제가 말한 블로그 시리즈의 첫 부분을 아직 확인하지 않으셨다면 확인해주세요. 이것은 필수는 아니지만 일부 맥락을 제공합니다.
소개 - PictoPy
PictoPy는 디지털 사진의 처리 방식을 혁신적으로 바꿔주기 위해 설계된 현대적인 데스크탑 앱입니다. 이 앱은 사물, 얼굴 또는 장면을 기반으로 한 사진에 대한 스마트 태깅 기능을 제공하여 효율적인 갤러리 관리를 용이하게 해줍니다.
이 프로젝트는 AOSSIE에 의해 발표되었으며 처음부터 구현되기로 했습니다. 이는 Google 사진과 유사하게 객체 감지 및 얼굴 유사성과 같은 기능을 제공합니다.
배경
GSoC 이전에 프로젝트에 몇 개의 Pull Request를 이미 제출했습니다. 우리가 무엇을 하려고 하는지 이해하려 머리를 쥐어뜯았습니다. 이 Pull Request에는 주로 Google Colab에서 다양한 유형의 모델을 테스트하고 마지막으로 출력을 제공하고 추론 속도를 벤치마킹하는 것이 포함되었습니다.
당시, 물체 탐지 및 얼굴 탐지를 위해 다양한 모델을 탐구했습니다. 우리가 시도한 첫 번째 모델은 Ultralytics의 YOLOv8 모델이었습니다. 이 모델은 훌륭한 추론 속도와 많은 온라인 자습서를 가지고 있어서 바로 이것을 사용할 수 있을 것이라는 것이 명백했습니다. 이 프로젝트는 처음부터 만들어지고 있기 때문에 시작할 때 모든 것을 결정하고 확정하기가 매우 어렵습니다.
그러나 얼굴 탐지 및 인식은 더 어려웠습니다. 얼굴 임베딩과 유사성 측정을 제공하는 많은 라이브러리와 모델이 있었습니다. 당시에 직면한 공통 문제 중 하나는 어린이의 얼굴을 잘 탐지하지 못하는 것이었습니다(예: 파이썬의 facial_recognition 라이브러리). 모든 유형의 얼굴을 탐지할 수 있는 몇 가지 모델이 있었지만, 이러한 모델들은 유사성 성능이 우수했습니다. 우리는 궁극적으로 결정을 내렸습니다. 얼굴 탐지에는 다른 라이브러리를 사용하고, 얼굴 인식에는 다른 라이브러리를 사용할 것입니다. 두 가지 모두 최고의 성과를 얻을 수 없었으므로, 우리가 선택한 얼굴 탐지 모델은 yolo-face 모델이었고, 이 모델에서 얼굴을 자르고 정렬한 후 임베딩을 추출하여 face recognition에 전달했습니다. facial_recognition 라이브러리는 이를 잘 수행했습니다.
지금까지 우리는 애플리케이션에 후보가 될 수 있는 몇 가지 모델을 가지고 있었고 마인드에 워크플로우도 있었습니다. 아마도 전면 갤러리 측면에 대해 아직 논의하지 않았을 것을 알아채셨을 것입니다. 단지 백엔드 부분(특히 CNNs)에 대해 더 관심이 있었기 때문입니다. 백엔드에서 기반 준비가 되면 앱 갤러리를 생성하여 API 호출을 할 수 있을 만큼 React(및 Electron)을 사용하는 방법을 알고 있었으며 백엔드 준비가 되었을 때 구현할 수 있을 것이라고 확신했어요. 또한 공개 소스 세계에서는 언제든지 누군가가 도와줄 것이므로 그때는 프론트엔드로 걱정할 필요가 없었습니다. 디자인에 있어서는 나보다 더 창의력과 기술을 가진 사람들이 분명히 있기 때문이죠. 그럼에도 불구하고 제 제안서에는 프로젝트의 프론트엔드와 백엔드 부분을 어떻게 다룰 것인지 언급했고 가끔가다 제가 쓴 내용을 다시 상기시키기 위해 그것을 다시 참고했습니다.
GSoC 참여자가 발표된 후 PictoPy에는 저 외에 두 명의 사람이 선택되었습니다. 이로써 우리 모두가 이 프로젝트를 다양한 각도에서 접근하고 충분히 아이디어 회의를 진행할 수 있었습니다. 커뮤니티 결속 기간 동안 우리는 멘토와 빈도 있는 회의를 갖고 최종 제품을 위한 기술 스택, 아키텍처 및 디자인에 대해 논의했어요. 최종 선택 수에 따라 목표가 변경되어 우리 모두는 계획을 재정의하고 작업을 분배해야 했습니다.
우리의 접근
1. 설정
백앤드에서는 다른 프로젝트에서 가져온 스타터 FastAPI 코드를 설정했어요. 이것에는 표준 디렉토리 구조 및 명명 규칙과 Linux에서는 uvcorn을 사용하여 bash 스크립트에서 빠르게 실행되는 앱, Windows에서는 bat 파일이 포함되어 있었어요.
멘토와 프로젝트의 스키마를 논의하면서 객체 탐지 모델을 찾았어요. 우리가 직면한 한 가지 문제는 라이브러리의 크기가 최종 제품 측면에서 다소 크다는 것이었어요. Ultralytics 라이브러리 (PyTorch를 사용하는)는 5GB 크기의 가상 환경과 함께 제공되었는데, 이를 cpu 모드로 설치하면 이 크기가 2GB로 줄었어요.
2GB는 여전히 많은 것 같았어요. 우리가 필요한 모델이 약 80MB 크기면서도요. 그때 ONNX 형식에 대해 알게 되었어요. 이것은 큰 도움이 되었고, 우리는 대략 400MB의 가상 환경과 우리가 사용하는 모델 크기를 더한 객체 탐지 모델을 설정할 수 있었어요.
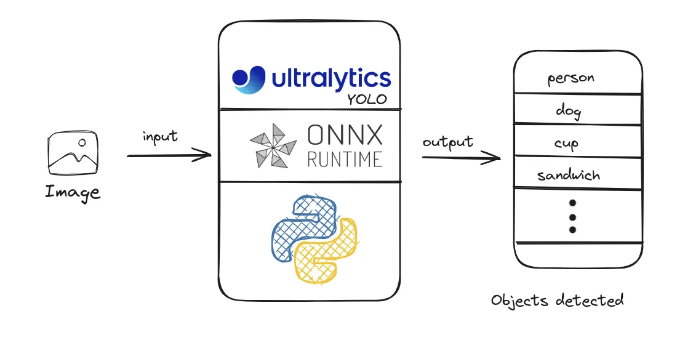
요거 간단해졌네요. 이제 우리는 사용하는 모델들의 ONNX 형식과의 호환성을 찾아야 한다는 것을 알았고, 그것을 다시 사용할 수 있었으며, 마침내 애플리케이션 크기를 어느 정도로 컨트롤할 수 있게 된 것 같아요.
2. 병렬 처리를 이용한 라우팅 로직
라우팅 로직을 다루면서, 우리는 FastAPI를 사용하고 있었기 때문에 프론트엔드에서의 요청이 블로킹되지 않도록 하는 방법을 찾아야 했어요. 다시 말해, 프론트엔드는 이미지 처리가 끝날 때까지 기다리지 않아야 했고, 갤러리에 더 많은 사진을 추가할 수 있어야 했어요. 갤러리에 사진을 추가하고 프론트엔드에 표시하는 것은 이 사진들을 처리하고 클래스를 감지하는 것보다 훨씬 빠른 단계예요. 이는 백엔드에서 실행될 수 있기 때문이죠.
이런 결정들은 나중에 이 백엔드가 미래의 다른 어플리케이션과 호환이 되도록 하기 위해 적절한 엔드포인트를 제공하고 프론트엔드와의 낮은 결합 디자인을 유지하는 것을 염두에 두고 내려졌어요. 이를 위해 우리는 우리의 갤러리 앱에 추가된 여러 이미지를 병렬로 처리하는 방법을 찾아야 했어요. 그때 우리는 파이썬의 스레딩과 같은 옵션들을 시도해보았는데, 그때는 파이썬에서 한 번에 하나의 스레드만 실행할 수 있는 Global Interpreter Lock에 대해 알 지 못했었어요. 이에 대해 더 읽고 싶다면 아래에서 공유한 자료들을 따라보세요. 이외에도 우리는 애플리케이션에 복잡성을 도입한 multiprocessing 라이브러리를 사용해 보기도 했어요. 우리는 FastAPI와 uvicorn 그리고 기본적으로 하나의 워커 프로세스로 실행되는 gunicorn 워커를 사용하고 있었는데, multiprocessing을 실행하기 위해 각각 FastAPI 애플리케이션의 인스턴스를 갖는 여러 워커 프로세스를 구성해야 했고, uvicorn을 사용함으로써 교차 플랫폼 호환성 문제에 부딪히기도 했었어요. 결국 우리는 hypercorn을 사용하게 되었어요.
마침내, 우리는 asyncio를 사용하기로 결정했어요. FastAPI는 asyncio를 완전히 지원하는 비동기 웹 프레임워크인 Starlette 위에서 구축되었어요.
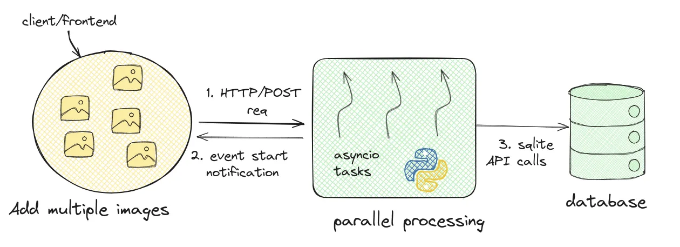
이러한 결정들은 커뮤니티, 팀 및 멘토의 피드백을 기반으로 시간이 지남에 따라 개선되었어요.
3. 데이터베이스 설계
전통적인 이미지 갤러리 데스크톱 애플리케이션으로, 구조화된 방식으로 작업을 수행하기 위해 일종의 데이터베이스 스키마가 필요했습니다. 이미지에 대한 경로를 키로 원래 저장하면서(이는 클라이언트로부터의 페이로드이기도 합니다), 이미지를 처리하여 모델이 감지한 클래스를 기반으로 해당 객체에 속하는 인덱스를 추가했습니다. 이미지의 메타데이터(생성 날짜, 크기, 형식 등)도 저장하고, 미래에는 이미지에서 발견된 얼굴 임베딩 목록(파란색으로 표시)을 저장할 예정입니다.

이렇게 구성된 상태에서 우리는 앨범 스키마를 정의하여 앞으로 나아갔는데, 이는 많은 이미지와 일부 앨범 기능으로 이루어져 있었습니다. 여기서 주요 키는 앨범 이름 자체이며, 사용자가 필요한 경우 제공할 수 있는 간단한 설명이 함께 포함된 앨범의 경로입니다.
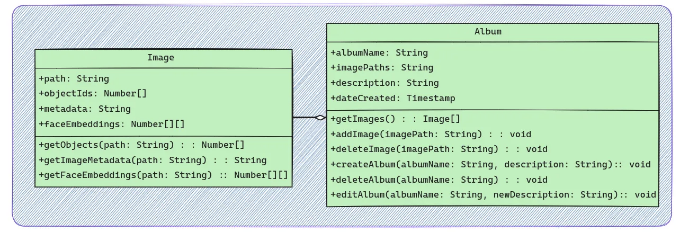
우리 갤러리 앱의 특성과 모델과의 호환성 때문에 이러한 스키마는 시간이 지남에 따라 계속 변화합니다. 더 구체적인 매핑을 얻기 위해 더 많은 스키마를 생성할 계획이며, 예를 들어 이미지 경로의 숫자/uuID를 포함하는 별도의 테이블을 생성하여 이를 모든 곳에서 주 키로 사용할 예정입니다. 미래에 예상되는 어려움 중 하나는 사용자가 파일 시스템을 통해 응용 프로그램 외부에서 이미지를 수동으로 삭제하는 경우에 대처해야 할 것입니다.
우리의 미래 목표
다양한 얼굴 인식 모델을 탐색하면서 이러한 모델이 ONNX 형식과 호환되는지 확인해야 했습니다. 이를 위해 ONNX 저장소에는 그러한 인식 모델의 예제가 있습니다. arcface가 그 중 하나입니다. 이것이 우리가 필요한 바로 그것이며, 우리 애플리케이션에 이를 통합할 것입니다.
우리가 흔히 하는 작업 흐름 중 하나는 아이디어를 고안하는 것, 이 아이디어에 대한 모델을 찾는 것, 이러한 모델의 ONNX 형식 지원을 찾는 것, 그리고 이를 통합하는 것입니다. 이 작업에 OpenVINO를 사용하는 것이 좋았습니다. 훌륭한 문서와 모델을 실행하는 데 사용할 수 있는 예제 노트북이 포함된 Model Zoo가 제공되었습니다.
이것은 우리 응용 프로그램에 많은 가능성을 열어 주었습니다. Linux, Windows 및 MacOS에서 런타임을 사용하여 교차 플랫폼 호환성을 보장할 수 있습니다. 이것은 다양한 모델을 제공하며 중간 표현(IR)으로 변환하여 사용할 수 있습니다. 다행히도 arcface는 OpenVINO에서 문서화 된 모델 중 하나였습니다. 우리는 정렬 없이 LFW 데이터셋의 이러한 모델들을 테스트한 결과 얼굴 모델의 사이즈가 약 200MB 정도일 때 꽤 잘 동작합니다. 이것은 얼굴 정렬과 landmark detection (눈, 코, 입 등)을 위한 MTCNN을 지원하며, 우리는 이를 향후 통합할 계획입니다.
나중에 이러한 임베딩을 사용하여 비슷한 얼굴을 포함하는 사진을 클러스터링하여 사용자에게 구글 포토와 유사하게 특정인의 이미지를 반환하는 옵션을 제공할 수 있습니다. OpenVINO를 사용한다면 저장한 태그에 기반한 검색 기능도 추가할 수 있습니다.
도전과 배운점
내가 처음에 제안한 계획과는 달리, 환경 및 런타임의 변화로 인해 위에 설명한 기술들이 다르게 진행되었습니다. 이는 ONNX 및 OpenVINO의 문서를 찾아본 적이 없기 때문에 어려움을 겪은 첫 번째 경험이었습니다. 팀원들이 직면한 어려움과 그들이 그것을 해결하는 방법을 알게 된 것 또한 좋은 경험이었습니다. 파이썬에서의 다중 처리에 대해 사전에 알지 못했고, 동시성에 대한 초기 접근 방식이 달라졌기 때문에 지속적인 도전은 앞으로 이 프로젝트에 참여할 다른 기여자들을 고려하여 결정을 내리는 것이었습니다. 저는 딥러닝 모델을 기반으로 개발된 도구들과 Python 언어 전반에 대해 더 강한 이해를 가지게 되었습니다. 이러한 배움들을 다른 부수 프로젝트와 학업 프로젝트에도 적용할 수 있었으며, 전체적으로 배우는 것이 정말 즐거웠습니다. 이 프로젝트에서 작업하는 동안 참고한 자료 목록을 추가하고, 여러분에게도 도움이 되기를 바랍니다.
자원
- 객체 검출을 위한 Ultralytics YOLO 모델
- ONNX 형식의 YOLOv8 모델 사용 예시를 보여주는 저장소
- ORM에 관한 블로그
- YOLOv8 얼굴 모델
- ONNX 모델의 모음
- OpenVINO Toolkit의 Open Model Zoo
- asyncio, concurrency 및 GIL에 대한 Real Python 튜토리얼
- 이미지에서 메타데이터 추출에 대한 Python 코드 튜토리얼
이 블로그 시리즈의 첫 번째 부분을 이 링크에서 확인하지 않으셨으면 확인하세요. 그리고 이 블로그 시리즈의 다음 부분을 기대해 주세요. GitHub 및 LinkedIn에서 저와 연락할 수 있습니다. 읽어 주셔서 감사합니다!