어느 때는 씨앗 벤처 투자 회사의 데이터 부서에서 일한 적이 있었어요. 저는 VC 펀드에서 일한 적이 있었는데, 그 중 하나는 창업가들과 그들의 비즈니스에서 제품-시장 적합성의 지표에 대해 논의하는 것이었습니다. Andrew Chen의 제품 시장 적합성에 대한 정량적 접근을 적용했었죠. 처음에 우리는 창업가들과 제품 시장 적합성의 지표에 대해 논의하고 그들의 사용자들의 원시 데이터를 요청했어요. 그런 다음 데이터를 분석해서 서로 다른 사용자들과 그들의 행동이 시간에 따라 어떻게 변하는지 파악했어요.
그 정량적 방법론에는 주로 두 가지 유형의 표현이 있습니다: 성장 회계 및 코호트 분석입니다. 창업기업에서는 원시 데이터가 보통 엉망이기 때문에 데이터를 맞추기 위해 모든 것을 다시 코딩해야 했어요. 그렇지만 몇 주 전에 옛 노트북을 먼지 털었어요. 시간이 흘러고 관점이 바뀌면서 해당 프레임워크를 일반화하고 사용하기 쉬운 Python 객체를 만들기로 결정했어요. 그렇게 하면 데이터를 정리하고 준비하는 일만 남을 거예요. 시각화는 이미 완료된 상태예요!
두 가지 객체를 코딩했어요: 성장 회계용 하나와 코호트용 하나요. 이 두 객체는 기계 학습 스타일로 구축되었기 때문에 매개변수를 설정하고 데이터로 객체를 적합시킨 다음 결과 및 시각화를 요청할 수 있어요. 제품-시장 적합성 프레임워크의 분산은 구축되지 않았는데, 단순화에는 도움이 되지 않을 것 같아요.
본 기사에서는 Spot the Lion 앱의 두 데이터셋을 사용하여 코드를 설명할 거예요. 이는 설명 목적으로 만든 가상 앱이에요. 더 많은 정보는 여기에서 확인할 수 있어요.
모든 이미지는 별도로 언급되지 않는 한 저자가 만들었습니다. 또한 제가 사용할 두 개의 데이터 세트가 있습니다. 이 유즈 케이스, 참고문헌 및 두 데이터 세트가 포함된 코드 저장소는 여기에 있습니다.
먼저 해야 할 일
간편하게 하기 위해 제품 시장 적합성을 PMF로 줄여 쓰고, PMF 단위를 측정하려는 사용자의 활동을 의미하는 것으로 부르겠습니다.
예를 들어, 앱을 사용하는 사용자의 행동을 평가하려면 PMF 단위는 총 상호작용 (사용자별)이 될 것이며, 앱의 각 상호작용을 포함하는 데이터 세트가 필요합니다. 즉, 각 행에는 사용자 및 날짜가 포함되어야 합니다. 이 유형의 PMF 단위는 간단하다고 부르는데, PMF 단위를 숫자로 측정하기 때문입니다 (상호작용의 수를 세는 것). 그래서 오브젝트는 날짜와 해당 작업을 실행한 사용자의 ID 두 개의 열만 필요합니다.
다른 PMF 유닛으로는 사용자가 소비한 금액이 될 수 있습니다. 이 경우 앱에서 모든 결제가 포함된 데이터셋이 필요합니다. 사용자, 날짜 및 수량이 포함되어야 합니다. 수량을 합산할 Quantity 열이 필요하기 때문에 이 유형의 PMF 유닛은 간단하지 않습니다.
이러한 정의는 Andrew Chen이 제시한 PMF의 양적 접근에서 프레임워크를 일반화하여 선택된 PMF 유닌과 관련된 개념을 자유롭게 다룰 수 있게 해줍니다. 성장 회계 및 코호트 두 프레임워크 모두 이러한 일반화를 활용합니다.
코드는 세 개의 파일로 구성되어 있습니다:
- aux.py: 날짜 처리 함수를 포함합니다.
- growth_accounting_pmf.py: GrowthAccounting 객체가 포함되어 있습니다.
- cohorts_pmf.py: Cohorts 객체와 일부 보조 함수가 포함되어 있습니다.
라이브러리로는 copy, datetime, numpy, pandas, matplotlib.pyplot 및 seaborn을 사용하여 구성되었어요.
import pandas as pd
import matplotlib.pyplot as plt
import datetime as dt
import numpy as np
import seaborn as sns
from growth_accounting_pmf import GrowthAccounting
from cohorts_pmf import Cohorts
이 객체의 구현과 작동 방식에 대한 모든 내용은 그들의 독스트링에 있어요. (독스트링을 좋아해서, 통찰력이 있는 독스트링을 만드는 데 많은 시간을 보냈어요! 도움이 되면 좋겠어요!).
성장 회계
성장 회계 프레임워크는 사용자를 PMF 유단위 행동으로 태깅한 다음 그 진화를 살펴보는 것을 목표로 합니다.
태그는 비즈니스에 부정적일 수 있습니다: 이탈, 축소; 비즈니스에 유리한 경우: 신규, 부활; 또는 비즈니스에 긍정적인 경우: 유지, 확장. 이러한 태그의 시간 분석을 통해 PMF 유단위의 행동을 이해할 수 있습니다. 이 분석은 B2B 또는 계약 비즈니스의 수익을 위한 것이 일반적이지만, 일반화를 통해 앱의 모든 작업에 대한 진화를 분석하는 데도 사용할 수 있습니다.
GrowthAccounting은 두 개의 매개변수로 구성되어 있습니다:
- period: 'Q', 'q', 'M', 'm', '28D', '28d', '7D', '7d', 'D', 'd' 중 하나입니다. 데이터를 분할할 기간을 나타내는 문자입니다. 기본값: 월간.
- simple: bool. PMF 유닛이 간단한지 여부를 나타내는 불리언 값이며, 이는 상호 작용을 단순히 계산해야 하는지(simple) 아니면 수량 열이 필요한지(not simple) 여부를 말합니다. 기본값: simple.
그럼 데이터를 담고 있는 객체를 맞춰야 해요:
- data: 각 행이 PMF 유당의 작업을 나타내는 판다스 데이터프레임입니다. 적어도 사용자 ID를 나타내는 열과 작업 날짜를 나타내는 다른 열이 있어야 합니다. 간단한 PMF 유당이 아닌 경우 양을 나타내는 열이 하나 더 필요합니다.
- column_date: 문자열. 데이터에서 날짜를 나타내는 열의 이름입니다. 날짜 형식이어야 합니다.
- column_id: 문자열. 데이터에서 사용자 ID를 나타내는 열의 이름입니다.
- column_input: 문자열. 데이터에서 양을 나타내는 열의 이름입니다. 기본값은 없습니다.
데이터로 맞춘 후에 객체는 (주어진 PMF 유당 및 기간에 대해) 새로운, 총계, 부활, 확장, 축소, 유지 및 탈당 사용자를 계산합니다. 또한 이러한 특성의 비율, 성장률, 총 보유율, 빠른 비율 및 순 탈당도를 계산합니다.
객체를 맞춘 후에는 데이터 및 시각화를 요청하기만 하면 됩니다:
- df: 판다 데이터프레임입니다. 위에서 계산한 모든 열이 포함되어 있습니다.
- plot: Accounting for Growth 시각화를 플롯합니다.
- plot_compound_growth(period): 복리 성장을 계산하기 위해 기간이 필요하며 그 후 시각화를 플롯합니다.
알겠습니다. 이 방법이 조금 어려운 것 같네요. 두 가지 예제를 살펴보겠습니다.
간단한 PMF 단위의 Accounting for Growth 예시: 총 사용자 상호 작용
spot_the_lion_user_activity_2023.csv 데이터 세트를 사용하겠습니다.
import pandas as pd
activity = pd.read_csv('spot_the_lion_user_activity_2023.csv')
activity['date'] = pd.to_datetime(activity['date'])
activity.head()
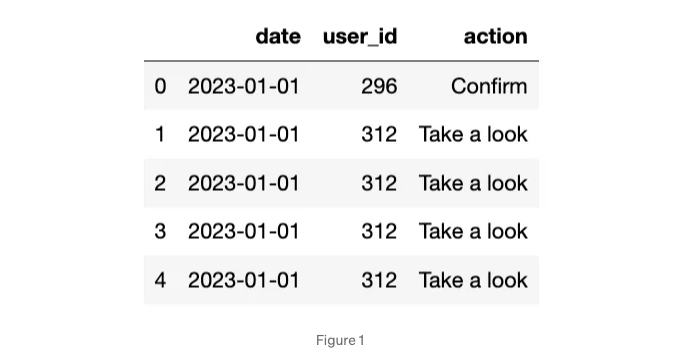
We have three columns: date, user_id, and action. However, to count total interactions, we only need the date and the user_id. Also, we choose a monthly period.
user_growth = GrowthAccounting(period='M')
user_growth.fit(activity, 'date', 'user_id')
적절한 시간은 데이터 양에 따라 다릅니다. 그럼 데이터프레임을 확인할 수 있습니다 (테이블 전체를 보려면 Jupyter Notebook으로 이동하세요).
user_growth.df;
이제 그래프를 그릴 수 있습니다.
user_growth.plot();
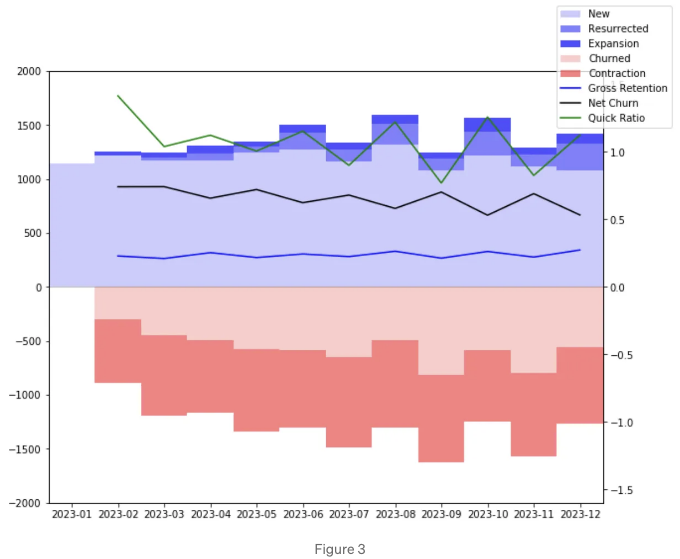
user_growth.plot_compound_growth(3);
그게 다에요!
단순하지 않은 PMF 단위의 성장 고려: 사용자별 수익
이 경우, 앱 내 각 지불을 포함하는 다른 데이터셋을 사용할 것입니다. 이 데이터셋은 spot_the_lion_revenue_2023.csv입니다.
revenue=pd.read_csv('spot_the_lion_revenue_2023.csv')
revenue['date']=pd.to_datetime(revenue['date'])
revenue.head()
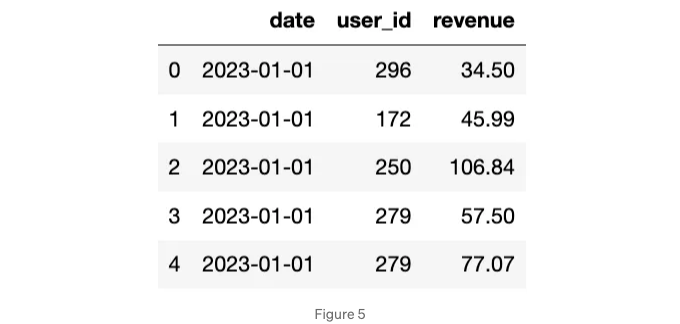
여기에는 세 개의 열이 있으며 모두 필요합니다: date, user_id 및 revenue. 또한, 이 분석이 매월 이루어지고 간단하지 않다고 지정해야 합니다.
rev_growth = GrowthAccounting((period = "M"), (simple = False));
rev_growth.fit(revenue, "date", "user_id", "revenue");
한번 그려보세요.
rev_growth.plot();
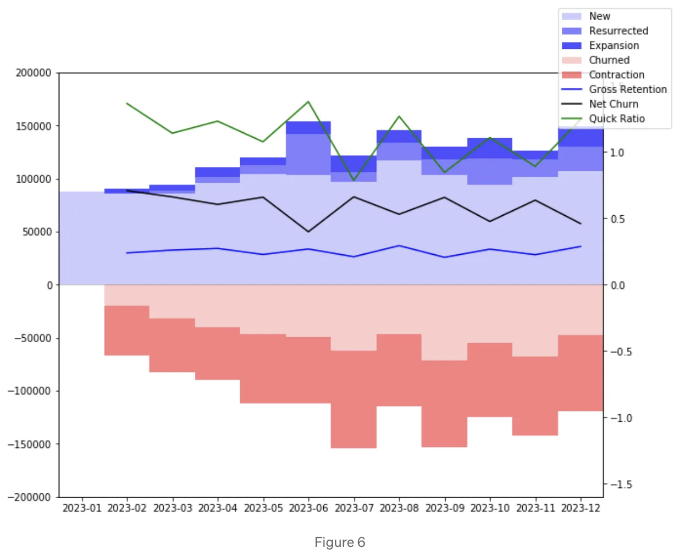
rev_growth.plot_compound_growth(3);
이것들은 기본 분석입니다. 그러나 선택한 PMF 단위(및 데이터 품질에 따라)에 따라 다양한 정보를 얻을 수 있습니다. 이 예시에서는 앱에서 사자를 확인한 사용자들을 대상으로 성장 회계(Growth Accounting)를 살펴볼 수 있습니다 (모든 상호작용이 아닌). 또한 데이터 세트를 id로 병합하고 앱과 두 번 상호작용하는 사용자별로 세분화된 수익을 찾을 수도 있습니다 (모르겠지만, 이제 당신의 차례입니다!).
만약 여전히 이 차트들이 무엇인지 모르거나 축소, 확장, 이탈 등을 들어본 적이 없다면... 시간을 낭비하지 말고 먼저 Andrew Chen의 Quantitative Approach to Product Market Fit를 읽으세요!
코호트(Cohorts)
Cohort Framework은 제품과 상호 작용하기 시작한 시점에 따라 사용자를 그룹화한 후 시간에 따른 PMF 단위의 진화를 볼 수 있는 목표를 가지고 있어요.
많은 사람들이 코호트 분석이 복잡하다고 생각하는데요. 이 기회를 주시면 좋겠어요. 코호트 분석을 통해 사용자들의 PMF 단위의 진화를 병행 분석할 수 있어요. 제품 코호트가 20% 감소한다면 참여도가 없다는 것이라고 하더라고요! 사용자를 잃고 있는 거예요!
코호트 객체는 두 개의 매개변수로도 구축됩니다:
- 기간: '‘Q’, ’q’, ’M’, ’m’, ’28D’, ’28d’, ’7D’, ’7d’, ’D’, ’d’'. 데이터를 나눌 기간을 나타내는 문자입니다. 기본값: 월별.
- 간단함: 부울. PMF 단위가 간단한지 여부를 나타내며, 상호 작용을 단순히 계산해야하는지 (간단) 또는 값을 합산해야하는 열이 필요한지 (복잡하지 않음)를 나타냅니다. 기본값: 간단함.
그러면 Accounting for Growth와 동일한 내용을 포함하도록 데이터가 있는 객체를 맞춰야 합니다. 다만, 종류가 있는 코호트를 명시해야 합니다.
- data: 각 행이 PMU 단위의 작업을 나타내는 판다 데이터프레임. 적어도 사용자 ID를 나타내는 열과 날짜를 나타내는 열이 있어야 합니다. 간단한 PMF 단위가 아닌 경우, 수량을 나타내는 열도 필요합니다.
- column_date: 문자열. 데이터에서 날짜를 나타내는 열의 이름. 날짜 형식은 datetime이어야 합니다.
- column_id: 문자열. 데이터에서 사용자 ID를 나타내는 열의 이름.
- column_input: 문자열. 데이터에서 수량을 나타내는 열의 이름. 기본값은 없음입니다.
- how: 문자열 목록. '‘total’, ’churn_total’, ’unique_users’, ‘churn_unique_users’, ’accum’, ‘per_user’ 중 하나 이상을 포함해야 합니다. 'Total'은 코호트의 모든 PMF 단위를 계산하는 것을 의미합니다. 'Churn total'은 Total의 음수입니다. 'Unique users'는 제품과 상호작용하는 모든 고유 사용자 수를 계산하는 것을 의미합니다. 'Churn unique users'는 Unique users의 음수입니다. 'Accum'은 시간에 따라 누적 PMF 단위를 계산합니다. 수명 가치에 사용하기 위해 고안되었습니다. 'Per user'는 사용자별로 PMF 단위의 평균을 계산합니다.
객체를 맞춘 후 코호트를 시각화하기 위해 계산된 모든 값이 있습니다. 두 가지 클래식 시각화가 있습니다: 숫자로만 표시되는 것과 백분율로 표시되는 것입니다. 따라서 how 매개변수에 지정된 값은 숫자와 백분율 둘 다 계산됩니다.
그럼 이제 데이터와 시각화를 요청하기만 하면 됩니다:
- df_cohorts: 데이터프레임. 코호트를 시각화하는 데 필요한 모든 열을 포함합니다.
- plot_heatmap(label, title, way): 일반적인 코호트 히트맵을 그립니다. 열과 차트 제목, 방법이 필요합니다. 방법은 "period" 또는 "period_num"일 수 있습니다. "period"의 경우 코호트를 기간에 맞추고, "period_num"의 경우 모든 코호트의 첫 번째 기간을 정렬한 후 두 번째, 그리고 그 이후로 이어집니다.
- plot_trend(label, title, way): 각 코호트에 대한 선 그래프를 그립니다. 히트맵과 동일한 매개변수를 사용합니다.
알겠어요, 알겠어요. 예제 없이는 모두 조금 어렵죠. 하지만 진행하기 전에, PMF 유닛의 다양성을 측정하고 싶다면 자체 유형의 코호트를 생성하는 함수도 만들었어요.
- apply_personalized(df_cohorts, column_label): "df_cohorts"는 self.df_cohorts와 동일한 구조를 가진 데이터프레임입니다. "기간"과 "코호트"를 위한 열이 있어야 합니다. 그런 다음 새로운 코호트의 "column_label"입니다.
두 가지 예제를 살펴보겠습니다.
간단한 PMF 단위의 사용자 상호 작용을 위한 코호트
우리는 데이터 집합 spot_the_lion_user_activity_2023.csv을 다시 사용할 것입니다.
activity = pd.read_csv("spot_the_lion_user_activity_2023.csv");
activity["date"] = pd.to_datetime(activity["date"]);
본 분석에서는 월 단위로 기간을 설정하고 "accum" 이외의 모든 코호트 유형과 맞출 것입니다.
users_cohort=Cohorts(period='M')
users_cohort.fit(activity,'date','user_id',how=['total','churn_total','unique_users','churn_unique_users','per_user'])
The dataframe generated is as follows.
users_cohort.df_cohorts.head()
Here, you can see that every column has a “perc” column with the percentage. Now, we can plot two heatmaps and a trend chart for every type of cohort.
총 상호 작용.
users_cohort.plot_heatmap("total", "총 상호 작용", (way = "period"));
users_cohort.plot_heatmap("perc_total", "총 상호 작용", (way = "period_num"));
users_cohort.plot_trends("perc_total", "활동 유지", (way = "period_num"));
고유 사용자.
users_cohort.plot_heatmap("unique_users", "사용자", (way = "period"));
users_cohort.plot_heatmap("perc_unique_users", "사용자", (way = "period_num"));
users_cohort.plot_trends("perc_unique_users", "로고 유지", (way = "period_num"));
사용자 이탈.
users_cohort.plot_heatmap("churn_unique", "사용자 이탈", (way = "period"));
users_cohort.plot_heatmap("perc_churn_unique", "사용자 이탈", (way = "period_num"));
사용자별 상호작용.
users_cohort.plot_heatmap("per_user", "월별 사용자별 상호작용", (way = "period"));
users_cohort.plot_heatmap("perc_per_user", "월별 사용자별 상호작용", (way = "period_num"));
위에서 보듯이 나는 일반 숫자 코호트에는 period 방식을 항상 사용하고 백분율에는 period_num 방식을 사용합니다. 또한 트렌드에 대해서는 일반적으로 백분율과 period_num 방식을 사용합니다. 다른 시각화 방법을 시도해볼 수도 있지만, 그것들은 실제로 통찰력이 부족한 것 같아요.
우리만의 메트릭을 준비해봅시다: 다양성.
먼저, 호환되는 데이터셋을 준비해야합니다.
new_df = users_cohort.df_period_cohort;
new_df["cohort"] = pd.to_datetime(new_df["cohort"]);
new_df["period"] = pd.to_datetime(new_df["period"]);
new_df = new_df
.groupby(["cohort", "period", "user_id"])
[["action"]].nunique()
.rename((columns = { action: "variety" }));
new_df = new_df.reset_index().groupby(["cohort", "period"])[["variety"]].mean().reset_index();
new_df.head();
그러면 이제 코호트를 적용하고 시각화할 수 있어요.
users_cohort.apply_personalized(new_df, "variety");
users_cohort.plot_heatmap("variety", "사용자별 상호작용 다양성", (way = "period"));
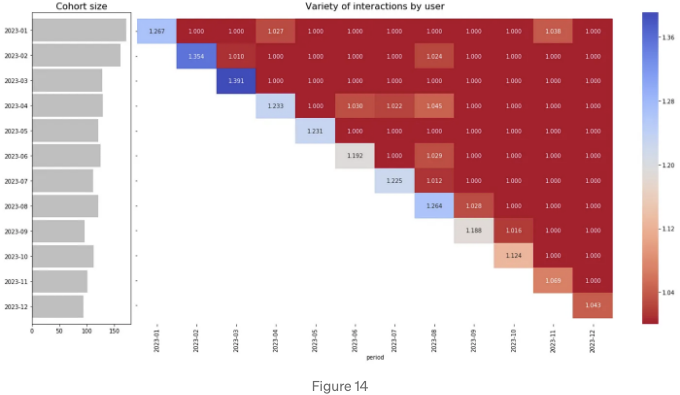
소득에 대한 비닝심플 PMF 유닛의 코호트
우리는 spot_the_lion_revenue_2023.csv 데이터셋을 사용할 것입니다.
revenue=pd.read_csv('spot_the_lion_revenue_2023.csv')
revenue['date']=pd.to_datetime(revenue['date'])
이 분석에서 우리는 월간 기간과 단순하지 않은 매개변수를 사용할 것입니다. 그런 다음 "unique_users"를 제외한 모든 코호트 유형과 적합합니다.
revenue_cohort=Cohorts(period='M',simple=False)
revenue_cohort.fit(revenue,'date','user_id','revenue',how=['total','churn_total','accum','per_user'])
이제 각각의 코호트 유형에 대해 두 개의 히트맵과 추이 차트를 그릴 수 있습니다.
총 수익.
revenue_cohort.plot_heatmap('total','총 수익','way='period')
revenue_cohort.plot_heatmap('perc_total','총 수익','way='period_num')
revenue_cohort.plot_trends('perc_total','수익 유지율','way='period_num')
한 명당 수익.
revenue_cohort.plot_heatmap("per_user", "한 명당 수익", (way = "period"));
revenue_cohort.plot_heatmap("perc_per_user", "한 명당 수익", (way = "period_num"));
코호트별 수명 가치.
revenue_cohort.plot_heatmap("accum", "코호트 LTV", (way = "period"));
revenue_cohort.plot_trends("accum", "코호트 LTV", (way = "period_num"));
revenue_cohort.plot_trends("accum", "코호트 LTV", (way = "age"));
이 경우의 마지막 차트는 조금 특별합니다. 연령대별로 플롯을 그릴 때는 각 날짜별 코호트의 주기 수에 따라 그룹화됩니다. 파란 선은 앱에서의 코호트의 첫 번째 기간에 누적된 총계를 나타냅니다. 주황색 선은 코호트가 두 번째 기간에 누적한 총계를 나타내고... 이어서 나갑니다.
개요
스타트업에서 제품-마켓 적합성을 평가하는 것은 쉬운 일이 아닙니다. 몇 년 전에 투자가인 앤드류 첸은 사용자 행동을 더 잘 이해하기 위해 사용할 수 있는 양적 접근 방식을 제안했습니다. 그는 대부분 B2B 스타트업의 매출을 사용했지만, 어떤 유형의 스타트업에도 일반화될 수 있다고 생각합니다. 최적 지표를 선택하기만 하면 됩니다.
제품-마켓 적합성은 여러분의 앱에서 실제로 사용자들이 여러분의 앱을 사용한다는 것을 의미합니다. 레시피 공유를 위한 C2C 마켓플레이스인 경우 사용자별 상호작용이 많을수록 기울어지게 됩니다. 업로드된 레시피, 댓글이 달린 레시피, 공유된 레시피 등이 지표가 될 수 있습니다. 이를 PMF(제품-마켓 적합성) 단위라고 부르며, 저가 구축한 Python 객체로 평가할 수 있습니다.
파이썬을 선택한 이유는 주피터 노트북과 그의 다양성 때문이에요. 머신러닝 스타일로 만들어져서 데이터를 맞추고 결과와 시각화를 요청하기만 하면 되기 때문이죠. 위의 예시가 프레임워크를 더 잘 이해하도록 도움이 되기를 바라요.
의견을 남겨주세요. 유용하게 사용하고 있는지 저에게 말씀해주세요. 개선에 열정적으로 참여하겠어요!
진행할 단계
- Andrew Chen의 제품 시장 적합성에 대한 정량적 접근서를 읽어보세요.
- 제 깃허브에서 코드를 다운로드하세요.
- 주피터 노트북의 사용 사례를 실험해보세요.
- PMF(unit)를 결정하고 데이터셋을 준비하여 자신의 목적에 활용하세요!
마크다운 형식으로 테이블 태그를 변경해보세요! ;)