내가 이것을 쓰기 전에, 팝컬쳐 특히 원피스에 너무 많은 선호를 준 것에 대해 죄송합니다. 강조해야 할 특정한 것이 하나 있거든요. 오하라 섬과 그 도서관에 관한 것입니다.

여기서 무슨 일이 있었는지에 대해 너무 많이 이야기하고 싶지 않겠습니다. 이 기사의 초점은 책에 있습니다. 어떻게 디자인하고 관리하며 관련 정보를 수집하는지 등의 것이요. 그러나 이 기사에서는 컴퓨터의 도움을 받아서 이 작업을 잘 할 겁니다. 여전히 책들과 다루긴 하지만, 지난 큰 도서관과의 추악한 역사처럼 이번에는 이 책들이 쉽게 태울 수 없어요. 그러니 시작해봅시다.
내 첫 인상은, 책을 두려워하지 마세요. 책은 어디서나 있어요. 만나본 모든 사람이 다르지 않나요? 네, 우리는 생동하는 책 자체예요. 심지어 당신의 책도 만나본 수많은 사람들에게 빌려주면 수천 권의 책으로 번지더라구요. 모든 것이 아직 기계적이었던 옛날, 도서관에 가는 것은 세계 여행하는 것과 같았어요, 그러나 최대한 싼 방법으로요. 우리가 와서 자신의 ID를 만들고, 원하는 책을 고르고, 빌리고, 그 책을 돌려주고, 그리고 되풀이했죠. 하지만 요즘엔 그렇지 않아요.
현재의 디지턈 시대에는 젊은 세대를 중심으로 디지턈 도서관이 인기를 끌고 있어요. 이는 접근성과 유연성이 뛰어나기 때문입니다. 이제는 실제 도서관을 방문하지 않고도 다양한 정보, 책 및 학습 자료를 얻을 수 있어요. 전자책 같은 걸 들어봤나요?
그래서 이 기사의 목적은 디지턈 도서관을 위한 데이터베이스 시스템을 설계하여 효율성을 향상시키고 잘 조직된 구조를 유지하는 데 도움을 주는 것이에요. 오하라 도서관처럼, 하지만 디지턈 버전으로 말이죠.
데이터베이스를 설계할 때의 첫 번째 단계는 미션 명성을 결정하는 것이에요. 이 프로젝트의 미션 명성은 다음과 같아요:
- 사용자는 도서관에 있는 책 제목을 살펴볼 수 있어요.
- 사용자는 카테고리 또는 유형에 따라 책을 검색할 수 있어요.
- 사용자는 각 책의 도서관 보유량을 알 수 있어요.
- 사용자는 읽고 싶은 책을 대출하거나 예약할 수 있어요.
- 사용자는 각 책의 가용성을 확인할 수 있어요.
그럼에도 불구하고 이 프로젝트에는 몇 가지 주의할 점이 있습니다:
- 기본 대출 기간은 2주입니다. 그러나 고객들은 책을 더 빨리 반납할 수 있고, 도서 대출 기간을 초과하면 책이 자동으로 반납됩니다.
- 고객들은 동시에 최대 2권의 책을 대출할 수 있습니다.
- 현재 이용 불가한 책을 예약할 수 있지만, 고객들은 한 번에 최대 2권만 예약할 수 있습니다.
그리고 이후에 전자 도서관 시스템을 위한 표를 만들고, 주요 및 외래 키를 정의하여 그들의 관계를 확립할 수 있습니다. 아래 그림은 저가 만든 개체 관계 다이어그램(ERD)이며, 각 표에 대한 설명이 포함되어 있습니다. 전체로 10개의 표가 있습니다.
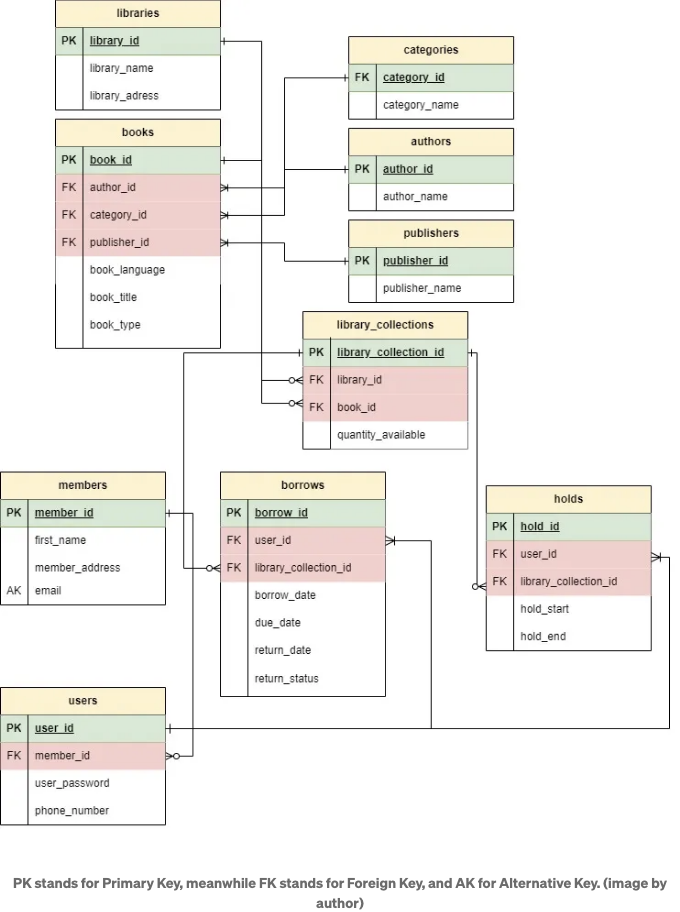
Libraries table
- This table contains information about libraries, including the library_id of each library, its name, and address
Categories table
이 표는 각 카테고리의 ID와 이름을 포함한 카테고리 정보를 담고 있습니다.
작가 테이블
이 표는 각 작가의 ID와 이름을 포함한 작가 정보를 담고 있습니다.
출판사 테이블
— 이 테이블은 각 출판사의 ID와 이름을 포함한 출판사에 대한 정보가 포함되어 있습니다.
Books 테이블
— 이 테이블은 책에 대한 정보를 포함하고 있으며, 주요 키로 책의 ID, 제목, 작가 ID, 카테고리 ID, 출판사 ID 및 책 유형이 포함되어 있습니다.
Library Collections 테이블
특정 도서관에 소장된 책 정보가 담긴 이 테이블은 특정 컬렉션의 ID, 특정 도서관의 ID, 해당 도서관의 ID, 그리고 이용 가능한 수량을 포함하고 있습니다.
회원 테이블
— 특정 회원의 ID(주요 키), 이름, 주소, 이메일 정보를 포함하는 회원 정보가 담긴 테이블입니다.
사용자 테이블
— 사용자 정보를 포함한 테이블이며 특정 사용자의 ID가 주요 키로 사용되고, 회원 ID, 비밀번호 및 전화 번호가 포함되어 있습니다.
Borrow 테이블
— 이 전자 도서관에서 대출 된 책에 대한 정보가 포함 된 테이블입니다. 각 대여 사례에 대해 ID가 주요 키로 사용됩니다. 대출 한 사용자의 ID, 대출 된 도서관 컬렉션 ID, 대출 된 책이 빌린 시간을 나타내는 borrow_date, 대출 날짜가 만료 된 도서의 due_date, 책이 반납 된 시간인 return_date, 그리고 책이 반납 되었는지 여부를 나타내는 return_status가 포함되어 있습니다.
Holds 테이블
— 이 테이블은 전자 도서관에 보관되어 있는 컬렉션에 관한 정보를 포함하고 있습니다. 각 보유 케이스에는 id가 있습니다. 사용자 id, 보유한 도서관 컬렉션 id, 도서 보유가 시작된 시간에 대한 정보를 나타내는 hold_start, 도서 보유 날짜가 만료되는 시간을 나타내는 hold_end가 포함되어 있습니다.
디자인 구현
다음 단계에서는 PostgreSQL을 사용하여 데이터베이스 또는 ERD의 디자인을 구현할 수 있습니다. 테이블을 생성하고 관계를 정의하기 위해 데이터 정의 언어(DDL) 구문을 사용할 수 있습니다. 그리고 데이터베이스 디자인을 구현하는 단계는 다음과 같습니다:
- PostgreSQL 데이터베이스에 연결
- 데이터베이스 생성
CREATE TABLE library_collections ( library_collection_id SERIAL PRIMARY KEY, library_id INTEGER NOT NULL, books_id INTEGER NOT NULL, quantity_available INTEGER NOT NULL CHECK(quantity_available >= 0), CONSTRAINT fk_library_collections_lib FOREIGN KEY(library_id) REFERENCES libraries(library_id), CONSTRAINT fk_library_collections_bk FOREIGN KEY(books_id) REFERENCES books(books_id) );
위의 예시는 라이브러리 컬렉션 테이블 세트를 만드는 경우이며, 해당 외래 키로 제약 조건이 있는 테이블을 작성하는 방법을 보여줍니다. 각각의 외래 키는 자신이 참조하는 원본 테이블을 참조하며, 각 키는 자신이 참조하는 테이블의 기본 키입니다. 전체 문서에 대한 자세한 내용은 아래 링크를 클릭하십시오:
https://github.com/ziadbwdn/E-LibraryRDB
데이터베이스 생성
데이터베이스에서 데이터를 검색하기 위해 테이블 형식의 데이터가 필요합니다. 이 경우, 테이블을 수동으로 생성한 데이터와 Python 라이브러리 Faker를 결합하여 얻은 더미 데이터를 사용합니다. 아래에 이전 스크립트를 통해 생성된 코드 예제와 faker를 사용한 이후 스크립트를 살펴볼 수 있습니다:
# 라이브러리 테이블 생성
def create_libraries(library_name, library_address):
"""
도서관에 대한 DataFrame 생성
Parameters:
- library_names (list): 도서관 이름 목록, 총 8개가 있습니다.
- library_address (list): 도서관 주소 목록, 총 8개가 있습니다.
Returns:
- pd.DataFrame: 도서관 ID 및 도서관 이름과 같은 정보를 포함하는 DataFrame
"""
libraries = {
"library_id": [i + 1 for i in range(len(library_name))],
"library_name": library_name,
"library_address": library_address
}
libraries_df = pd.DataFrame(libraries)
return libraries_df
library_name = ["와칸다 도서관",
"푸스타카 코노하",
"포헨 펜게타후안 풀라우 오하라",
"마이크로 라이브러리 와락 카유",
"C2O 도서관",
"키네루쿠 도서관",
"바카 디 테벳",
"타만 바카 아민 페르푸스타카안 콘테이너",
]
library_address = ["서라바야 자바 팀루 마르고무르 요 퍼마이 6-8 도메인 G 술라바야 자바 팀루",
"자와 바랏 반둥 지엠 앙디리 34-38 번듕 자와 바랏",
"자카르타 디케이 아일란트 자카르타 끄븽나가 라야 25 풀로 게방 라야 25 자카르타 DKI 자카르타",
"메단 수마테라 우타라 마니아 라야 18-20 서라바야 자바 팀루",
"주아 티음틸리스 라야 26 자카르타 DKI 자카르타",
"레페트시부 올라야 16 자카르타 DKI 자카르타",
"반두르 자와 바랏 H Juanda 377 반등 자와 바랏",
"반두르 자와 바랏 H Juanda 377 반등 자와 바랏"
]
libraries_table = create_libraries(library_name, library_address)
libraries_table
# 저자 테이블 생성
def create_authors(n_authors):
"""
저자 및 저자 이름과 저자 ID 사이의 매핑을 만드는 작업
Parameters:
- n_authors (int): 작성할 저자 정보의 수
Returns:
- pd.DataFrame: 저자 ID 및 저자 이름과 같은 정보를 포함하는 DataFrame
"""
authors = []
for a in range(n_authors):
authors.append({
'author_id': fake.unique.random_int(min=1, max=9999),
'author_name': fake.name()
})
authors_df = pd.DataFrame(authors)
return authors_df
# 저자 DataFrame 및 매핑 생성
authors_table = create_authors(800)
authors_table
사용할 라이브러리를 가져오는 첫 번째 단계는 다음과 같습니다:
- pandas: Python에서 데이터 조작 및 분석에 사용됩니다.
- Faker: 가짜 데이터를 생성하는 데 사용되는 라이브러리입니다.
- random: 무작위 값을 생성하는 데 사용됩니다.
- timedelta: 시간을 계산하는 데 사용됩니다.
그리고 가짜 데이터를 얻기 위해 위치 설정을 인도네시아로 설정하세요. 이름, 주소 및 이메일과 같은 가짜 데이터를 얻을 수 있습니다.
# 2단계: 인도네시아 또는 영어로 위치 설정
fake = Faker('id_ID' or 'en_EN')
이후에는 PostgreSQL에 가져오기 전에 더미 데이터를 얻기 위해 필요한 데이터를 실행할 수 있습니다. 만든 테이블 데이터프레임을 성공적으로 저장하기 위해 먼저 csv로 저장해야 합니다.
# CSV로 저장하기
authors_table.to_csv('authors.csv', index=False)
# CSV로 저장하기
library_collections_table.to_csv('library_collections.csv', index=False)
전체 코드는 이 페이지에서 확인할 수 있습니다
https://github.com/ziadbwdn/E-LibraryRDB
이제 가져오기 프로세스에 필요한 모든 데이터가 있는 경우 예를 들어 SQL 쿼리 도구에서 계속할 수 있습니다:
COPY authors(author_id, author_name)
FROM 'C:\Program Files\PostgreSQL\16\pgAdmin 4\SQL Exercise 4\authors.csv'
DELIMITER ','
CSV HEADER
COPY library_collections(library_collection_id, library_id, books_id, quantity_available)
FROM 'C:\Program Files\PostgreSQL\16\pgAdmin 4\SQL Exercise 4\library_collections.csv'
DELIMITER ','
CSV HEADER
이 작업을 수행하기 전에, DDL 구문에서 만든 데이터와 파이썬에서 출력한 csv가 ERD 다이어그램 처럼 우리가 설계한 요구 사항을 충분히 준수하는지 확인하는 것이 중요합니다.
사례 연구
먼저, 각각의 도서관에서 가장 많고 가장 적은 책을 가지고 있는 도서관을 확인해보겠습니다.
SELECT
l.library_name,
COUNT (books_id) AS total_book_collections
FROM library_collections AS lc
JOIN libraries AS l ON lc.library_id = l.library_id
GROUP BY library_name
ORDER BY total_book_collections DESC
그리고 아래는 결과입니다:
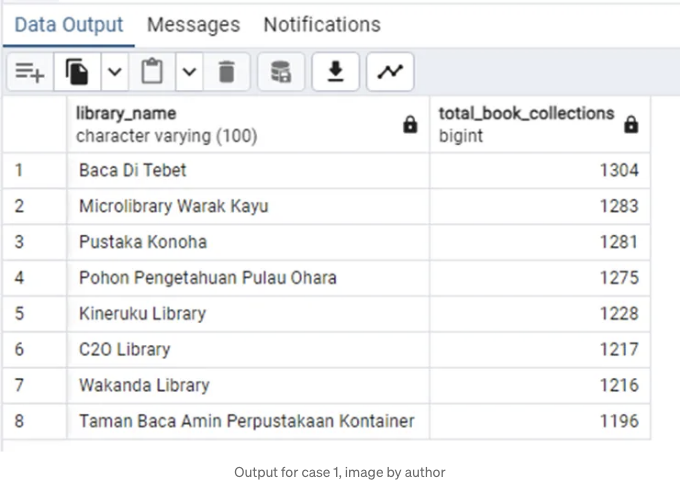
Baca Di Tebet은 책 수집량을 기준으로 하면 가장 많이 모은 도서관이며, Taman Baca Amin은 가장 작은 책 모음을 가진 1196 대비 1304개를 수집했습니다.
그리고 두 번째로, 우리는 가장 많은 책을 대출한 도서관 회원을 살펴보려고 해요.
WITH frequent_borrower as (
SELECT
br.user_id,
m.member_name,
count (br.borrow_id) as amount_of_borrow,
br.return_status
FROM borrows as br
join users as u on br.user_id = u.user_id
join members as m on u.member_id = m.member_id
WHERE return_status is true
GROUP BY 1,2,4
)
SELECT * from frequent_borrower as fb
where fb.amount_of_borrow > 2
order by amount_of_borrow desc limit 10
그런 다음 우리가 결과물로 다음을 받았어요:
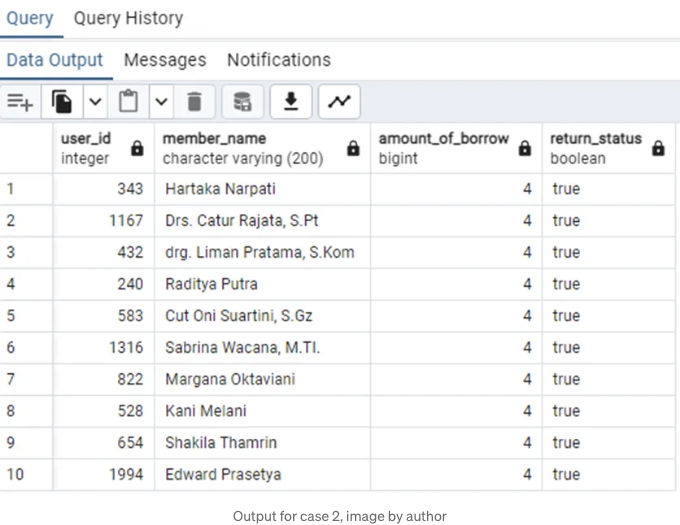
Hartika Narpati부터 Edward Prasetya까지는 도서 4권을 대출한 가장 빈번한 독자입니다.
세 번째 단계에서는, 테이브이지를 다음과 같이 마크다운 형식으로 변경해주세요:
| 책 제목 | 카테고리 이름 | 도서관 이름 | 이용 가능 수량 |
|---|---|---|---|
| book_title | category_name | library_name | quantity_available |
예를 들어, 청소년 자매가 로맨스 소설을 찾고 있어서 도와달라고 요청하며, 특정 도서관(예: Pustaka Konoha)를 찾고 있다면 어떨까요? 아래 PostgreSQL 쿼리를 사용해볼까요?
WITH konoha_books as (
SELECT b.book_title,
c.category_name,
l.library_name,
lc.quantity_available
FROM books as b
join categories as c on b.category_id = c.category_id
join library_collections as lc on b.books_id = lc.books_id
join libraries as l on lc.library_id = l.library_id
WHERE library_name = 'Pustaka Konoha'
)
SELECT * FROM konoha_books as kb
WHERE category_name ilike '%Romance%'
ORDER BY kb.quantity_available DESC
이후 다음이 결과로 나타납니다:
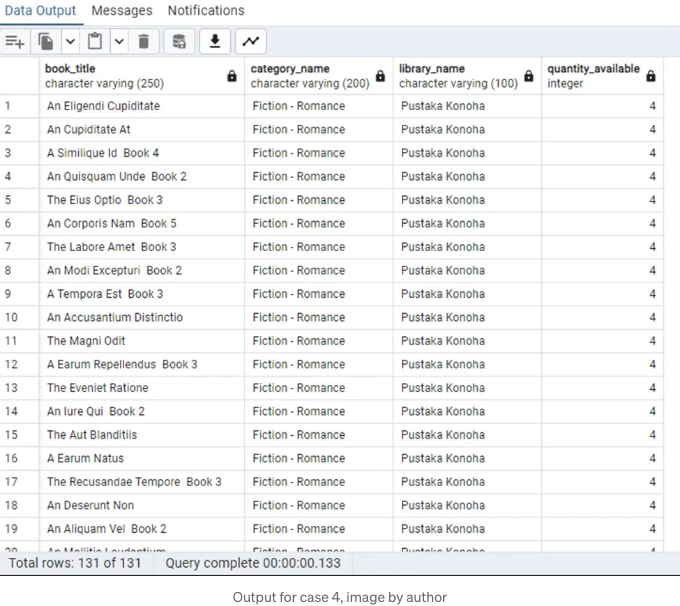
푸스타카 코노하에는 카테고리 소설 - 로맨스에 속하는 131개의 컬렉션이 있습니다.
성장을 위해 사회과학을 주전공으로 선택하셨고, 감독님으로부터 사회과학 주제의 참고 자료를 우선으로 찾아야 한다는 지시를 받았지만 수라바야에 있다는 한계가 있습니다. PostgreSQL 쿼리를 사용하십시오.
WITH surabaya_books as (
SELECT b.book_title,
c.category_name,
l.library_name,
l.library_address,
lc.quantity_available
FROM books as b
join categories as c on b.category_id = c.category_id
join library_collections as lc on b.books_id = lc.books_id
join libraries as l on lc.library_id = l.library_id
WHERE library_address ilike '%Surabaya%'
)
SELECT * FROM surabaya_books as sb
WHERE category_name ilike '%Social%'
ORDER BY ab.quantity_available
위 쿼리를 실행한 결과는 아래와 같습니다:
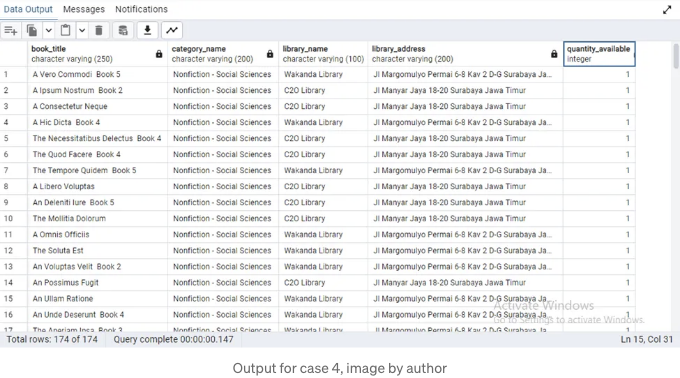
위 결과를 보면, 수라바야에서 볼 수 있는 사회과학 분야의 도서 총 174권이 있습니다.
마지막으로, 빌린 날짜로부터 일반적으로 두 주 후인 만기일을 초과하는 반납으로 인해 벌금을 내야 할 수 있는 사람들이 있습니다. 그들이 누구인지 알아보세요!
WITH duration_borrower as (
SELECT
EXTRACT (DAY FROM br.borrow_date) as days_of_borrow,
EXTRACT (DAY FROM br.return_date) as days_of_return,
br.user_id,
br.borrow_id,
m.member_name,
count (br.borrow_id) as amount_of_borrow,
br.return_status
FROM borrows as br
join users as u on br.user_id = u.user_id
join members as m on u.member_id = m.member_id
GROUP BY 1,2,3,4,5,7
)
SELECT
dur_b.borrow_id,
dur_b.member_name,
ABS(dur_b.days_of_return - dur_b.days_of_borrow) as interval_days,
dur_b.return_status
from duration_borrower as dur_b
where return_status is false
group by 1,2,3,4
order by 3 desc
limit 10
그런 다음 다음을 결과로 받았습니다:
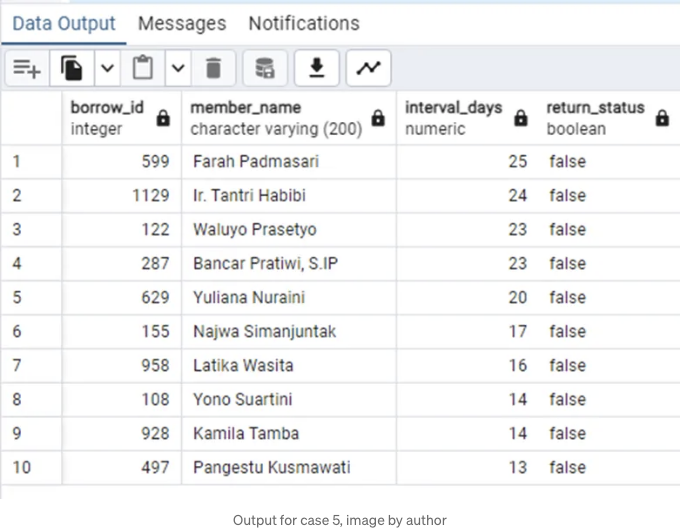
현재 Farah Padmasari와 Latika Wasita가 이번 기회에 조금의 경고나 벌금을 받아야할 것 같아요.
안팎을 다듬으면서 이런 것들의 내부 작동 방식을 조금씩 파악할 수 있기를 희망해요. 완벽하지는 않겠지만, 계속해서 발전할 여지가 많을 거에요.
혹시 실제 책은 태울 수 있지만, 디지털 책은 그렇게 쉽게 태울 수 없지요. 오하라의 지식의 등대는 아직 살아있어요, 적어도 이제는 니코 로빈과 빨강머리 해적단의 손에 있어요. 감사합니다.
참고자료: