파이썬과 Boto3를 활용한 Amazon Redshift 클러스터 자동화에 관한 궁극의 안내서에 오신 것을 환영합니다! Redshift 관리 프로세스를 최적화하고 클러스터 및 스냅샷을 생성 및 관리하며 비용을 절감하고 효율성을 향상시키려면 올바른 곳에 왔습니다. 이 블로그에서는 환경 설정부터 Python을 사용한 고급 자동화 스크립트 구현까지 필수 단계를 안내합니다. 이 가이드를 마치면 실용적인 지식과 프로처럼 Redshift 클러스터를 처리할 준비가 된 코드 조각을 가지고 있을 것입니다. 시작해보죠! 💻📊
준비 사항📋
Redshift 자동화의 흥미로운 세계로 뛰어들기 전에 시작할 준비가 되어 있는지 확인해보겠습니다. 이 섹션에서는 AWS Redshift 환경 및 Python 설정에 필요한 필수 준비 사항을 안내해 드릴 것입니다. 🌐🐍
- ☁️AWS 계정: Redshift를 사용해보기 위해 무료 체험을 신청해보세요.
- 🐍 파이썬 설치: Redshift와 원할하게 대화하기 위해 공식 웹사이트에서 다운로드하세요.
- 📦설치할 모듈: 터미널에서 pip install boto3를 사용하여 설치하세요. AWS 계정을 로컬 컴퓨터에 연결하는 방법에 대한 단계별 비주얼 가이드가 필요하다면, AWS 계정에 Boto3를 설정하는 비디오 자습서를 참고하세요.
이러한 필수 사항이 갖춰지면, 클라우드 데이터베이스와 데이터 분석에 전문가처럼 뛰어들 준비가 되었습니다. ☁️📊
목차 📚
- 수동으로 Redshift 클러스터 생성하기 🎥
- Python과 Boto3를 사용하여 클러스터 생성 자동화 🚀
- 클러스터 일시 중지 및 재개 ⏸️▶️
- 단일 작업으로 모든 Redshift 클러스터 일시 중지 ⏸️📊
- 전문가처럼 클러스터 관리하기 🔍
- 스냅샷: 데이터의 가장 친한 친구 📸
- 효율적인 클러스터 관리 스크립트 📝
📚자료 섹션
- 포괄적인 YouTube 비디오🎬: 이 YouTube 재생 목록에는 이 블로그의 코드 실행과 관련된 모든 비디오가 포함되어 있습니다.
- GitHub 텍스트 파일 📄: 본 저장소에는 이 블로그에서 참조하는 모든 코드가 포함되어 있어, 프로젝트에 필요한 모든 스크립트와 도구에 액세스할 수 있습니다.
수동으로 Redshift 클러스터 만들기 🎥
시작해 볼까요? 여러분만의 Redshift 클러스터를 설정해 봅시다. 다음 단계를 따라 주세요:
- AWS Management Console에 로그인하세요: Redshift 서비스로 이동해주세요 🔍.
- 클러스터 생성하기: '클러스터 생성'을 클릭하세요. 클러스터 식별자, 노드 유형, 데이터베이스 구성과 같은 세부 정보를 입력해주세요 🛠️.
- 검토하고 시작하기: 설정을 확인하고 클러스터를 시작하세요. 이 과정은 몇 분이 소요될 수 있습니다⏳.
- 보안 그룹 및 포트 구성: 보안 그룹을 편집하고 포트 번호를 5439로 설정해주세요.
- 클러스터를 공개적으로 접속 가능하게 만들기: 작업으로 이동하여 공개적으로 접속 가능한 옵션을 활성화해주세요 🌐.
레드시프트 클러스터 생성 방법에 대한 자세한 설명은 다음을 참고하세요:
- 📺 이 비디오 튜토리얼 시청: 시각적인 학습자에게 완벽합니다!
- 📄 이 블로그 포스트를 참조: 단계별 설명서를 선호하는 경우에 유용합니다.
Python 및 Boto3를 활용한 클러스터 생성 자동화 🚀
이 섹션에서는 Boto3와 Python을 사용하여 Redshift 클러스터를 생성하는 방법을 배우게 될 거에요. 이 안내서를 통해 상세한 코드 예제와 설명을 통해 과정을 안내할 거에요.
Redshift 클러스터 생성을 위한 코드 안내
아래 이미지는 코드에서 수행되는 주요 단계를 보여줍니다:
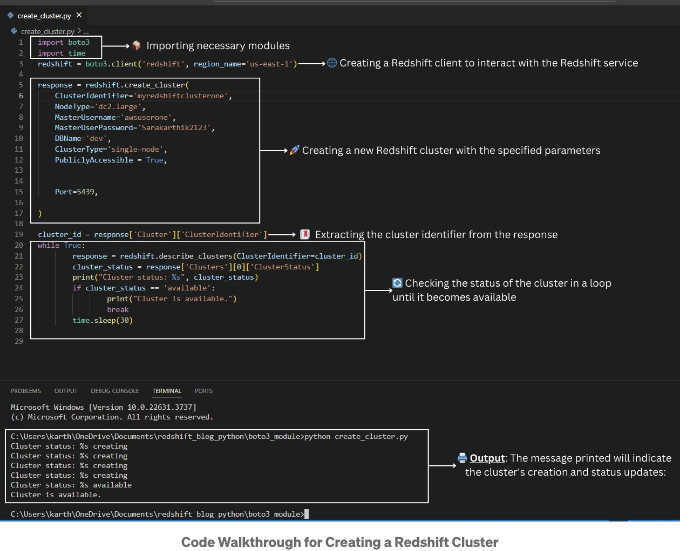
이 Python 스크립트는 Boto3를 사용하여 Amazon Redshift 클러스터를 생성합니다. 특정 매개변수로 클러스터를 설정하고 클러스터의 상태를 지속적으로 확인하여 사용 가능해질 때까지 기다립니다. 클러스터를 사용할 수 있게 되면 확인 메시지를 출력합니다.
비디오 자습서
실제 코드 실행을 볼 수 있는 비디오 자습서를 확인해보세요:
동일한 코드에 대한 링크 📎.
이 가이드를 따라하면 Python과 Boto3를 사용하여 Redshift 클러스터를 효율적으로 생성할 수 있습니다. 다음 섹션에서는 클러스터 일시 중지 및 재개에 대해 배울 것입니다 ⏸️▶️
클러스터 일시 중지 및 재개 ⏸️▶️
이 섹션에서는 Boto3와 Python을 사용하여 Redshift 클러스터의 일시 중지 및 재개 프로세스를 자동화하는 방법을 배웁니다.
1. 클러스터 재개하기 ▶️
클러스터를 다시 시작해보겠습니다. 아래는 코드 설명입니다:
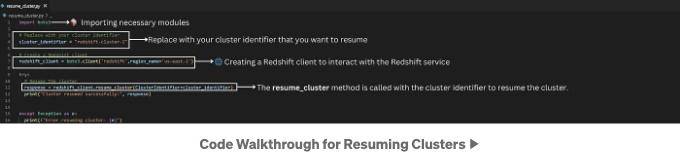
제공된 코드 스니펫은 Boto3를 사용하여 Redshift 클러스터를 재개하는 Redshift 클라이언트를 생성합니다. 클러스터가 성공적으로 재개되면 성공 메시지를 출력하고, 그렇지 않으면 발생하는 모든 오류를 잡아서 출력합니다.
비디오 자습서
위 코드가 어떻게 실행되는지 확인하려면 이 비디오 튜토리얼을 확인해보세요:
동일한 코드에 대한 링크 📎.
2. 클러스터 일시 중지 ⏸️
다음으로 클러스터를 일시 중지하는 방법에 대해 배워봅시다. 여기 코드 설명이 있습니다:
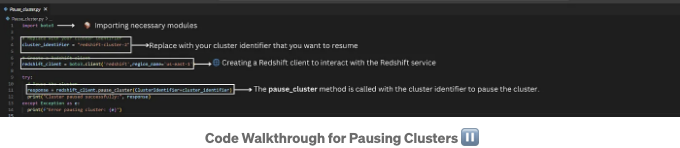
The code snippet creates a Redshift client using Boto3 to pause ⏸️ a Redshift cluster identified by cluster_identifier. If the cluster pauses successfully, it prints a success message; otherwise, it catches and prints any errors that occur during the process.
Video Tutorial
Check out this video tutorial to see the execution of the code in action:
위의 가이드를 따르면 Redshift 클러스터를 자동으로 다시 작동하고 일시 중지하는 프로세스를 효율적으로 관리할 수 있습니다. 이는 비용을 절약하고 클러스터가 필요할 때만 작동되도록 보장하는 데 도움이 될 수 있습니다.
다음 섹션에서는 모든 클러스터를 일시 중지하는 방법을 보여주는 작은 프로젝트를 살펴볼 것입니다. 기대해 주세요! 🚀
모든 Redshift 클러스터를 한 번에 일시 중지하기 ⏸️📊
이 섹션에서는 Python과 Boto3를 사용하여 모든 실행 중인 Redshift 클러스터를 자동으로 일시 중지하는 멋진 프로젝트를 살펴보겠습니다. 이 자동화는 비용을 절약하고 클러스터 관리를 간편화할 수 있습니다.
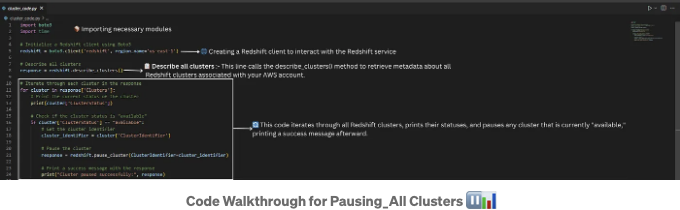
이 Python 스크립트는 Boto3를 사용하여 Amazon Redshift와 상호 작용하여 모든 클러스터를 설명하고 상태를 확인하고 사용 가능한 클러스터를 일시 중지합니다. 그렇게 하기 위해 Redshift 클라이언트의 describe_clusters 및 pause_cluster 함수를 활용하여 클러스터 상태와 일시 중지 시 클러스터 상태 및 성공 메시지를 출력합니다.
비디오 자습서
위 코드 실행을 보고 싶다면 이 비디오 튜토리얼을 확인해보세요:
동일한 코드 링크 📎.
실제 활용 사례 시나리오 ⏰🔄
모든 클러스터 일시 중지 및 모든 클러스터 재개는 다양한 시나리오에서 매우 유익할 수 있습니다.
- 예정된 다운타임: AWS Lambda와 이벤트 트리거를 사용하여 클러스터가 사용되지 않을 때 오후 6시에 모든 클러스터를 일시 중지하는 스크립트를 자동으로 예약 할 수 있습니다.
- 비용 관리: 필요한 시간인 아침 9시 전에 스크립트를 예약하여 모든 클러스터를 자동으로 다시 시작하면 효율적인 클러스터 이용과 비용 관리가 보장됩니다.
파이썬과 Boto3를 사용하여 모든 Amazon Redshift 클러스터의 일시 중지를 자동화 함으로써 효율적인 비용 관리와 운영 제어를 보장할 수 있습니다. 🌟
이 섹션에서는 파이썬과 Boto3를 사용하여 모든 Amazon Redshift 클러스터의 일시 중지를 자동화하여 비용 관리와 운영 제어를 효율적으로 보장했습니다. 다음으로 클러스터를 효과적으로 관리하는 몇 가지 기술을 탐색해 보겠습니다.
전문가처럼 클러스터 관리하기 🔍
이 섹션에서는 Python 및 Boto3를 사용하여 Amazon Redshift 클러스터를 관리하는 내용을 살펴보겠습니다. 모든 클러스터를 볼 수 있는 방법과 특정 클러스터를 삭제하는 방법을 다룰 것입니다.
1. 모든 클러스터 보기
먼저, Redshift 클러스터를 모두 검색하고 표시해 봅시다:
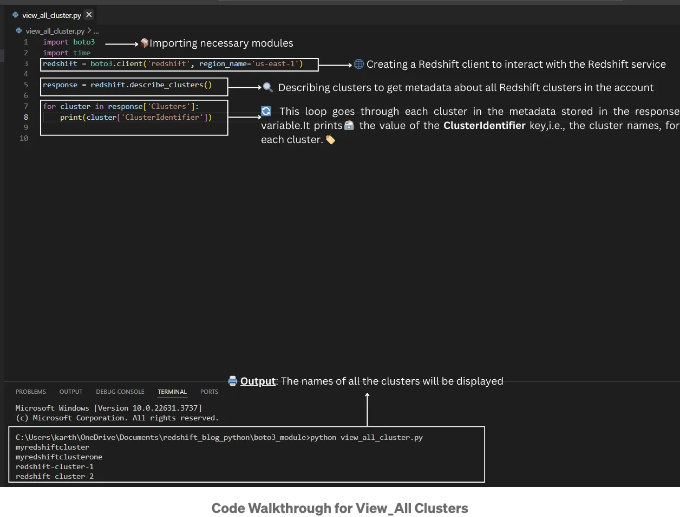
이 코드는 Boto3를 사용하여 지정된 지역(us-east-1)의 AWS Redshift 서비스에 연결하고 모든 클러스터 식별자의 목록을 검색합니다. 이 목록은 당신의 필요에 따라 필터링 및 정렬과 같은 추가 작업에 유용할 수 있습니다.
비디오 자습서
코드 실행 과정을 확인하려면 이 비디오 자습서를 확인해보세요:
동일한 코드에 대한 링크 📎.
실제 활용:
클러스터 필터링 및 정렬: 정규 표현식 (regex)을 사용하여 특정 기준에 따라 클러스터를 필터링하는 코드를 수정할 수 있습니다. 이를 통해 유지 관리 또는 삭제와 같은 특정 작업을 위해 클러스터를 대상으로할 수 있습니다.
클러스터 삭제
이제 Redshift 클러스터를 프로그래밍 방식으로 삭제하는 방법을 살펴보겠습니다.
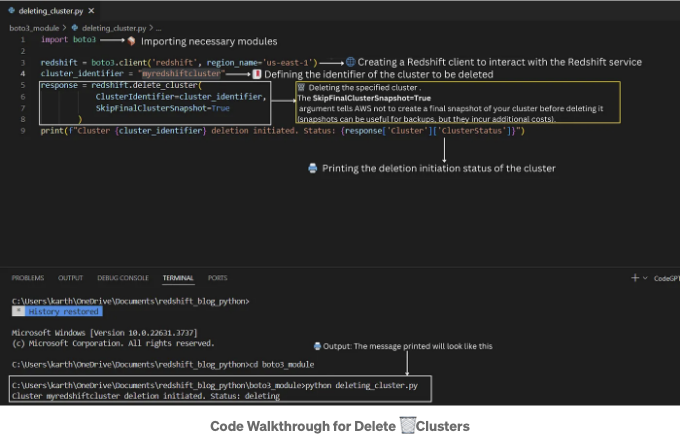
이 코드 조각은 Boto3를 사용하여 지정된 Redshift 클러스터 (myredshiftcluster)를 최종 스냅샷을 찍지 않고 삭제하는 방법을 보여줍니다. 삭제 프로세스의 현재 상태를 출력합니다.
비디오 튜토리얼
실제 코드 실행을 확인하려면 이 비디오 튜토리얼을 확인하세요:
동일한 코드에 대한 링크 📎
이제 클러스터를 관리하는 데 sol하게 이해했으니, Redshift 관리의 다음 중요한 측면인 스냅샷으로 넘어가 봅시다.
스냅샷: 데이터의 베스트 프렌드 📸
이 섹션에서는 Redshift 스냅샷의 세계에 대해 알아볼 것입니다. 데이터 백업 및 복구를위한 중요한 기능인 스냅샷을 다룰 것입니다. 포함될 내용은 다음과 같습니다:
- 스냅샷이란 무엇인가요?
- 스냅샷 목록을 위한 코드 Walkthrough
- 클러스터를 위한 스냅샷 생성
- 스냅샷 생성 및 삭제에 대한 코드 Walkthrough
# 스냅샷이란 무엇인가요?
Amazon Redshift에서 스냅샷은 클러스터의 데이터와 메타데이터를 캡처하는 클러스터의 특정 시점 백업입니다. 스냅샷은 자동화되거나 수동으로 이루어질 수 있으며, 스냅샷이 촬영된 시점의 상태로 클러스터를 복원할 수 있도록 합니다. 이는 데이터 복구, 재해 복구 및 데이터 무결성 유지를 위해 중요합니다.
# 스냅샷 목록을 위한 코드 Walkthrough
Redshift 스냅샷을 관리하기 위해, 특정 클러스터에 대한 모든 스냅샷을 나열하는 것부터 시작해보세요.
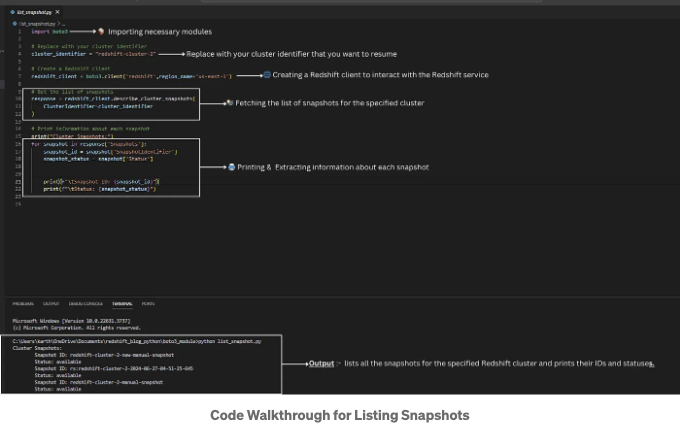
이 코드는 지정된 Redshift 클러스터의 스냅샷 목록을 가져와 표시합니다. Redshift 서비스와 상호 작용하기 위해 Boto3를 사용하여 스냅샷을 효율적으로 모니터링하고 관리할 수 있습니다.
비디오 튜토리얼
해당 코드 실행 과정을 확인하려면 이 비디오 튜토리얼을 확인해보세요:
해당 코드 링크는 여기 있습니다 📎.
클러스터에 대한 스냅샷 만들기
스냅샷을 만들면 클러스터의 현재 상태를 백업하여 필요 시 나중에 복원할 수 있습니다.
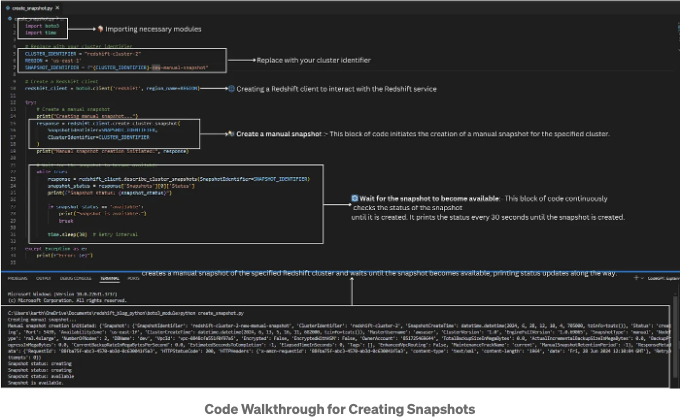
이 코드는 지정된 Redshift 클러스터의 수동 스냅샷을 생성하고 스냅샷 상태가 'available'일 때까지 기다립니다. 이렇게 함으로써 스냅샷 생성 프로세스가 완료된 후 추가 작업을 진행할 수 있습니다.
비디오 튜토리얼
실행 중인 코드를 보려면 이 비디오 튜토리얼을 확인해보세요:
동일한 코드에 대한 링크를 첨부합니다 📎.
이 섹션에서는 데이터 백업 및 복구를 위해 Amazon Redshift의 스냅샷의 중요성을 탐색했습니다. 우리는 스냅샷이 무엇인지, 스냅샷 목록 및 생성을 위한 코드 안내, 그리고 데이터 무결성 유지에 대한 실제 응용 사례를 강조했습니다.
다음 섹션에서는 효율적인 클러스터 관리에 대한 우리의 학습을 유기적으로 연결하는 실용적인 프로젝트를 살펴볼 것입니다.
효율적인 클러스터 관리 스크립트 📝
이 프로젝트는 Redshift 클러스터를 관리하는 포괄적인 스크립트를 보여줍니다. 클러스터를 재개하거나 데이터베이스를 생성하고 스냅샷을 찍거나 클러스터를 일시 중지하는 등의 작업이 가능합니다.
코드 안내
아래 이미지는 코드에서 수행되는 주요 단계를 설명합니다:
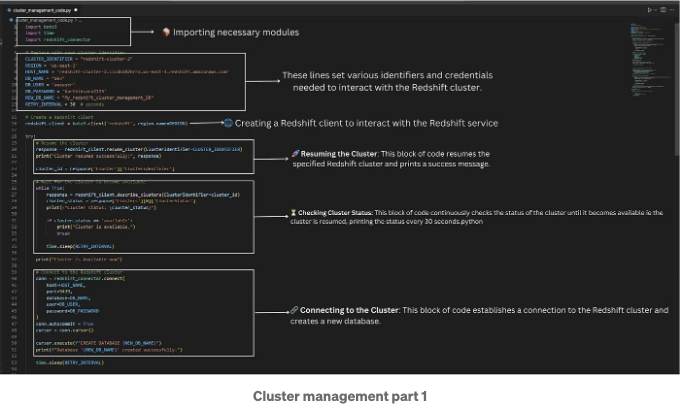
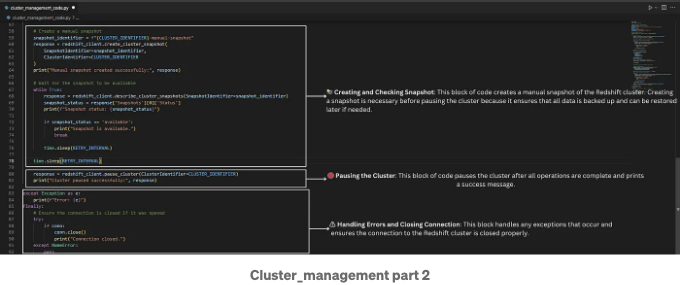
이 스크립트는 Amazon Redshift 클러스터를 관리하는 여러 핵심 작업을 자동화합니다. 일시 중지된 클러스터를 다시 시작하고 사용 가능해질 때까지 대기합니다. 클러스터가 준비되면 redshift_connector를 사용하여 클러스터에 연결하고 새 데이터베이스를 만듭니다. 그 후 클러스터의 수동 스냅샷을 만들고 스냅샷이 사용 가능해질 때까지 대기합니다. 마지막으로 스크립트는 비용을 절약하기 위해 클러스터를 일시 중지합니다. 프로세스 전반에 걸쳐 스크립트는 오류 처리를 포함하고 데이터베이스 연결이 올바르게 닫혀 있는지 확인합니다. 이 포괄적인 방법은 효율적이고 자동화된 Redshift 클러스터 관리를 보장합니다.
비디오 자습서
실행 중인 코드를 확인하려면 이 비디오 자습서를 확인해보세요:
링크를 마크다운 형식으로 변경하세요 📎.
결론
이 블로그에서는 Python과 Boto3를 사용하여 Amazon Redshift 클러스터를 관리하는 다양한 측면을 다루었습니다. 수동 및 프로그래밍 방식으로 클러스터를 생성하고, 비용 효율성을 위해 클러스터를 일시 중지하고 재개하며, 데이터 백업과 복구를 위해 스냅샷을 활용하는 등 Redshift 작업을 최적화하는 실용적이고 강력한 기술을 탐색했습니다.
제공된 단계와 코드 예제를 따르면 Redshift 클러스터 관리를 자동화하여 최적의 성능과 비용 절감을 보장할 수 있습니다. 효율적인 Redshift 클러스터 관리는 비용을 절약할 뿐만 아니라 데이터 처리 능력을 향상시켜 데이터 작업을 더 견고하고 신뢰할 수 있게 만듭니다.
더 많은 고급 기술과 프로젝트가 있는 것을 기대해 주세요. AWS 관리 기술을 더 향상시킬 수 있도록 도와 드리겠습니다. 자동화 작업을 즐기세요! 🚀💼

다음 단계
이제 Redshift 클러스터를 관리하는 탄탄한 기초가 있으므로, 다음과 같은 고급 주제를 탐험해 볼 수 있습니다:
- Redshift 클러스터에 대한 보안 모범 사례를 구현합니다.
- Redshift를 다른 AWS 서비스와 통합하여 포괄적인 데이터 솔루션을 구축합니다.
- Redshift 성능 및 쿼리 효율을 최적화합니다.
이러한 개념들을 실험하고 발전시켜 Redshift 자동화 전문가로 성장해보세요. 행운을 빕니다! 💻🌐