
이 글에서는 "lazypredict" 라이브러리를 소개하려고 합니다. 이 라이브러리를 사용하면 여러 개의 머신러닝 모델을 동시에 적용할 수 있습니다.
이 라이브러리는 pip로 설치할 수 있습니다:
여기에서는 mal 고객 데이터 세트를 사용합니다: 링크
데이터 세트의 처음을 살펴보겠습니다:
import pandas as pd
df = pd.read_csv('https://gist.githubusercontent.com/pravalliyaram/5c05f43d2351249927b8a3f3cc3e5ecf/raw/8bd6144a87988213693754baaa13fb204933282d/Mall_Customers.csv')
df.head()
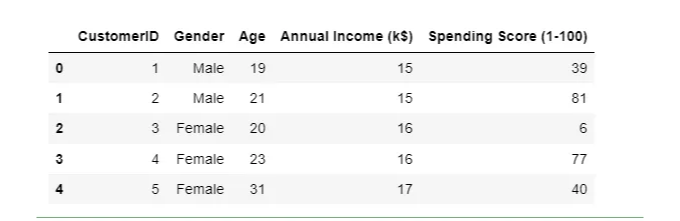
간단해요. "지출 점수"는 종속 변수 Y이고 다른 필드들은 X입니다.
그런 다음, 데이터 집합을 훈련 세트와 테스트 세트로 분할하십시오:
from sklearn.model_selection import train_test_split
X = df.loc[:, df.columns != 'Spending Score (1-100)']
y = df['Spending Score (1-100)']
X_train, X_test, y_train, y_test =…