과정을 확인하려면 실제 미국 달러 지수를 다운로드하여 비교해보겠습니다.
usd_dollar_index = yf.download("DX-Y.NYB", (start = "2023-01-01"), (end = "2023-12-31"), (interval = "1d"));
첫 번째 점검은 시각적으로 이루어질 것입니다. 그래서 우리가 만든 그래프와 공식 그래프를 겹쳐서 플로팅할 거에요. 멋져 보이죠?
mpf.plot(ohlc, (type = "candle"), (figratio = (30, 10)));
mpf.plot(usd_dollar_index, (type = "candle"), (figratio = (30, 10)));
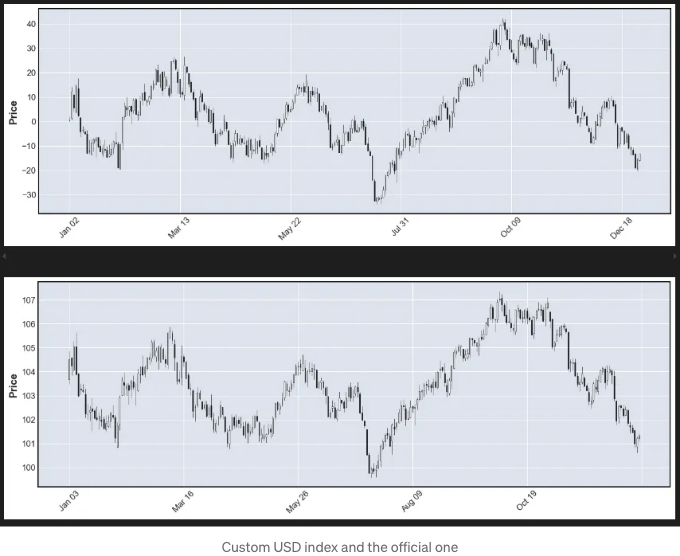
다른 방법은 종가의 상관 관계를 점검하는 것이에요.
# 먼저 상관 계수를 계산하기 전에 두 날짜 및 시간 인덱스를 시간대 정보 없이 만들어야 합니다
ohlc.index = ohlc.index.tz_localize(None)
usd_dollar_index.index = usd_dollar_index.index.tz_localize(None)
combined_df = pd.DataFrame({
'ohlc': ohlc['close'],
'usd_dollar_index': usd_dollar_index['Close']
})
correlation = combined_df.corr().iloc[0, 1]
이를 통해 우리는 놀라운 0.976의 상관 관계를 얻게 됩니다. 이를 통해 두 인덱스가 일치함을 알 수 있습니다...
하지만 미국 달러 지수는 6개 통화에 대한 고정 가중치로 계산되는 반면, 우리의 경우에는 14가 있었으므로 약간의 차이가 있습니다!
여기에서 Git Hub에서 코드와 통화 쌍에 대한 json 파일을 찾을 수 있습니다. 클릭하세요.
다음 단계
- 실험: 다양한 가중 체계와 자산 선택을 시도해보세요.
- 향상: 보다 정교한 백테스팅 지표 추가.
- 최적화: 기계 학습 모델 통합하여 사용자 정의 지수를 최적화하세요.
나의 데이터 주도 투자 여정을 함께 해보세요! 저를 Medium, Twitter (현재 X로 잘 알려진) 및 Github에서 팔로우해주세요. 저는 코딩, 글쓰기, 데이터 이해를 통한 성장을 추구합니다 ;)
면책 조항: 이 글에서 투자의 흥미로운 세계를 탐험하는 동안 교육 목적으로 제공되는 정보임을 꼭 상기해주세요. 저는 금융 자문가가 아니며 여기에 게시된 내용은 금융 조언으로 간주되지 않습니다. 언제나 연구를 하시고 투자 결정을 내리기 전에 전문가와 상의하는 것을 고려해주십시오.
쉽고 간결한 영어 커뮤니티에 참여해 주셔서 감사합니다! 떠나시기 전에:
- 반드시 저자를 clapping 하고 팔로우 해주세요 ️👏️️
- 팔로우하기: X | LinkedIn | YouTube | Discord | 뉴스레터
- 다른 플랫폼 방문하기: CoFeed | Differ
- PlainEnglish.io에서 더 많은 콘텐츠 확인하기