Transformer 아키텍처의 소개로 자연어 처리에서 중요한 전환점이 시작되었습니다. 많은 주요 언어 모델이 지금은 이를 주요 아키텍처로 사용하고 있어요. 우리가 알다시피 큰 언어 모델(LLM)은 우리 삶을 더 쉽게 만들어줍니다.
LLM 모델의 크기를 생각해보세요. GPT-3은 1750억 개의 파라미터를 가지고 있고, 각각 16비트(2바이트)의 크기를 가지고 있어요. 약 350GB의 저장 공간이 필요합니다. 다른 모델들 중에는 1조를 초과하는 파라미터 크기가 있는 것도 많아요. 그래서 계산량이 매우 많습니다. 로컬에서 실행하는 것을 상상하기도 어렵죠.
하지만, 이 기사는 모두 Ollama 프레임워크에 관한 것입니다. 이를 사용하여 대규모 언어 모델을 로컬에서 실행할 수 있어요.
Ollama는 Llama 3, Mistral 등 다양한 대규모 언어 모델을 운영할 수 있게 해주는 오픈 소스 플랫폼입니다. 또한 애플리케이션에 맞게 모델을 사용자 정의하고, 쉽게 제품에 배포하는 것까지 가능하도록 해줘요.
여기서는 다른 모델들을 실행하는 유사한 프로세스를 따라 우리의 로컬 시스템에서 Llama3 모델 실행에 초점을 맞춥니다.
Ollama는 Windows, Linux 및 macOS와 호환됩니다. 다운로드하기 위해 아래 링크를 사용하십시오.
Mac: https://ollama.com/download/mac
Linux: https://ollama.com/download/linux
Windows: https://ollama.com/download/windows
Let’s try LLama 3:
- Refer to the article link: https://ollama.com/library/llama3:8b. It has all the information about the model size, variants, benchmark, and API information.
먼저 컴퓨터의 명령 프롬프트에 "ollama --version"을 입력하여 설정이 올바르게 되어 있는지 확인하십시오.

Llama 3 다운로드 :
채팅/대화 사례 모델을 다운로드하려면 "ollama pull llama3" 명령을 사용하십시오.
다른 모델 목록은 여기에서 확인할 수 있어요: https://ollama.com/library. 동일한 명령어를 사용하여 다른 모델을 가져와서 사용할 수 있어요.

Llama 3 실행:
“llama run llama3” 명령을 사용하여 모델을 직접 실행할 수 있어요.
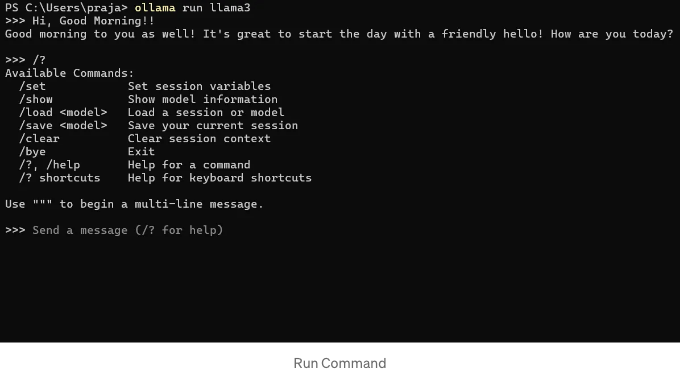
API 사용 방법:
만약 동일한 모델을 위해 API를 사용하고 싶다면, 몇 가지 간단한 단계를 따라주세요.
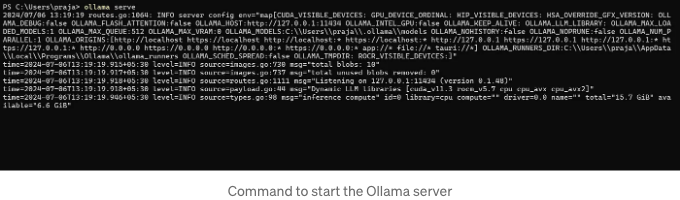
- "ollama serve"를 사용하여 로컬 서버를 시작하세요.
- 이제 "curl"이나 다른 코드를 사용하여 요청을 보낼 수 있습니다. 여기서는 Postman 도구를 사용하여 llama3 모델에 요청했습니다.
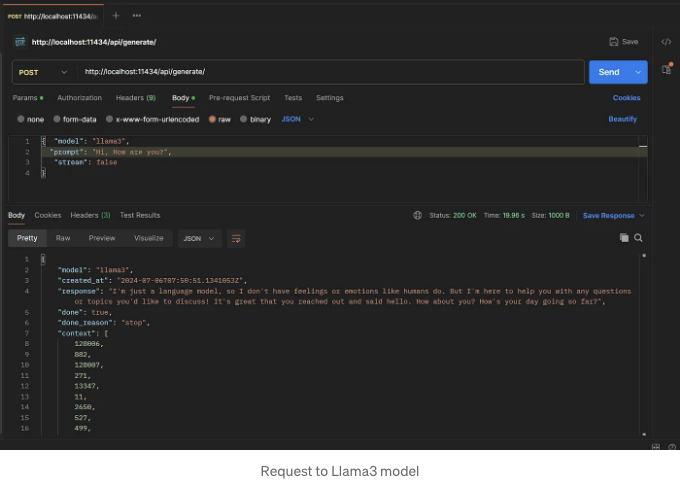
- 이 요청과 함께 전달할 수 있는 다른 매개변수도 있습니다. 자세한 API를 탐색할 수 있는 링크는 아래에 있습니다.
API 문서: https://github.com/ollama/ollama/blob/main/docs/api.md
유용한 링크: