
서문
✔️ 아마존 베드락 지식베이스에 대해 다루겠습니다. ✔️ AWS 아키텍처를 설명합니다. ✔️ TypeScript 및 AWS CDK 코드를 살펴봅니다. ✔️ 작동 방식을 확인하기 위해 몇 가지 테스트를 수행합니다.
소개 👋🏽
이 기사에서는 Amazon Bedrock Knowledge Bases에 대해 이야기하고, 최신 비공개 회사 정보로 AI 모델을 장착하는 방법에 대해 얘기할 것입니다. 이를 통해 사용자들이 자체 사용자 정의 데이터로 AI를 활용할 수 있게 됩니다. 우리는 코드 예제와 관련된 AWS 아키텍처에 대해 설명할 것입니다.

우리의 예시에서는 'LJ Medical Center'라는 허구의 회사를 위한 사용 사례에 대해 이야기할 것입니다. 여기서 우리의 접수 직원들이 회사 정보를 질의하기 위해 AI 모델을 사용할 수 있습니다.

접대 직원은 자연어를 사용하여 사설 데이터를 쿼리할 수 있습니다. 예를 들어, 의료 분야에서 지불 지연에 대한 정책이 무엇인지 묻는 것이 있습니다.

아래에 TypeScript로 작성된 전체 코드 예제와 AWS CDK를 찾을 수 있습니다:
👇 더 나아가기 전에 — LinkedIn에서 저와 연결해주세요. 미래의 블로그 게시물과 서버리스 뉴스를 만날 수 있습니다. https://www.linkedin.com/in/lee-james-gilmore/

아마존 베드락은 무엇인가요? 🤖
이제 아마존 베드락이 무엇이고 어떻게 작동하는지 알아봅시다. 먼저 몇 가지 주요 약어를 이해하는 것부터 시작해보겠습니다.
약어
시작하기 전에, 몇 가지 약어와 그 의미에 대해 알아보겠습니다:
- FMs — Foundational Models.
- RAG — Retrieval Augmented Generation.

Bedrock Knowledge Bases란 무엇인가요? 🤖
최신 및 사용자 정의 정보를 시설 관리자(FM)에게 제공하기 위해, 기업 및 비즈니스는 RAG(Retrieval Augmented Generation) 기법을 사용합니다. 이 기법은 회사 데이터 소스에서 데이터를 가져와 프롬프트를 보다 관련성 높고 정확한 응답을 제공하기 위해 풍부하게 합니다.
지식 베이스는 사용자 쿼리에 대답하는 데뿐만 아니라 프롬프트에 맥락을 제공함으로써 기초 모델이 제공하는 프롬프트를 보강하는 데 사용될 수 있습니다.
사용자 정의 데이터를 어디에 저장하나요? 🤖
아마존 베드락 지식 베이스를 사용하면 데이터 수집부터 Amazon S3에서 데이터를 검색하고 프롬프트 추가까지 전체 RAG 워크플로우를 구현할 수 있습니다. 사용자는 데이터 소스에 맞춤 통합을 작성하거나 데이터 흐름을 관리할 필요 없이 쉽게 다중 대화를 지원할 수 있습니다.
아마존 S3에서 사용자 정의 데이터를 가리킨 후, 아마존 베드락을 사용하면 데이터를 자동으로 가져와 텍스트 블록으로 나누고 이를 임베딩으로 변환하여 벡터 데이터베이스에 저장합니다. 이 기사에서는 임베딩을 아마존 오픈서치 서버리스 벡터에 저장할 것입니다.
사용자 정의 데이터는 어떻게 저장되나요? 🤖
벡터 임베딩에는 문서 내 텍스트 데이터의 숫자 표현이 포함됩니다. 각 임베딩은 데이터의 의미나 문맥적 의미를 포착하기 위해 노력합니다. 아마존 베드락은 벡터 저장소에서 임베딩을 생성, 저장, 관리 및 업데이트하며 데이터가 항상 벡터 저장소와 동기화되도록 보장합니다.
✔️ 전처리
데이터 검색을 개선하기 위해 문서를 작은 세그먼트로 나누어 임베딩으로 변환한 후 벡터 인덱스에 저장하여 원본 문서와의 연결을 유지합니다. 이러한 임베딩은 데이터 원본에서 효율적인 쿼리 일치를 위한 의미 유사성 비교를 가능하게 합니다. 이 과정은 첨부된 이미지에 설명되어 있습니다.
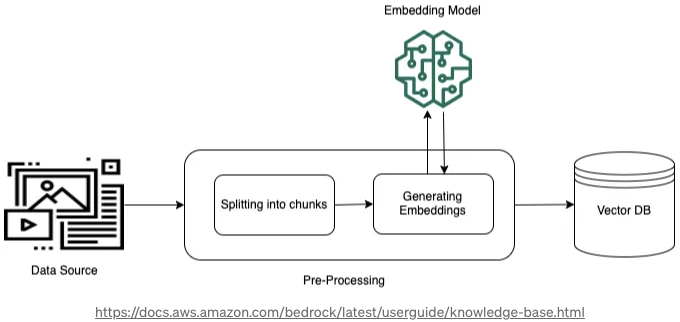
✔️ 런타임 실행
실시간으로 모델은 사용자의 쿼리를 벡터로 변환하고 의미적으로 유사한 청크를 찾기 위해 벡터 인덱스를 탐색합니다. 이러한 청크들은 사용자 프롬프트를 보강하는 데 사용되고, 그 후에 모델로 전송되어 응답을 생성합니다. 이 프로세스는 아래 이미지에서 RAG의 실행 중인 작업을 보여줍니다.
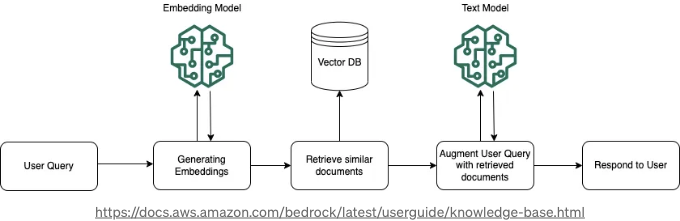
✔️ 데이터 동기화
우리의 Amazon S3 버킷에 새 문서를 업로드하면 지식 베이스 데이터 원본으로 사용하게 되는데, 이때 데이터를 주기적으로 동기화하여 색인 작업과 쿼리를 위해 지식 베이스와 동기화해야 합니다.
업데이트 동기화는 마지막 동기화 이후에 S3 버킷에 새로 추가되거나 수정된 객체들만을 처리하여 지식 베이스를 증분적으로 업데이트합니다.
무엇을 만드는 중인가요? 🛠️
자, 이제 Amazon Bedrock의 지식 베이스에 대해 심도있는 탐구를 했고, 이론적으로 어떻게 작동하는지 이해했으니, 이제 이 글에서 무엇을 만드는지 살펴보겠습니다:
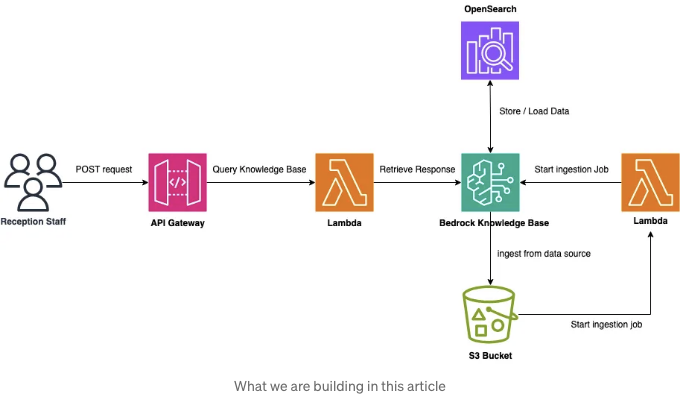
위 다이어그램에서 알 수 있듯이:
- 수신 직원 팀의 사용자는 그들의 응용 프로그램을 통해 Amazon API Gateway에 요청을 보냅니다.
- Amazon API Gateway는 쿼리를 기반으로 한 POST 요청에 따라 람다 함수를 호출합니다.
- 람다 함수는 사용자의 쿼리를 오픈서치 서버리스 벡터 저장소의 데이터로 보완하기 위해 Bedrock Knowledge Base를 호출합니다.
- S3 버킷에서 객체가 수정, 작성 또는 삭제되면 Ingestion 람다를 호출합니다.
- 람다 함수는 수정 사항이 있었기 때문에 Amazon S3 버킷의 데이터를 동기화하기 위해 Knowledge Base를 호출합니다.
이제 우리가 전체 아키텍처를 토론했으니, 이를 실제로 보고 주요 코드를 설명해 보겠습니다.
주요 코드 설명하기 👨💻
알겠어요. 우리는 이 기본 예제를 살펴보았으니 이제 TypeScript와 CDK 코드를 살펴보겠습니다. 전체 솔루션은 여기에서 찾을 수 있음을 기억해 주세요.
상태를 가지는 스택
먼저, 저희의 상태를 가지는 스택을 살펴봅시다. 아마존 베드락 지식베이스 및 데이터를 저장할 S3 버킷이 있는 스택입니다:
// 베드락 지식베이스 생성
const kb = new bedrock.KnowledgeBase(this, "BedrockKnowledgeBase", {
embeddingsModel: bedrock.BedrockFoundationModel.TITAN_EMBED_TEXT_V1,
instruction: `환자 기록에 대한 질문에 답변하는 데 사용할 지식베이스입니다.`,
});
// 환자 데이터를 저장하는 S3 버킷 생성 (베드락을 위한 소스)
this.bucket = new s3.Bucket(this, "PatientRecordsBucket", {
bucketName: "lj-medical-center-patient-records",
autoDeleteObjects: true,
removalPolicy: cdk.RemovalPolicy.DESTROY,
});
위의 코드에서는 Titan Text V1 기본 모델을 사용하고 있음을 알 수 있습니다.
다음으로, 첫 번째 배포 시에는 데이터 폴더에서 예제 문서를 S3 버킷으로 업로드해야 합니다:
// cdk 배포의 일부로 데이터가 업로드되도록 보장
new s3deploy.BucketDeployment(this, "ClientBucketDeployment", {
sources: [s3deploy.Source.asset(path.join(__dirname, "../../data/"))],
destinationBucket: this.bucket,
});
마지막으로, 지식 베이스용 데이터 소스를 생성하며, 이는 우리의 S3 버킷을 가리킵니다:
// knowledge base를 위한 s3 버킷의 데이터 소스 설정
const dataSource = new bedrock.S3DataSource(this, "DataSource", {
bucket: this.bucket,
knowledgeBase: kb,
dataSourceName: "patients",
chunkingStrategy: bedrock.ChunkingStrategy.DEFAULT,
maxTokens: 500,
overlapPercentage: 20,
});
Stateful 스택을 배포하려면 npm 스크립트 npm run deploy:stateful을 사용하고, 완료되면 콘솔에 로그인하여 '동기화'를 실행할 수 있습니다:
Stateless Stack
이제 Stateless 스택을 살펴보겠습니다. 우선 S3 트리거를 추가하여 S3 버킷 내에서 변경 사항(새 파일, 수정, 삭제 등)이 발생할 때 Ingestion Lambda 함수를 호출하는 방법을 살펴보겠습니다:
// 객체가 추가, 수정 또는 삭제될 때의 s3 이벤트 소스를 만듭니다
bucket.addEventNotification(s3.EventType.OBJECT_CREATED_PUT, new s3n.LambdaDestination(ingestionLambda));
bucket.addEventNotification(s3.EventType.OBJECT_REMOVED, new s3n.LambdaDestination(ingestionLambda));
그런 다음 Ingestion Lambda에는 데이터 소스를 동기화하기 위해 다음 코드를 실행하는 보조 어댑터가 있습니다:
import {
BedrockAgentClient,
StartIngestionJobCommand,
StartIngestionJobCommandInput,
StartIngestionJobCommandOutput,
} from "@aws-sdk/client-bedrock-agent";
import { config } from "@config";
import { logger } from "@shared/logger";
import { v4 as uuid } from "uuid";
const client = new BedrockAgentClient();
const knowledgeBaseId = config.get("knowledgeBaseId");
const dataSourceId = config.get("dataSourceId");
export async function ingestionProcess(): Promise<string> {
const input: StartIngestionJobCommandInput = {
knowledgeBaseId: knowledgeBaseId,
dataSourceId: dataSourceId,
clientToken: uuid(),
};
const command: StartIngestionJobCommand = new StartIngestionJobCommand(input);
const response: StartIngestionJobCommandOutput = await client.send(command);
logger.info(`response: ${response}`);
return JSON.stringify({
ingestionJob: response.ingestionJob,
});
}
다음으로 Lambda 함수가 동기화 수행을 허용하기 위해 필요한 IAM 정책을 살펴보겠습니다:
// ensure that the lambda function can start a data ingestion job
ingestionLambda.addToRolePolicy(
new iam.PolicyStatement({
actions: ["bedrock:StartIngestionJob"],
resources: [knowledgeBaseArn],
})
);
우리 쿼리 람다에 유사한 정책을 추가합니다. 이 정책에 따라 쿼리 람다가 Amazon Bedrock에 대해 작업을 수행할 수 있게 됩니다:
// 쿼리 람다 함수가 모델을 쿼리할 수 있도록 허용합니다
queryModelLambda.addToRolePolicy(
new iam.PolicyStatement({
actions: ["bedrock:RetrieveAndGenerate", "bedrock:Retrieve", "bedrock:InvokeModel"],
resources: ["*"],
})
);
쿼리 람다의 두 번째 어댑터에 대한 코드가 아래에 표시되어 있습니다:
import {
BedrockAgentRuntimeClient,
RetrieveAndGenerateCommand,
RetrieveAndGenerateCommandInput,
RetrieveAndGenerateCommandOutput,
} from '@aws-sdk/client-bedrock-agent-runtime';
import { config } from '@config';
const client = new BedrockAgentRuntimeClient();
const knowledgeBaseId = config.get('knowledgeBaseId');
export async function queryModel(prompt: string): Promise<string> {
const input: RetrieveAndGenerateCommandInput = {
input: {
text: prompt,
},
retrieveAndGenerateConfiguration: {
type: 'KNOWLEDGE_BASE',
knowledgeBaseConfiguration: {
knowledgeBaseId: knowledgeBaseId,
// we are using Anthropic Claude v2 in us-east-1 in this example
modelArn: `arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-v2`,
},
},
};
const command: RetrieveAndGenerateCommand = new RetrieveAndGenerateCommand(
input
);
const response: RetrieveAndGenerateCommandOutput = await client.send(command);
return response.output?.text as string;
}
마지막 단계는 우리의 Amazon API Gateway를 추가하고, /queries/ 리소스에 대해 Query Lambda 함수를 호출하도록 허용하는 것입니다.
// 우리 수의원 앱에서 사용할 API를 생성합니다
const api: apigw.RestApi = new apigw.RestApi(this, "Api", {
description: "LJ Medical Center API",
restApiName: "lj-medical-center-api",
deploy: true,
endpointTypes: [apigw.EndpointType.REGIONAL],
deployOptions: {
stageName: "prod",
dataTraceEnabled: true,
loggingLevel: apigw.MethodLoggingLevel.INFO,
tracingEnabled: true,
metricsEnabled: true,
},
});
// API에 대한 쿼리 리소스 생성
const queries: apigw.Resource = api.root.addResource("queries");
// 지식 베이스 쿼리 엔드포인트 추가 (POST) - prod/queries/
queries.addMethod(
"POST",
new apigw.LambdaIntegration(queryModelLambda, {
proxy: true,
allowTestInvoke: false,
})
);
이제 npm 스크립트 npm run deploy:stateless로 무상태 스택을 배포하고 기능을 테스트할 수 있습니다.
앱 테스트 🧪
Postman을 통한 테스팅
postman/Bedrock Knowledge Bases.postman_collection.json 파일을 사용하여 자신의 URL 정보로 테스트할 수 있습니다.
늦은 지불에 관한 간단한 쿼리를 시작해보세요:
위의 스크린샷에서 올바른 응답을 받았음을 확인할 수 있습니다:
그런 다음 다음과 같은 쿼리를 요청할 수 있습니다:
위의 쿼리에서 답변을 성공적으로 받았음을 확인할 수 있습니다:
위의 예시는 우리 접수 직원이 모든 정책에서 필요한 정보를 빠르게 찾을 수 있는 두 가지 예시에 불과합니다.
어째서 이 기능을 사용해보지 않고 가상의 환자 기록을 추가해 보시겠어요? 솔루션을 배포하는 비용을 기억해 주세요!
마무리 인사 👋🏽
이 글을 즐겁게 읽어주셨으면 공유와 피드백도 부탁드립니다!
제 유튜브 채널을 방문해 비슷한 콘텐츠를 구독해주세요!
함께 소통하고 싶어요! 아래 링크에서 저와 연계해 주세요:
만약 글을 즐겼다면, 저의 프로필 Lee James Gilmore를 팔로우하여 더 많은 글/시리즈를 만나보세요. 그리고 연락하여 인사도 잊지 마세요! 👋
나에 대해
“안녕하세요, 저는 영국을 기반으로 하는 AWS 커뮤니티 빌더, 블로거, AWS 인증 클라우드 아키텍트이자 City Electrical Factors (UK) & City Electric Supply (US)에서 글로벌 기술 및 아키텍처 총괄을 맡고 있는 Lee입니다. 지난 6년간 주로 AWS에서 풀스택 JavaScript 개발을 하였습니다.
저는 서버리스를 주장하는 사람으로, AWS, 혁신, 소프트웨어 아키텍처, 기술 전반에 관심을 가지고 있습니다.” 클래프 기능을 사용하여 이 게시물이 마음에 드셨다면 반드시 박수를 눌러주세요! (여러 번 박수를 두드릴 수 있어요!!)
_ 제공된 정보는 제 개인적인 의견이며 정보 사용에 대한 책임은 지지 않습니다. _
아래 정보도 참고하실만 합니다: