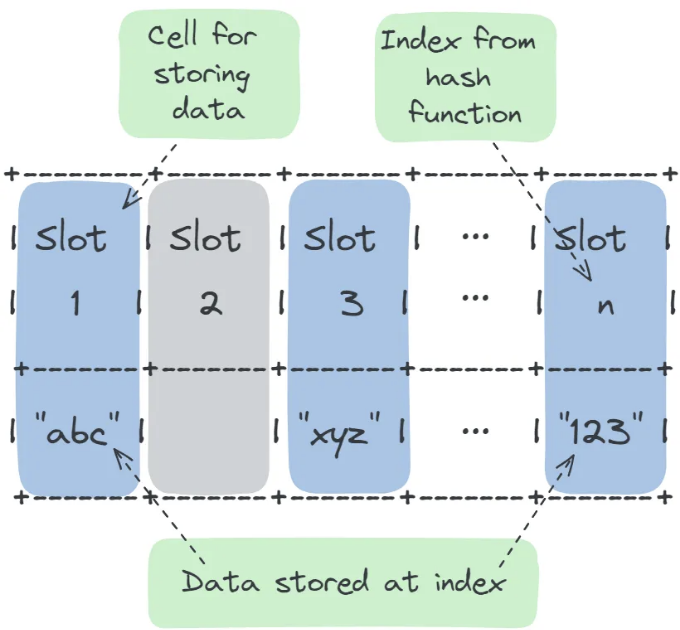
1. 소개
해시 테이블은 소프트웨어 개발에서 효율적인 데이터 저장 및 검색의 기초입니다. 고유한 키를 통해 데이터에 빠르게 액세스할 수 있도록 함으로써, 해시 테이블은 높은 속도로 조회, 삽입 및 삭제를 가능케 하여, 데이터베이스 인덱싱 및 캐싱 솔루션과 같이 성능이 중요한 시나리오에서 필수적입니다.
해시 테이블의 본질은 해싱 메커니즘에 있습니다. 이 메커니즘은 해시 함수를 사용하여 키를 배열 인덱스로 변환합니다. 선택된 인덱스는 배열에 해당 값이 저장되는 위치를 결정합니다. 이 함수가 키를 배열 전체에 균일하게 분산시키고 이중 해싱(double hashing) 및 제곱 프로빙(quadratic probing)과 같은 고급 충돌 해결 기술을 사용함으로써, 해시 테이블은 충돌을 최소화하고 데이터 검색 시간을 최적화할 수 있습니다. 이러한 방법은 해시 테이블이 빠른 액세스를 유지하도록 도와주며, 높은 부하 요소에서도 성능을 유지하는 데 중요합니다.
2. 기초 이해하기
2.1 해시 테이블의 주요 구성 요소 설명
해시 테이블은 데이터를 효율적으로 저장하고 관리하기 위해 함께 작동하는 여러 가지 핵심 구성 요소로 구성되어 있습니다:
해시 함수: 이것은 해시 테이블의 핵심입니다. 해시 함수는 입력 키를 가져와 버킷이나 슬롯 배열 내에서 해당 값이 저장된 위치의 인덱스를 계산합니다. 해시 함수의 효율성은 테이블 내 데이터의 분배에 영향을 미치므로 중요합니다. 좋은 해시 함수는 충돌을 최소화하고 항목들을 버킷들 사이에 균일하게 분배합니다.
버켓 또는 슬롯: 이들은 데이터 항목이 저장되는 배열 내의 위치입니다. 각 버켓은 하나 이상의 항목을 저장할 수 있습니다. 가장 간단한 형태에서 버켓은 키-값 쌍을 하나 보유합니다. 그러나 충돌 처리 전략에 따라, 더 복잡한 데이터 구조나 항목 목록을 보유할 수도 있습니다.
충돌 처리: 두 키가 동일한 인덱스로 해싱될 때 충돌이 발생합니다. 충돌을 효율적으로 관리하는 것은 해시 테이블의 성능을 유지하는 데 중요합니다. 충돌을 처리하는 여러 방법이 있습니다. 그 중 일부는 다음과 같습니다:
- 연결 방식: 이 방법은 더 복잡한 데이터 구조(예: 연결 리스트 또는 다른 해시 테이블)를 사용하여 동일한 인덱스에 여러 요소를 저장하는 것을 포함합니다. 특정 인덱스의 각 버켓이 동일한 해시 인덱스를 공유하는 항목 목록의 헤드를 가리킵니다.
- 개방 주소 방식: 개방 주소 방식에서 모든 요소는 배열에 직접 저장됩니다. 충돌이 발생하면 해시 테이블이 미리 정의된 시퀀스에 따라 다음 사용 가능한 슬롯을 탐색하거나 검색합니다. 일반적인 전략으로는 선형 조사, 이차 조사 및 두 번 해싱이 포함됩니다. 각 방법은 구현의 용이성과 충돌 감소 효과면에서 다른 이점을 제공합니다.
2.2 소프트웨어 개발에서 해시 테이블의 일반적 사용 사례 개요
해시 테이블은 소프트웨어 개발에서 널리 사용되며 효율성과 다용성으로 인해 귀중히 여겨집니다. 다음은 일반적인 사용 사례입니다:
- 데이터베이스 색인: 해시 테이블은 데이터베이스 색인 시스템의 성능에 필수적인 빠른 데이터 검색을 제공합니다.
- 캐싱: 해시 테이블은 빠른 캐시된 데이터 조회가 중요한 캐싱 애플리케이션에 이상적입니다. 효율적인 삽입, 조회 및 삭제가 가능합니다.
- 데이터 중복 제거: 데이터 중복을 최소화해야 하는 상황에서 해시 테이블은 중복 데이터를 신속하게 식별하는 데 도움을 줄 수 있습니다.
- 연관 배열: 많은 프로그래밍 언어가 연관 배열(맵 또는 사전이라고도 함)을 구현하는 데 해시 테이블을 사용합니다. 사용자 정의 키를 기반으로 데이터를 검색하고 저장할 수 있습니다.
- 고유한 데이터 표현: 해시 테이블은 고유한 항목 집합을 유지하는 데 유용하며 반복 검사가 필요한 구현에서 널리 사용됩니다.
3. 파이썬 환경 설정
필요한 도구 및 라이브러리
파이썬에서 해시 테이블을 구현하려면, 파이썬 인터프리터와 텍스트 편집기 또는 통합 개발 환경(IDE)이 필요합니다. 파이썬의 표준 라이브러리만으로 해시 테이블을 구축하는 데 충분하므로 이 기본적인 구현에는 추가적인 라이브러리가 필요하지 않습니다. 그러나 해시 테이블을 고급 기능으로 확장하거나 특정 애플리케이션에 사용하기 위해 NumPy와 같은 라이브러리를 사용하는 것을 고려할 수 있습니다. 성능 최적화를 위해 NumPy를 사용하거나 pytest를 사용하여 구현을 테스트할 수 있습니다.
시스템에 파이썬을 설치했는지 확인하세요. 파이썬 3.8 이상을 권장합니다. 개선된 기능과 지원으로 인해 최신 버전의 파이썬을 공식 파이썬 웹사이트에서 다운로드하거나 macOS의 brew나 Ubuntu Linux의 apt와 같은 패키지 관리자를 사용할 수 있습니다.
해시 테이블을 위한 파이썬 스크립트 또는 모듈의 초기 설정
- 새로운 파이썬 파일 만들기: 먼저 hash_table.py라는 새로운 파이썬 파일을 만들어 시작하세요. 이 파일에는 해시 테이블 구현과 관련된 모든 코드가 포함됩니다.
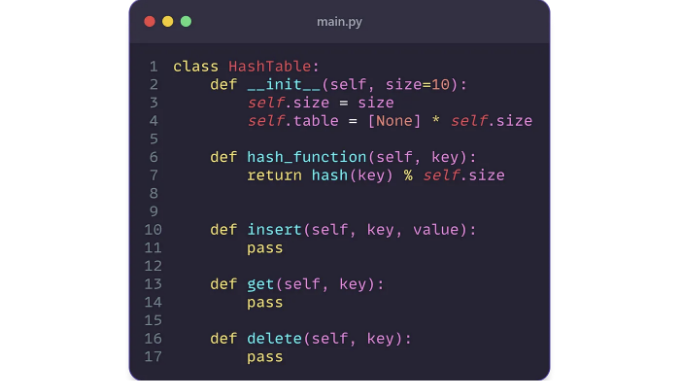
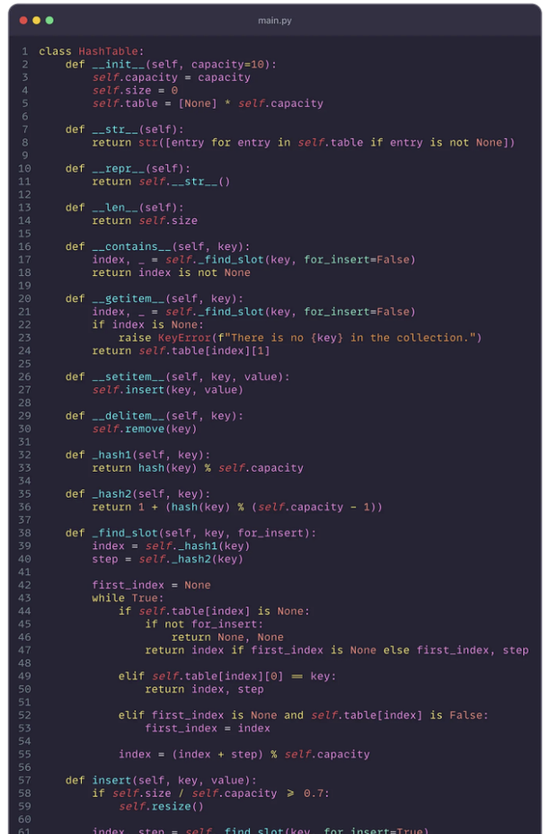
- 해시 테이블 클래스의 구조 정의: HashTable이라는 클래스를 정의하여 시작하세요. 이 클래스는 삽입, 삭제, 조회 등 해시 테이블의 모든 기능을 캡슐화할 것입니다. 다음은 시작할 수 있는 기본 구조입니다:
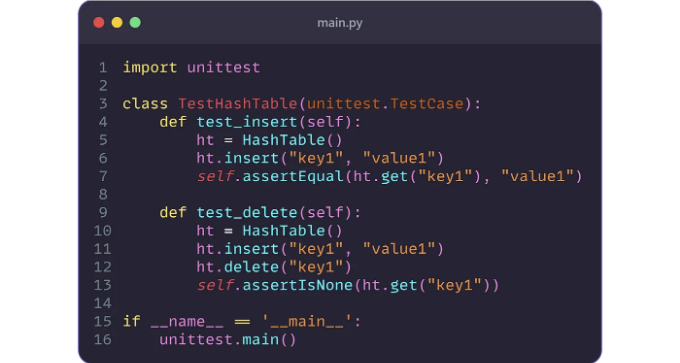
- 테스트 설정: 해시 테이블을 작성하는 과정에서 확인할 수 있는 간단한 테스트 메커니즘을 설정하는 것이 좋습니다. Python의 내장된 unittest 프레임워크를 사용하여 테스트 케이스를 작성할 수 있습니다:
- 스크립트 실행: 명령줄에서 파일이 있는 디렉토리로 이동하여 python hash_table.py를 실행하여 스크립트를 실행하고 작성한 테스트를 실행할 수 있습니다.
4. 해시 테이블 클래스 구현
4.1 해시테이블 클래스 구조 정의
해시테이블 클래스는 우리의 해시 테이블의 청사진 역할을 합니다. 이는 키-값 쌍의 저장, 검색 및 삭제를 효율적으로 관리하기 위해 설계되었습니다. 아래는 초기화, 데이터 처리를 위한 메서드 및 해시 함수를 적용하는 메서드가 포함된 클래스의 기본 구조입니다:
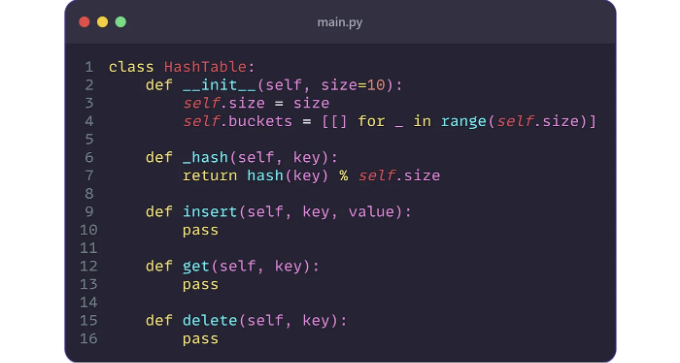
4.2 메소드 추가
- init: 해시 테이블 초기화. 이 메소드는 지정된 크기로 해시 테이블을 설정하고 버킷을 초기화합니다. 충돌 처리 전략에 따라 버킷은 체이닝을 위한 리스트로 구현하거나 오픈 어드레싱을 위한 빈 슬롯으로 구현할 수 있습니다.
- insert: 해시 테이블에 아이템 추가. 이 메소드는 새로운 키-값 쌍을 해시 테이블에 삽입합니다. 해시 함수를 사용하여 키의 해시 인덱스를 계산하고 값을 적절한 버킷에 배치하며, 필요에 따라 충돌을 처리합니다.
- get: 키로 아이템 조회. get 메소드는 해시 테이블에서 키를 검색하고 해당하는 값 반환합니다. 가능한 충돌을 처리하고, 키를 찾을 수 없는 경우 None을 반환하여 견고한 데이터 검색을 보장합니다.
- delete: 키로 아이템 삭제. 이 메소드는 키를 사용하여 해시 테이블에서 키-값 쌍을 제거합니다. 올바른 버킷을 찾아 해당 아이템을 제거하며, 이후 요소에 영향을 미칠 수 있는 충돌을 관리합니다.
- _hash: 해시 함수 적용을 위한 내부 메소드. 이는 키에 대해 해시 함수를 적용하는 과정을 단순화하는 도우미 메소드입니다. 이를 통해 키가 버킷 리스트의 범위 내에서 유효한 인덱스로 변환됩니다.
4.3 체이닝(링크드 리스트) 또는 오픈 어드레싱을 이용한 충돌 처리 설명
- 체이닝(링크드 리스트): 체이닝은 충돌 해결 기법으로, 배열 내 특정 인덱스의 각 버킷이 연결 리스트를 시작할 수 있습니다. 동일한 인덱스로 해싱된 모든 키-값 쌍은 이 리스트에 저장되어 같은 인덱스에 여러 항목을 보관하도록 허용하지만, 최악의 경우 원소를 검색하는 시간 복잡성이 증가할 수 있습니다.
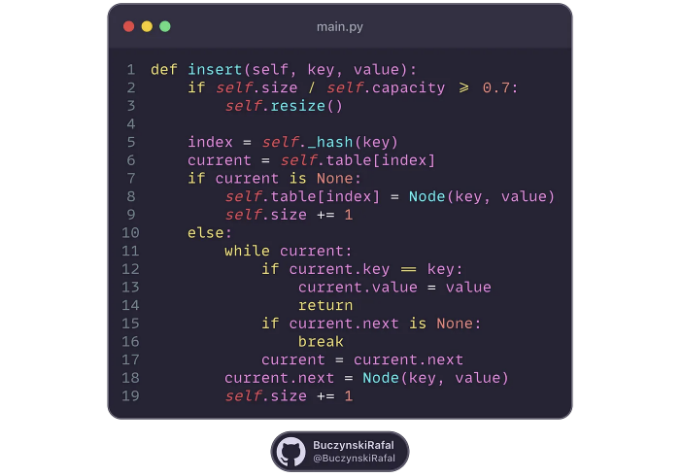
- Open Addressing: Open addressing stores all elements directly in the array and resolves collisions by finding another empty slot within the array. The common strategies for open addressing include linear probing, quadratic probing, and double hashing, each with distinct approaches to resolving collisions efficiently.
Here’s an implementation of linear probing:
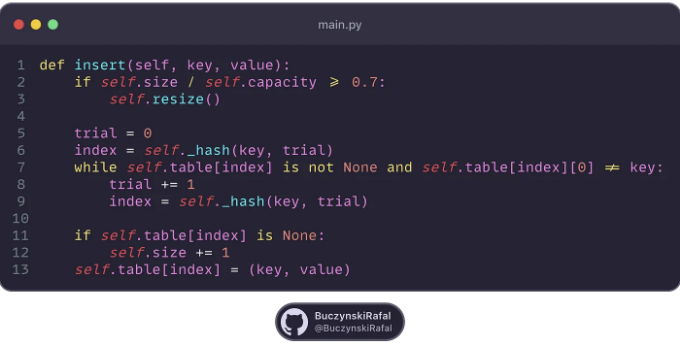
다음은 이차 조사법의 구현 예시입니다:
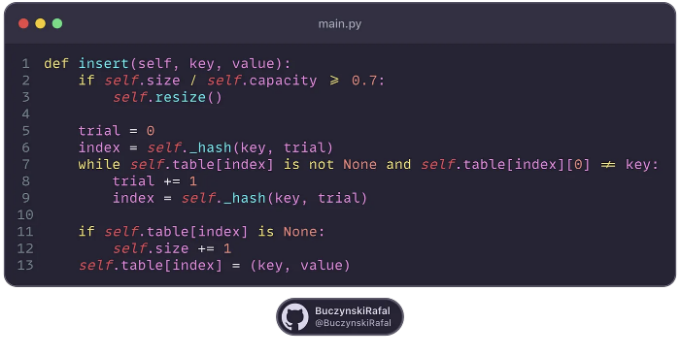
다음은 두 번째 해싱(double hashing)의 구현 예시입니다:

5. 충돌 처리
5.1 체이닝의 상세 설명 및 Python에서의 구현
체이닝은 해시 테이블에서 충돌을 처리하는 일반적인 방법으로, 특정 인덱스의 각 버킷이 하나 이상의 요소를 보유할 수 있습니다. 이 접근 방식은 동일한 인덱스로 해싱된 여러 항목을 저장하는 데 연결 목록과 같은 보조 데이터 구조를 사용합니다. 각 버킷이 항목 리스트를 저장할 수 있도록 함으로써 체이닝은 충돌을 우아하게 처리하고 높은 부하 요인에서도 성능을 유지합니다.
Python에서의 구현: 해시 테이블에서 체이닝을 구현하는 상세 예제입니다.
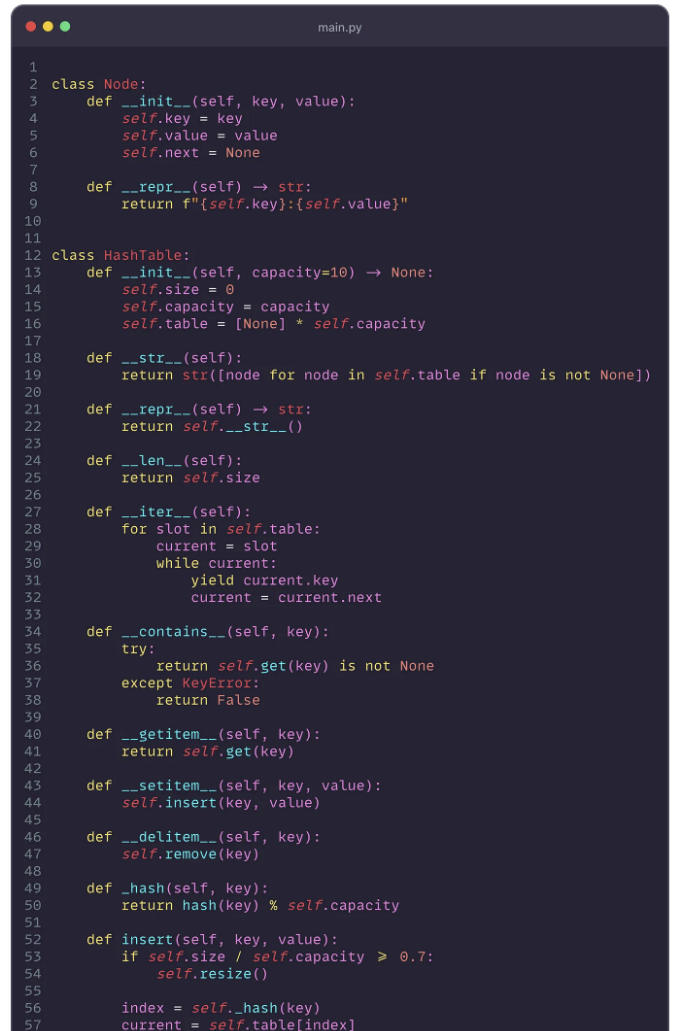
이 구현에서 각 버킷은 연결 리스트로 연결된 여러 항목을 잠재적으로 저장할 수 있습니다. 새 키-값 쌍이 삽입될 때 해시 테이블은 계산된 인덱스에 이미 항목이 있는지 확인합니다. 버킷이 비어있으면 새 노드를 간단히 삽입합니다. 그렇지 않으면 기존 키를 업데이트하거나 키가 존재하지 않으면 체인 끝에 새 노드를 추가합니다. 이 방법은 메모리 사용량 면에서 효율적이며 충돌 처리를 단순화합니다.
체이닝의 장점:
- 체이닝은 구현이 간단합니다.
- 높은 충돌 시나리오를 우아하게 처리할 수 있습니다. 해시 테이블은 버킷 수보다 더 많은 항목을 저장할 수 있습니다.
- 전체 테이블의 크기를 조정할 필요가 없습니다. 영향을 받는 체인만 조정하면 됩니다.
체이닝의 단점:
- 체이닝은 링크드 리스트 포인터와 관련된 오버헤드로 인해 더 많은 메모리를 사용합니다.
- 많은 요소가 동일한 인덱스로 해싱되는 최악의 경우에는 요소를 찾는 작업이 느려질 수 있습니다. 이는 링크드 리스트를 탐색해야 하기 때문입니다.
이 충돌 처리 방법은 하중 계수가 높고 해시 테이블이 효율적으로 많은 충돌을 처리해야 하는 경우에 적합합니다.
5.2 대체 방법: 오픈 어드레싱 방법 구현
열린 주소 할당은 해시 테이블 내에서 다양한 버킷 위치를 조사하여 충돌을 해결합니다.
선형 조사: 해시 테이블에서 충돌을 해결하는 간단한 열린 주소 할당 전략입니다. 연결 리스트와 달리 충돌은 동일한 인덱스의 항목을 연결하는 것이 아니라, 선형 조사는 배열 내에서 새 항목을 저장할 다음 사용 가능한 슬롯을 찾습니다. 이 방법을 통해 모든 항목이 배열 내에 직접 저장되므로 캐시 성능이 향상되고 공간을 더 효율적으로 사용할 수 있습니다.
Python에서의 구현:
이 구현에서 충돌이 발생하는 경우(즉, 해시된 인덱스가 이미 사용 중인 경우), 해시 테이블은 다음 사용 가능한 슬롯을 선형적으로 탐색합니다. 이 방법은 간단하고 효과적이지만 연속적인 슬롯이 채워져 클러스터링이 발생할 수 있어 테이블이 채워질수록 평균 검색 시간이 증가할 수 있습니다.
선형 조사의 장점:
- 주 메인 테이블 외 추가 메모리가 필요하지 않아 공간을 효율적으로 사용합니다.
- 구현 및 이해하기 쉽습니다.
- 연속적인 메모리 사용으로 인한 좋은 캐시 성능을 지니고 있습니다.
선형 조사의 단점:
- 클러스터링은 고부하 시나리오에서 성능에 상당한 영향을 미칠 수 있습니다.
- 부하 요소 임계값에 도달하면 전체 테이블을 조정해야 하므로 계산 비용이 많이 들 수 있습니다.
선형 조사는 부하 요소가 낮고 중간 수준인 테이블에 적합하며, 삭제 빈도가 낮을 때 특히 효과적입니다. 삭제는 조사 순서를 복잡하게 만들 수 있는 간격을 만들 수 있기 때문입니다.
제곱 조사: 해시 테이블에서 충돌을 해결하는 고급 개방 주소 지정 기술이며, 클러스터링 문제를 해결하여 선형 조사보다 큰 개선을 제공합니다. 선형 조사가 선형 시퀀스에서 다음 사용 가능한 슬롯을 찾는 것과 달리, 제곱 조사는 제곱 다항식을 사용하여 조사 간의 간격을 계산하므로 클러스터를 생성할 가능성을 줄입니다.
파이썬에서의 구현:

이 구현에서는 이차 탐사가 선형 탐사에서 발생하는 주요 클러스터링 문제를 크게 줄이기 위해 탐사 시도 횟수의 이차 함수를 사용하여 다음 인덱스를 계산합니다. 탐사 함수는 다음과 같은 공식을 사용합니다: (index + c1trial + c2trial^2) % table_size, 여기서 c1과 c2는 상수이고, trial은 빈 슬롯을 찾거나 루프가 감지될 때까지 각 탐사마다 1씩 증가합니다.
이차 탐사의 장점:
- 선형 탐사와 비교하여 클러스터링을 줄입니다.
- 클러스터링 된 항목을 효율적으로 분산하여 해시 테이블 공간을 더 효과적으로 활용합니다.
- 다음 인덱스를 계산하는 과정은 여전히 비교적 간단하고 빠릅니다.
제곱 탐사의 단점:
- 선형 탐사보다는 심각성이 적긴 하지만 부착 현상이 발생할 수 있습니다.
- c1 및 c2 값의 선택이 성능에 상당한 영향을 미치며 신중한 조정이 필요합니다.
- 다른 개방 주소 메서드와 마찬가지로 테이블이 너무 가득 차면 크기를 조정해야 합니다.
제곱 탐사는 중간 부하 인자에 대해 효과적인 충돌 해결 기술이며 해시 테이블 크기를 충분히 크게 유지하여 자주 크기 조정을 피할 수 있는 시나리오에서 특히 유익합니다.
더블 해싱: 간단한 형태의 탐사와 관련된 클러스터링 문제를 크게 줄이는 데 기여하는 두 개의 해시 함수를 사용하는 개방 주소의 정교한 방법입니다. 선형 또는 제곱 탐사와 달리, 더블 해싱은 충돌이 발생한 후 단계 크기를 계산하기 위해 두 번째 해시 함수를 사용하여 각 탐사가 키를 기반으로 한 독특한 순서를 따르도록 합니다. 이 방법은 항목을 해시 테이블 전체에 골고루 분배하여 효율적이고 효과적인 것으로 알려져 있습니다.
파이썬에서의 구현:
이 구현에서 첫 번째 해시 함수는 초기 슬롯을 결정하고 충돌이 발생하는 경우 두 번째 해시 함수는 다음 프로브를 위한 오프셋을 제공합니다. 이는 단순 혹은 제곱 프로빙과는 다르며 단계가 고정되어 있거나 예측 가능한 패턴으로 증가하는 것이 아닙니다. 따라서 더블 해싱은 주요 및 보조 클러스터링을 모두 줄여 데이터 분포를 더 균일하게 만듭니다.
더블 해싱의 장점:
- 다른 조사 기법보다 클러스터링을 더 효과적으로 최소화합니다.
- 높은 부하 계수를 가진 해시 테이블에서 높은 성능을 제공합니다.
- 각 키는 고유한 조사 시퀀스를 받아 다른 조사 방법보다 성능을 향상시킵니다.
더블 해싱의 단점:
- 선형 또는 이차 조사보다 구현이 더 복잡합니다.
- 두 번째 해시 함수를 계산하기 위해 추가 계산이 필요합니다.
- 성능은 두 해시 함수의 품질에 매우 의존합니다.
더블 해싱은 해시 테이블이 높은 트래픽을 경험하거나 키 분포로 인해 충돌이 자주 발생할 수 있는 애플리케이션에서 특히 유용합니다. 입력을 효율적으로 분배하는 능력으로 대규모 데이터 세트에 대한 훌륭한 선택입니다.
5.3 각 충돌 해결 기술의 장단점
체이닝: 장점: 구현하기 쉽고 높은 충돌 상황을 우아하게 처리함; 크기 조정 시 전체 테이블을 다시 해싱할 필요가 없음. 단점: 더 많은 메모리를 사용함; 연결 리스트 작업이 비연속 메모리 할당 때문에 느릴 수 있음.
오픈 어드레싱: 장점: 해시 테이블 배열 자체에 모든 요소를 저장하여 공간을 효율적으로 사용함; 연속적인 메모리 사용으로 인한 더 나은 캐시 성능. 단점: 클러스터링이 발생하여 효율성이 감소할 수 있음; 테이블이 가득 찰 경우 리사이징이 필요함; 리사이징을 구현하기 복잡함.
각 충돌 처리 방법은 상충 관계가 있으며 특정 유형의 응용 프로그램에 가장 적합합니다. 체이닝은 불특정하거나 매우 변동적인 부하를 갖는 해시 테이블에 적합할 수 있으며, 오픈 어드레싱은 안정적인 데이터 세트와 충돌을 최소화하기 위한 좋은 해시 함수가 있는 응용 프로그램에 더 적합할 수 있습니다.
6. 테스트 및 디버깅
6.1 해시 테이블을 위한 테스트 케이스 작성
해시 테이블의 효과적인 테스트는 다양한 조건에서 데이터를 처리하는 신뢰성과 효율성을 보장하기 위해 중요합니다. 서로 다른 프로빙 기법을 사용하여 해시 테이블 구현을 위한 포괄적인 테스트 케이스를 작성하는 방법은 다음과 같습니다:
요소 삽입, 검색 및 삭제:
- 기본 작업(삽입, 가져오기, 삭제)이 예상대로 작동하는지 확인하는 간단한 테스트부터 시작해보세요. 해시 테이블에 요소를 추가하고, 키를 사용하여 그 값을 검색하고, 일부 요소를 제거하여 테이블이 올바르게 업데이트되는지 확인하는 것이 포함됩니다.
고부하로 성능 확인:
- 해시 테이블이 로드 팩터가 증가함에도 효율적으로 작동하는지 확인하세요. 많은 수의 요소를 삽입하고 다양한 작업에 걸리는 시간을 측정하여 수행할 수 있습니다. 해시 테이블이 용량 한계에 가까워지는 경우와 리사이징을 처리하는 방법에 대한 테스트를 해보세요.
충돌 처리에 대한 스트레스 테스트:
- 동일한 값으로 해싱되는 많은 키가 있는 시나리오를 만들어 충돌 처리를 테스트합니다. 이는 충돌 처리 메커니즘의 효율성 (체이닝, 선형 조사, 제곱 조사, 이중 해싱)과 강압하에서의 구조적 무결성을 테스트하는 것을 포함합니다.
샘플 테스트 구현:
- 체이닝: pytest 픽스처를 사용하여 여러 항목이 동일한 버킷으로 해싱되는 시나리오를 만들고 해당 항목이 검색 및 삭제 가능한지 확인합니다. 버킷 내에서 광범위한 목록을 처리하는 체이닝이 어떻게 처리되는지 테스트합니다.

- Linear Probing: 해시 테이블이 충돌을 해결하는 방법을 테스트하는 것에 초점을 맞추세요. 다음으로 사용 가능한 슬롯을 찾아 보세요. 항목이 올바르게 덮어쓰기되거나 업데이트되는지, 그리고 테이블이 필요에 따라 어떻게 확장되는지 확인하세요.

- Quadratic Probing: 선형 조사와 유사하지만 다른 초기 충돌을 테스트하고, 이차 단계 계산이 항목을 충돌하지 않는 슬롯에 올바르게 배치하는지 확인하세요.
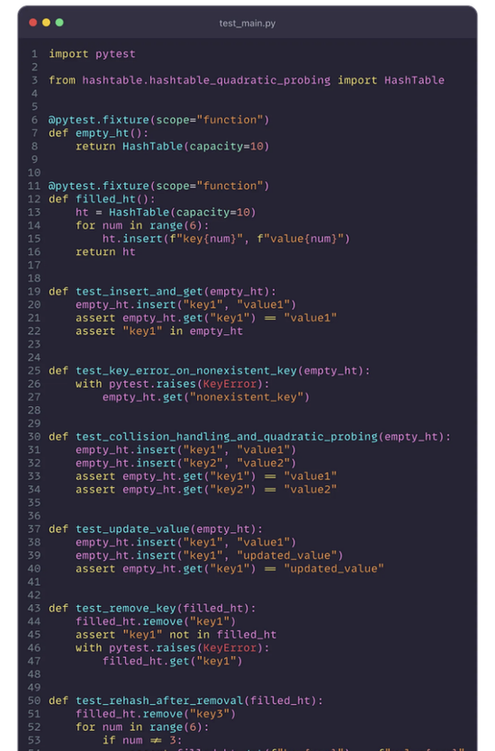
- 더블 해싱: 보조 해시 함수를 사용하여 충돌을 줄이는 효과를 테스트해보세요. 더블 해싱 방법이 다른 방법보다 항목을 테이블에 더 균등하게 분배하는지 확인해보세요.
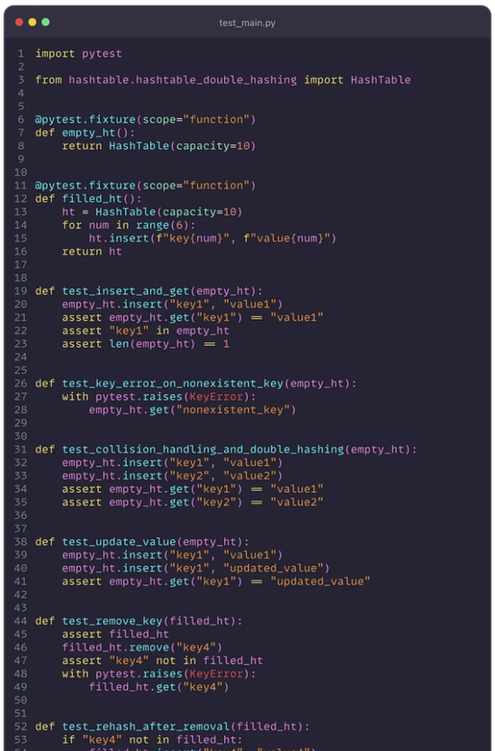
6.2 해시 테이블 구현에서 발생하는 일반적인 문제 해결
해시 테이블을 디버깅하는 것은 주로 충돌 처리, 해시 함수 분포, 동적 크기 조절과 관련된 문제를 식별하는 것을 포함합니다. 다음은 몇 가지 전략입니다:
- 충돌 처리: 요소가 자주 손실되거나 덮어써지는 경우 충돌 해결 논리를 검토해보세요. 삽입, 삭제 및 조회가 충돌하는 키를 올바르게 처리하도록 확인해주세요.
- 해시 함수 품질: 해시 함수에 의한 부족한 분포는 성능 병목 현상으로 이어질 수 있습니다. 특정 버킷이 과도하게 사용되는 경우 해시 함수를 수정하는 것을 고려해보세요. 키들이 버킷 간에 어떻게 분산되는지 테스트하여 이 문제를 확인할 수 있습니다.
- 메모리 누수 및 오버플로우: 수동 메모리 관리가 있는 언어에서 특히 관련됩니다만, Python에서는 쓰레기 수집을 방해하는 의도하지 않은 참조를 확인하세요. 또한, 메모리 오버플로우나 과도한 재할당을 유발하지 않으면서 크기 조정 로직이 메모리를 적절히 관리하는지 확인하세요.
- 동시성 문제: 해시 테이블이 멀티 스레드 응용 프로그램에서 사용되는 경우 경합 조건이 데이터 구조를 손상시킬 수 있습니다. 잠금을 구현하거나 동시성 데이터 구조를 사용하여 스레드 안전성을 보장하세요.
7. 고급 주제
7.1 동적 크기 조절을 통한 해시 테이블 성능 향상
요소 수가 증가함에 따라 해시 테이블에서 효율적인 성능을 유지하기 위해 동적 크기 조정은 중요한 기능입니다. 크기 조정 없이는 로드 팩터(요소 수 대비 버킷 수의 비율)이 증가하여 더 많은 충돌이 발생하고 따라서 더 긴 검색 시간이 발생합니다. 성능을 향상시키기 위해 해시 테이블은 다음과 같이 동적으로 크기를 조절할 수 있습니다:
- 크기 두 배로 확장: 해시 테이블의 로드 계수가 특정 임계값을 초과할 때(일반적으로 0.7 또는 0.75로 설정), 해시 테이블의 크기가 두 배로 증가합니다. 이 과정은 두 배의 버킷 수를 갖는 새로운 해시 테이블을 만들고 모든 기존 요소를 새 테이블로 재해싱하는 것을 포함합니다.
- 크기 반으로 축소: 마찬가지로 로드 계수가 낮은 임계값(예: 0.1)보다 낮아지면, 해시 테이블의 크기가 반으로 줄어들어 공간을 절약하고 데이터 크기가 작아지는 시나리오에서 효율을 유지합니다.
동적 크기 조정을 구현하는 것은 리사이징 작업 중 데이터 무결성과 최소한의 성능 영향을 보장하기 위해 신중한 처리가 필요합니다.
7.2 해시 테이블의 실제 응용 및 최적화에 대한 토론
해시 테이블은 소프트웨어 엔지니어링에서 만능으로 사용되며, 빠른 데이터 검색이 중요한 다양한 응용 프로그램에서 사용됩니다:
- 데이터베이스: 해시 테이블은 많은 데이터베이스 인덱스 메커니즘을 구동하여 레코드의 신속한 조회, 삽입 및 삭제를 가능하게 합니다.
- 캐싱 시스템: 많은 웹 및 응용프로그램 서버는 해시 테이블을 사용하여 캐싱을 하며, 자주 액세스되는 데이터를 빠르게 검색 가능한 형식으로 저장하여 데이터베이스로의 요청 횟수를 줄입니다.
- 유일한 항목 추적: 해시 테이블은 고유한 항목을 추적하거나 항목의 존재 여부를 확인하는 작업에 이상적이며, 그들의 일정한 실행 시간 특성 때문에 유용합니다.
최적화는 콜리전 최소화를 위해 올바른 해시 함수 선택, 유니버설 해싱 같은 기법 사용, 캐시 성능 향상을 위한 메모리 할당 전략 최적화 등이 포함될 수 있습니다.
7.3 Python의 내장 dict와 사용자 정의 해시 테이블 비교
Python의 내장 dict는 사실상 Python 언어에 통합된 하이퍼 최적화된 해시 테이블입니다:
- 성능: 파이썬의 dict는 C로 구현되어 있어 순수 파이썬으로 작성된 사용자 지정 해시 테이블보다 속도가 빠릅니다. 이는 하위 수준의 최적화와 Python의 동적 타이핑으로 인한 오버헤드가 없기 때문입니다.
- 기능: 파이썬의 dict는 순서를 유지하는 추가 기능을 제공합니다 (Python 3.7부터), 이는 일반적인 해시 테이블 구현에서 일반적으로 제공되지 않는 기능입니다.
- 사용 편의성: 내장 유형인 dict는 Python 구문과 표준 라이브러리에서 직접 지원되므로 사용자 정의 해시 테이블을 구현하는 것보다 편리하게 사용할 수 있습니다.
사용자 정의 해시 테이블은 특정 필요에 맞게 맞춤 설정할 수 있지만, 대부분의 응용 프로그램에 대해 파이썬의 dict는 충분한 성능과 기능을 제공하므로 dict가 지원하지 않는 특정 동작이 필요하지 않는 한 사용자 정의 해시 테이블을 구현할 필요는 없습니다. 예를 들어, 다른 충돌 처리 방법이나 실시간 크기 조정 임계값 등을 필요로 할 때입니다.
결론
이 기사를 통해 Python에서 해시 테이블을 구현하는 것에 대해 깊이 있는 내용을 제공했습니다. 체이닝, 선형 조사, 이차 조사, 두 배 해싱을 포함한 충돌 해결 방법을 탐색했습니다. 각 방법이 충돌을 처리하고 해시 테이블의 성능을 최적화하는 방법을 자세히 설명했으며, 효과적인 응용에 대한 포괄적인 가이드를 제공했습니다. 또한 다양한 시나리오에서 해시 테이블의 신뢰성과 효율성을 보장하기 위한 상세한 테스트 접근 방법에 대해 다루었습니다. 이 논의는 데이터 구조에 대한 이해력을 향상시킬 뿐만 아니라 Python 프로젝트에서 복잡한 데이터 관리 도전에 대비하기 위한 실용적 기술을 갖추도록 도와줍니다. 철저한 테스트 실천을 통해 구현의 무결성과 성능을 향상하는 방법을 보여주었습니다.
친절한 영어로 🚀
In Plain English 커뮤니티에 참여해 주셔서 감사합니다! 떠나시기 전에:
- 작가를 갈치하고 팔로우하세요 ️👏️️
- 팔로우하기: X | LinkedIn | YouTube | Discord | 뉴스레터
- 다른 플랫폼 방문하기: Stackademic | CoFeed | Venture | Cubed
- 알고리즘 콘텐츠를 다루는 블로깅 플랫폼에 질려셨나요? Differ를 시도해 보세요
- PlainEnglish.io에서 더 많은 콘텐츠를 만나보세요