AutoGluon이 캐글 대회를 석권한 방법 및 여러분도 이김을 거두는 방법. 4줄의 코드로 99%의 데이터 과학자들을 이겨낸 알고리즘입니다.
/assets/img/2024-07-06-AutoMLwithAutoGluonMLworkflowwithJustFourLinesofCode_0.png
AutoGluon 연구논문에서 발췌한 이 문장이 오늘 우리가 살펴볼 것을 완벽하게 요약합니다: 최소한의 코딩으로 인상적인 성능을 제공하는 머신러닝 프레임워크입니다. ML 파이프라인을 설정하는 데 4줄의 코드만 필요합니다. 그렇습니다, 4줄의 코드로 말이죠! 직접 확인해보세요:
from autogluon.tabular import TabularDataset, TabularPredictor
train_data = TabularDataset('train.csv')
predictor = TabularPredictor(label='Target').fit(train_data, presets='best_quality')
predictions = predictor.predict(train_data)
이 네 줄은 각 열의 데이터 유형을 자동으로 인식하여 데이터 전처리를 처리하고, 유용한 열 조합을 찾아 특성 공학을 수행하며, 주어진 시간 내에서 최적의 성능을 보이는 모델을 식별하기 위해 앙상블을 통해 모델을 학습합니다. 머신러닝 작업(회귀/분류)의 유형조차 명시하지 않았다는 점을 주목하세요. AutoGluon은 레이블을 검토하여 작업을 스스로 결정합니다.
이 알고리즘을 옹호하고 있나요? 꼭 그렇지는 않아요. AutoGluon의 성능을 인정하지만, 저는 데이터 과학을 카글 대회의 정확도 점수만 낼 수 있는 것으로 축소시키지 않는 솔루션을 선호합니다. 그러나 이러한 모델들이 점점 더 인기를 얻고 널리 채택되는 상황에서는, 그들이 어떻게 작동하는지, 그들 뒤에 숨은 수학과 코드를 이해하고, 그들을 활용하거나 능가하는 방법을 파악하는 것이 중요합니다.
1: AutoGluon 개요
AutoGluon은 아마존 웹 서비스(AWS)에서 만든 오픈소스 머신러닝 라이브러리입니다. 이는 데이터 준비부터 최적의 모델 선택과 설정 조정까지 전체 머신러닝 프로세스를 자동으로 처리하기 위해 설계되었습니다.
AutoGluon은 간편함과 우수한 성능을 결합한 머신 러닝 라이브러리입니다. 앙상블 학습과 자동 하이퍼파라미터 튜닝과 같은 고급 기술을 활용하여 생성하는 모델이 높은 정확도를 유지하도록 합니다. 이는 기술적인 세부사항에 갇히지 않고도 강력한 머신 러닝 솔루션을 개발할 수 있다는 것을 의미합니다.
이 라이브러리는 데이터 전처리, 특성 선택, 모델 훈련 및 평가를 처리하여 견고한 머신 러닝 모델을 구축하는 데 필요한 시간과 노력을 크게 줄여줍니다. 게다가 AutoGluon은 작은 프로젝트와 대규모 복잡한 데이터셋 모두에 적합한 규모 조정이 잘 되어 있습니다.
Tabular data의 경우, AutoGluon은 데이터를 각기 다른 그룹으로 분류하는 분류 작업과 계속적인 결과를 예측하는 회귀 작업을 모두 처리할 수 있습니다. 또한 텍스트 데이터를 지원하여 감정 분석이나 주제 분류와 같은 작업에 유용합니다. 또한 이미지 데이터를 처리하며 이미지 인식 및 물체 검출에 도움이 됩니다. AutoGluon의 여러 변형은 시계열 데이터, 텍스트 및 이미지를 더 잘 처리하기 위해 만들어졌지만, 여기서는 Tabular data를 처리하는 변형에 초점을 맞출 것입니다. 이 글이 마음에 들었는지, 앞으로 AutoGluon에 대한 깊은 탐구를 원하시는 경우 알려주세요. (AutoGluon 팀, "AutoGluon: AutoML for Text, Image, and Tabular Data." 2020)
2: AutoML의 영역
2.1: AutoML이란 무엇인가요?
AutoML은 Automated Machine Learning의 약자로, 머신러닝을 실제 문제에 자동으로 적용하는 전체 프로세스를 자동화하는 기술입니다. AutoML의 주요 목표는 머신러닝을 보다 접근 가능하고 효율적으로 만들어 사람들이 심층 전문 지식이 없이도 모델을 개발할 수 있게 하는 것입니다. 이미 알고 있듯이, 이는 데이터 전처리, 특성 공학, 모델 선택 및 하이퍼파라미터 튜닝과 같은 보통 복잡하고 시간이 많이 소요되는 작업을 처리합니다 (He et al., "AutoML: A Survey of the State-of-the-Art", 2019).
AutoML 개념은 시간이 흐름에 따라 크게 발전해 왔습니다. 초기에는 머신러닝이 특성을 신중하게 선택하고 하이퍼파라미터를 튜닝하고 올바른 알고리즘을 선택해야 했던 전문가들의 많은 수동 노력이 필요했습니다. 이 분야가 성장함에 따라 점점 크고 복잡한 데이터셋을 처리하기 위해 자동화된 필요성도 증가했습니다. 프로세스 일부를 자동화하기 위한 초기 노력이 현대 AutoML 시스템의 길을 열었습니다. 오늘날, AutoML은 앙상블 학습과 베이지안 최적화와 같은 고급 기술을 사용하여 최소한의 인간 개입으로 높은 품질의 모델을 생성합니다 (Feurer et al., "Efficient and Robust Automated Machine Learning", 2015).
AutoML 공간에는 개별적인 기능과 기능을 제공하는 여러 업체들이 등장했습니다. Amazon Web Services가 개발한 AutoGluon은 다양한 데이터 유형에서의 사용 편의성과 강력한 성능으로 유명합니다 (AutoGluon Team, "AutoGluon: AutoML for Text, Image, and Tabular Data", 2020). Google Cloud AutoML은 개발자들이 최소한의 노력으로 고품질 모델을 훈련할 수 있는 머신러닝 제품 스위트를 제공합니다. H2O.ai는 감독 및 비감독 학습 작업을 위한 자동 머신러닝 기능을 제공하는 H2O AutoML을 제공합니다 (H2O.ai, "H2O AutoML: Scalable Automatic Machine Learning", 2020). DataRobot은 기업용 AutoML 솔루션에 초점을 맞춰 모델 배포 및 관리를 위한 견고한 도구를 제공합니다. Microsoft의 Azure Machine Learning에는 다른 Azure 서비스와 통합되어 포괄적인 머신러닝 솔루션을 제공하는 AutoML 기능이 포함되어 있습니다.
2.2: AutoML의 주요 구성 요소
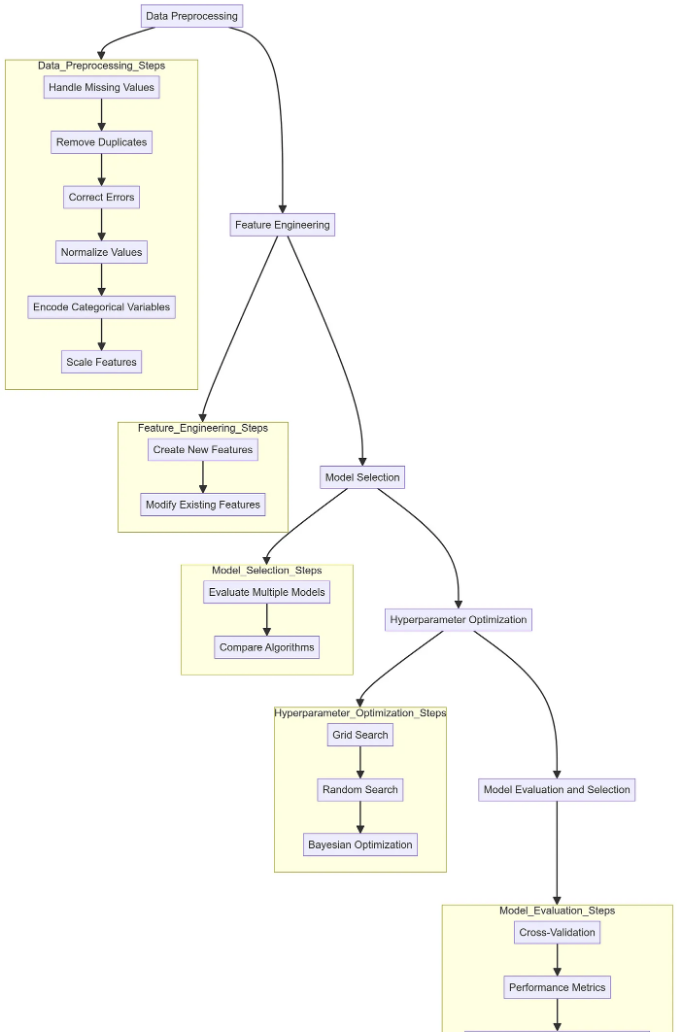
머신 러닝 파이프라인에서의 첫 번째 단계는 데이터 전처리입니다. 이는 결측값 처리, 중복 제거, 오류 수정 등을 통해 데이터를 정리하는 것을 포함합니다. 데이터 전처리에는 값의 정규화, 범주형 변수의 인코딩, 피처의 스케일 조정과 같이 분석에 적합한 형식으로 데이터를 변환하는 것도 포함됩니다. 적절한 데이터 전처리는 데이터의 품질이 머신 러닝 모델의 성능에 직접적으로 영향을 미치기 때문에 매우 중요합니다.
데이터가 정리되면, 다음 단계는 피처 엔지니어링입니다. 이 프로세스는 모델의 성능을 개선하기 위해 새로운 피처를 만들거나 기존 피처를 수정하는 것을 포함합니다. 피처 엔지니어링은 기존 데이터를 기반으로 새 열을 만드는 것처럼 간단할 수도 있고, 의미 있는 피처를 생성하기 위해 도메인 지식을 사용하는 것처럼 복잡할 수도 있습니다. 적절한 피처는 모델의 예측 능력을 높일 수 있습니다.
데이터 준비가 완료되고 피쳐가 엔지니어링되었다면, 다음 단계는 모델 선택입니다. 해결해야 할 문제에 따라 각각의 강점과 약점을 가진 다양한 알고리즘이 있습니다. AutoML 시스템은 여러 모델을 평가하여 주어진 작업에 가장 적합한 모델을 식별합니다. 이는 의사 결정 트리, 서포트 벡터 머신, 신경망 등과 같은 모델들을 비교하여 데이터와 가장 잘 작용하는 모델을 확인하는 과정을 포함할 수 있습니다.
모델을 선택한 후 다음 과제는 하이퍼파라미터 최적화입니다. 하이퍼파라미터는 머신러닝 알고리즘의 동작을 제어하는 설정들입니다. 이는 신경망의 학습률이나 의사 결정 트리의 깊이와 같은 것들을 포함할 수 있습니다. 하이퍼파라미터의 최적 조합을 찾는 것은 모델의 성능을 크게 향상시킬 수 있습니다. AutoML은 이 과정을 자동화하기 위해 그리드 탐색, 랜덤 탐색 및 베이지안 최적화와 같은 방법을 사용하여 모델이 가장 최적화되도록 보장합니다.
마지막 단계는 모델 평가 및 선택입니다. 이는 모델이 새로운 데이터에 얼마나 잘 일반화되는지 평가하기 위해 교차 검증과 같은 기술을 사용하는 과정을 포함합니다. 정확도, 정밀도, 재현율, F1-점수 등과 같은 다양한 성능 지표를 사용하여 모델의 효과를 측정합니다. AutoML 시스템은 이평가 과정을 자동화하여 선택된 모델이 주어진 작업에 가장 잘 맞는지 보장합니다. 평가가 완료되면, 최적의 성능을 보인 모델이 배포를 위해 선택됩니다. (AutoGluon 팀. "AutoGluon: 텍스트, 이미지 및 표 형식 데이터를 위한 AutoML." 2020).
2.3: AutoML의 도전과제
오토ML은 시간과 노력을 절약해주지만, 컴퓨팅 자원 측면에서 상당히 요구되는 경우가 있습니다. 하이퍼파라미터 튜닝과 모델 선택 같은 작업을 자동화하기 위해서는 여러 번의 반복과 다수의 모델 학습이 필요할 수 있는데, 이는 고성능 컴퓨팅 자원에 접근할 수 없는 소규모 조직이나 개인에게는 어려운 과제가 될 수 있습니다.
다른 어려움은 맞춤화에 대한 요구사항입니다. 오토ML 시스템은 많은 상황에서 매우 효과적일 수 있지만, 항상 원하는 요구 사항을 즉시 충족시키지 못할 수 있습니다. 때로는 자동화된 과정이 특정 데이터셋이나 문제의 고유한 측면을 완전히 포착하지 못할 수 있습니다. 사용자는 워크플로우의 일부를 조정해야 할 수 있으며, 시스템이 충분한 유연성을 제공하지 않거나 사용자가 필요한 전문 지식을 갖추지 못한 경우에는 어려울 수 있습니다.
하지만 이러한 어려움에도 불구하고, 오토ML의 혜택은 종종 단점을 상회합니다. 생산성을 크게 향상시키고 접근성을 확대하며 확장 가능한 솔루션을 제공하여 더 많은 사람들이 머신러닝의 힘을 활용할 수 있게 합니다 (Feurer 등, “효율적이고 견고한 자동화 머신러닝”, 2015).
3: AutoGluon 뒤의 수학
3.1: AutoGluon의 구조
AutoGluon의 구조는 데이터 전처리부터 모델 배포까지 전체 기계 학습 워크플로우를 자동화하는 데 설계되었습니다. 이 구조는 특정 단계를 처리하는 여러 연결된 모듈로 구성되어 있습니다.
첫 번째 단계는 데이터 모듈입니다. 이 모듈은 데이터를 로드하고 전처리하는 작업을 처리합니다. 이 모듈은 데이터를 정리하고 누락된 값을 처리하며 데이터를 분석에 적합한 형식으로 변환하는 작업을 다룹니다. 예를 들어, 누락된 값이 있는 데이터 세트 X가 있다고 가정해 보겠습니다. Data Module은 이러한 누락된 값을 평균이나 중앙값을 사용하여 보완할 수 있습니다:
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='mean')
X_imputed = imputer.fit_transform(X)
데이터 전처리가 완료되면 특성 엔지니어링 모듈이 작동합니다. 이 구성 요소는 새로운 기능을 생성하거나 기존 기능을 변환하여 모델의 예측 능력을 향상시킵니다. 범주형 변수에 대한 원핫 인코딩 또는 숫자 데이터에 다항식 기능을 생성하는 기술이 일반적입니다. 예를 들어, 범주형 변수의 인코딩은 다음과 같이 보일 수 있습니다:
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder()
X_encoded = encoder.fit_transform(X)
AutoGluon의 핵심은 모델 모듈입니다. 이 모듈에는 의사 결정 트리, 신경망 및 그래디언트 부스팅 머신과 같은 다양한 머신러닝 알고리즘이 포함되어 있습니다. 이 모듈은 데이터 세트에서 여러 모델을 훈련하고 그 성능을 평가합니다. 예를들어, 의사 결정 트리를 훈련하는 방법은 다음과 같습니다:
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier()
model.fit(X_train, y_train)
하이퍼파라미터 최적화 모듈은 각 모델에 대한 최상의 하이퍼파라미터를 자동으로 탐색합니다. 그리드 탐색, 랜덤 탐색 및 베이지안 최적화와 같은 방법을 사용합니다. Snoek 등이 2012년 논문에서 상세히 설명한 바에이지안 최적화는 탐색 프로세스를 안내하기 위해 확률 모델을 구축합니다:
from skopt import BayesSearchCV
search_space = {'max_depth': (1, 32)}
bayes_search = BayesSearchCV(estimator=DecisionTreeClassifier(), search_spaces=search_space)
bayes_search.fit(X_train, y_train)
학습 후 평가 모듈은 정확도, 정밀도, 재현율 및 F1 점수와 같은 메트릭을 사용하여 모델 성능을 평가합니다. 모델이 새로운 데이터에 잘 일반화되도록 보장하기 위해 교차 검증이 일반적으로 사용됩니다:
from sklearn.model_selection import cross_val_score
scores = cross_val_score(model, X, y, cv=5, scoring='accuracy')
mean_score = scores.mean()
AutoGluon은 여러 모델의 예측을 결합하여 더 정확한 단일 예측을 생성하는 Ensemble Module이 뛰어나다. 스태킹, 배깅, 블렌딩과 같은 기술이 사용된다. 예를 들어, 배깅은 BaggingClassifier를 사용하여 구현할 수 있다:
from sklearn.ensemble import BaggingClassifier
bagging = BaggingClassifier(base_estimator=DecisionTreeClassifier(), n_estimators=10)
bagging.fit(X_train, y_train)
마지막으로, Deployment Module은 가장 좋은 모델 또는 앙상블을 제품으로 배포하는 작업을 다룬다. 이는 모델을 내보내고, 새로운 데이터에 대한 예측을 생성하고, 모델을 기존 시스템에 통합하는 것을 포함한다:
import joblib
joblib.dump(bagging, 'model.pkl')
이러한 구성 요소들은 머신 러닝 파이프라인을 자동화하여 사용자가 빠르고 효율적으로 고품질 모델을 구축하고 배포할 수 있도록합니다.
3.2: AutoGluon에서 앙상블 학습
앙상블 학습은 AutoGluon의 핵심 기능으로, 고품질 모델을 제공하는 능력을 향상시킵니다. 여러 모델을 결합함으로써 앙상블 방법은 예측 정확도와 견고성을 향상시킵니다. AutoGluon은 세 가지 주요 앙상블 기법을 활용합니다: 스태킹, 배깅 및 블렌딩.
스태킹 스태킹은 동일한 데이터 집합에서 여러 기본 모델을 학습하고 그 예측을 상위 수준 모델에 입력 기능으로 사용하는 방식입니다. 이 접근 방식은 다양한 알고리즘의 강점을 활용하여 앙상블이 더 정확한 예측을 할 수 있도록 합니다. 스태킹 프로세스는 다음과 같이 수학적으로 표현할 수 있습니다:
/assets/img/2024-07-06-AutoMLwithAutoGluonMLworkflowwithJustFourLinesofCode_2.png
여기서 h_1은 기본 모델을 나타내며, h_2는 메타 모델입니다. 각 기본 모델 h_1은 입력 피처 x_i를 가져와 예측을 생성합니다. 이러한 예측은 메타 모델 h_2의 입력 피처로 사용되어 최종 예측 y^가 이루어집니다. 다양한 기본 모델의 출력을 결합함으로써 스태킹은 데이터의 보다 넓은 범위의 패턴을 포착하여 예측 성능을 향상시킬 수 있습니다.
배깅 배깅은 Bootstrap Aggregating의 줄임말로, 동일한 모델의 여러 인스턴스를 데이터의 다른 부분집합에 학습시킴으로써 모델의 안정성과 정확도를 향상시킵니다. 이러한 부분집합은 원본 데이터셋을 대체로 무작위로 샘플링하여 생성됩니다. 최종 예측은 일반적으로 회귀 작업의 경우 모든 모델의 예측을 평균 내거나 분류 작업의 경우 다수결 투표로 이루어집니다.
수학적으로, 배깅은 다음과 같이 표현할 수 있습니다:
회귀 분석:
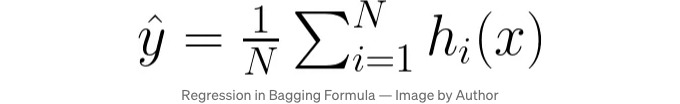
분류:
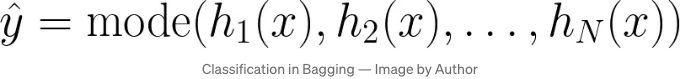
각각 데이터 하위 집합에서 훈련된 i번째 모델을 h_i로 나타냅니다. 회귀의 경우, 최종 예측 값 y^는 각 모델이 만든 예측의 평균입니다. 분류의 경우, 최종 예측 값 y^는 모델들 중 가장 빈도가 높은 클래스로 예측됩니다.
배깅의 분산 감소 효과는 다수의 모델에서 예측의 평균이 기대값으로 수렴하여 전체 분산을 줄이고 예측의 안정성을 향상시키는 큰 수의 법칙에 의해 설명될 수 있습니다. 이는 아래와 같이 설명할 수 있습니다:
/assets/img/2024-07-06-AutoMLwithAutoGluonMLworkflowwithJustFourLinesofCode_5.png
데이터의 다른 하위 집합에서 훈련함으로써 배깅은 오버피팅을 줄이고 모델의 일반화 성능을 향상시키는 데 도움이 됩니다.
Blending Blending은 stacking과 유사하지만 더 간단하게 구현됩니다. Blending에서 데이터는 학습 세트와 검증 세트로 분할됩니다. 기본 모델은 학습 세트에서 학습되며, 검증 세트에서의 예측값은 최종 모델인 블렌더 또는 메타-러너를 학습하는 데 사용됩니다. Blending은 홀드아웃 검증 세트를 사용하여 구현이 빠를 수 있습니다:
# 단순한 학습-검증 분리를 사용한 블렌딩 예시
train_meta, val_meta, y_train_meta, y_val_meta = train_test_split(X, y, test_size=0.2)
base_model_1.fit(train_meta, y_train_meta)
base_model_2.fit(train_meta, y_train_meta)
preds_1 = base_model_1.predict(val_meta)
preds_2 = base_model_2.predict(val_meta)
meta_features = np.column_stack((preds_1, preds_2))
meta_model.fit(meta_features, y_val_meta)
이러한 기술은 최종 예측이 더 정확하고 견고하게 되도록 보장하며, 다중 모델의 다양성과 강점을 활용하여 우수한 결과를 제공합니다.
3.3: 하이퍼파라미터 최적화
하이퍼파라미터 최적화는 모델의 성능을 극대화하기 위해 최적의 설정을 찾는 작업을 말합니다. AutoGluon은 베이지안 최적화, 조기 중지, 스마트 자원 할당과 같은 고급 기술을 활용하여 이 프로세스를 자동화합니다.
베이지안 최적화 베이지안 최적화는 목적 함수의 확률 모델을 구축하여 최적의 하이퍼파라미터 세트를 찾는 것을 목표로 합니다. 이는 이전 평가 결과를 활용하여 다음에 시도할 하이퍼파라미터를 결정하는 데 도움을 줍니다. 이는 특히 크고 복잡한 하이퍼파라미터 공간을 효율적으로 탐색하고 최적 구성을 찾기 위해 필요한 평가 수를 줄이는 데 유용합니다.
여기서 f(θ)는 최적화하려는 목적 함수를 나타내며, 예를 들어 모델 정확도나 손실입니다. θ는 하이퍼파라미터를 나타냅니다. E[f(θ)]는 하이퍼파라미터 θ가 주어졌을 때 목적 함수의 기대값을 나타냅니다.
베이지안 최적화에는 두 가지 주요 단계가 포함됩니다:
- Surrogate Modeling: 이전 평가를 기반으로 목적 함수를 근사하는 확률 모델, 일반적으로 가우시안 프로세스가 구축됩니다.
- Acquisition Function: 이 함수는 탐색(하이퍼파라미터 공간의 새로운 영역을 시도)과 활용(잘 수행하는 영역에 집중)을 균형있게 고려하여 다음 세트의 하이퍼파라미터를 결정합니다. 일반적인 획득 함수로는 예상 향상(EI) 및 상한 신뢰구간(UCB)이 포함됩니다.
최적화는 최적의 하이퍼파라미터 집합에 도달할 때까지 후보 모델을 실제로 평가하는 횟수를 그리드나 무작위 검색 방법에 비해 줄일 수 있도록 순환적으로 대리 모델과 획득 함수를 업데이트합니다.
조기 중지 기술 조기 중지는 오버피팅을 방지하고 검증 세트에서 모델의 성능 향상이 멈출 때 교육 프로세스를 중단하여 교육 시간을 단축합니다. AutoGluon은 교육 중에 모델의 성능을 모니터링하고 추가 교육이 큰 향상을 기대하기 힘들 때 프로세스를 중지합니다. 이 기술은 계산 자원을 절약할 뿐만 아니라 모델이 새로운 데이터에도 잘 일반화되도록 보장합니다.
from sklearn.model_selection import train_test_split
from sklearn.metrics import log_loss
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2)
model = DecisionTreeClassifier()
best_loss = np.inf
for epoch in range(100):
model.fit(X_train, y_train)
val_preds = model.predict(X_val)
loss = log_loss(y_val, val_preds)
if loss < best_loss:
best_loss = loss
else:
break
자원 할당 전략 효과적인 자원 할당은 제한된 컴퓨팅 자원을 다룰 때 하이퍼파라미터 최적화에 중요합니다. AutoGluon은 다양한 성능 최적화 전략을 사용합니다. 시스템은 초기에 일부 데이터 또는 더 적은 에폭으로 모델을 훈련하여 빠르게 잠재력을 평가합니다. 유망한 모델에는 이후에 더 많은 자원이 할당되어 철저한 평가를 수행합니다. 이 접근 방식은 탐색과 활용을 균형 있게 유지하여 컴퓨팅 자원이 효율적으로 사용되도록 합니다:
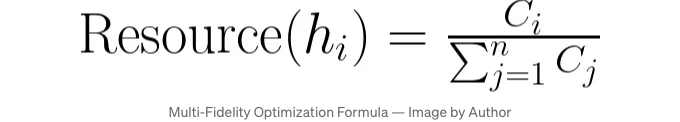
이 공식에서:
- h_i는 i번째 모델을 나타냅니다.
- C_i는 모델 h_i와 관련된 비용으로, 계산 시간이나 사용된 자원과 같은 것들을 의미합니다.
- Resource(h_i)는 모델 h_i에 할당된 총 자원 비율을 나타냅니다.
먼저 낮은 충실도를 가진 모델을 학습합니다(예: 더 적은 데이터 포인트 또는 epoch 사용). Multi-fidelity 최적화를 통해 빠르게 유망한 후보자를 식별합니다. 그런 후보자들은 더 높은 충실도로 학습시켜, 계산 자원을 효율적으로 사용한다는 것을 보장합니다. 이 방법은 하이퍼파라미터 공간의 탐색과 이미 알려진 좋은 구성을 활용하는 것을 균형 있게 유지하여, 효율적이고 효과적인 하이퍼파라미터 최적화를 이끌어냅니다.
3.4: 모델 평가 및 선택
모델 평가 및 선택은 선정된 모델이 새로운, 보지 못한 데이터에서 잘 수행되도록 보장합니다. AutoGluon은 교차 검증 기술, 성능 지표 및 자동 모델 선택 기준을 사용하여 이 프로세스를 자동화합니다.
교차 검증 기법 교차 검증은 데이터를 여러 폴드로 분할하고 모델을 서로 다른 하위 집합에서 훈련한 후 나머지 부분에서 유효성을 검사하는 과정을 말합니다. AutoGluon은 k-fold cross-validation과 같은 기술을 사용합니다. 데이터가 k개의 하위 집합으로 나뉘고 모델이 k번 훈련 및 유효성을 검사하며 각 시도마다 다른 하위 집합을 검증 세트로 사용합니다. 이를 통해 모델의 성능을 신뢰할 수 있는 추정치로 얻을 수 있으며 특정 train-test 분할에 의한 평가가 편향되지 않도록 합니다.
성능 지표 모델의 품질을 평가하기 위해 AutoGluon은 특정 작업에 따라 다양한 성능 지표를 활용합니다. 분류 작업의 경우 일반적으로 정확도, 정밀도, 재현율, F1 점수 및 ROC 곡선 아래 영역 (AUC-ROC)과 같은 지표가 사용됩니다. 회귀 작업의 경우 평균 절대 오차 (MAE), 평균 제곱 오차 (MSE), R제곱 등의 지표가 자주 사용됩니다. AutoGluon은 평가 과정에서 이러한 지표를 자동으로 계산하여 모델의 강점과 약점을 종합적으로 파악할 수 있습니다:
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
y_pred = model.predict(X_val)
accuracy = accuracy_score(y_val, y_pred)
precision = precision_score(y_val, y_pred)
recall = recall_score(y_val, y_pred)
f1 = f1_score(y_val, y_pred)
자동 모델 선택 기준 모델을 평가한 후 AutoGluon은 최상의 성능을 발휘하는 모델을 선택하는 자동 기준을 사용합니다. 이때는 다양한 모델들 사이의 성능 지표를 비교하고, 해당 작업에 가장 관련성 높은 지표에서 우수한 성과를 보이는 모델을 선택합니다. AutoGluon은 또한 모델 복잡성, 학습 시간, 자원 효율성과 같은 요소도 고려합니다. 자동 모델 선택 프로세스는 선택된 모델이 우수한 성능을 보이는 것뿐만 아니라, 현실 세계 시나리오에서 실제로 배포하고 사용하기에 실용적인지를 보장합니다. 이 선택을 자동화함으로써, AutoGluon은 인간의 편향을 제거하고 최고의 모델을 선택하는 것에 일관되고 객관적인 접근을 보장합니다:
best_model = max(models, key=lambda model: model['score'])
4: Python에서의 AutoGluon
AutoGluon을 사용하기 위해 환경을 설정해야 합니다. 이에는 필요한 라이브러리와 종속성을 설치하는 과정이 포함됩니다.
파이프를 사용하여 AutoGluon을 설치할 수 있어요. 터미널이나 명령 프롬프트를 열고 다음 명령을 실행해주세요:
pip install autogluon
이 명령은 AutoGluon과 필요한 종속성을 함께 설치할 거에요.
다음으로 데이터를 다운로드해야 해요. 이 예제용 데이터 집합을 다운로드하려면 Kaggle을 설치해야 해요:
pip install kaggle
설치가 완료되면 터미널에서 이 명령을 실행하여 데이터 세트를 다운로드하세요. 노트북 파일이 있는 동일한 디렉토리에 있는지 확인해주세요:
mkdir data
cd data
kaggle competitions download -c playground-series-s4e6
unzip "Academic Succession/playground-series-s4e6.zip"
또는 최근 Kaggle 대회 "Academic Success Dataset"을 통해 데이터 세트를 수동으로 다운로드할 수 있습니다. 이 데이터 세트는 상업적 이용을 위해 무료로 제공됩니다.
환경 설정이 완료되면 AutoGluon을 사용하여 기계 학습 모델을 구축하고 평가할 수 있습니다. 먼저 데이터 세트를 로드하고 준비해야 합니다. AutoGluon을 사용하면이 프로세스를 간단하게 수행할 수 있습니다. 학습 데이터가 포함 된 train.csv라는 CSV 파일이 있다고 가정해보십시오.
from autogluon.tabular import TabularDataset, TabularPredictor
# 데이터 세트 로드
train_df = TabularDataset('data/train.csv')
데이터를 로드 한 후에 AutoGluon을 사용하여 모델을 훈련할 수 있습니다. 이 예에서는 'Target'라는 대상 변수를 예측하는 모델을 훈련하고 평가 메트릭으로 정확도를 사용합니다. 또한 하이퍼파라미터 튜닝과 자동 스택을 활성화하여 모델 성능을 향상시키겠습니다.
# 모델 훈련
predictor = TabularPredictor(
label='Target',
eval_metric='accuracy',
verbosity=1
).fit(
train_df,
presets=['best_quality'],
hyperparameter_tune=True,
auto_stack=True
)
훈련 후에 모델의 성능을 평가할 수 있습니다. 리더보드를 사용하여 모델이 훈련 데이터에 대해 어떻게 수행되는지 요약된 정보를 제공합니다:
# 모델 평가
리더보드 = predictor.leaderboard(train_df, silent=True)
print(리더보드)
리더보드를 통해 AutoGluon에 의해 훈련된 모든 모델을 자세히 비교할 수 있습니다.
/assets/img/2024-07-06-AutoMLwithAutoGluonMLworkflowwithJustFourLinesofCode_9.png
주요 열을 자세히 살펴보겠습니다:
- model: 이 열은 모델의 이름을 나열합니다. 예를 들어, RandomForestEntr_BAG_L1은 엔트로피를 기준으로 사용하고 레벨 1에서 배깅한 랜덤 포레스트 모델을 의미합니다.
- score_test: 이는 데이터셋에 대한 모델의 정확도를 보여줍니다. 일부 모델의 경우 1.00의 점수는 완벽한 정확도를 의미합니다. 이름과는 반대로, score_test는 모델 훈련 중에 사용된 훈련 데이터셋을 나타냅니다.
- score_val: 이는 검증 데이터셋에 대한 모델의 정확도를 보여줍니다. 모델이 보이지 않는 데이터에서 얼마나 잘 수행되는지 보여주므로 주의깊게 살펴보세요.
- eval_metric: 여기서 사용된 평가 지표인 정확도.
- pred_time_test: 테스트 데이터에 대한 예측 시간.
- pred_time_val: 검증 데이터에 대한 예측 시간.
- fit_time: 모델 훈련에 소요된 시간.
- pred_time_test_marginal: 테스트 데이터셋에서 앙상블 모델에 의해 추가된 예측 시간.
- pred_time_val_marginal: 검증 데이터셋에서 앙상블 모델에 의해 추가된 예측 시간.
- fit_time_marginal: 앙상블 모델에서 추가된 훈련 시간.
- stack_level: 모델의 스태킹 레벨을 나타냅니다. 레벨 1 모델은 기본 모델이며, 레벨 2 모델은 레벨 1 모델의 예측을 특성으로 사용하는 메타 모델입니다.
- can_infer: 모델이 추론에 사용될 수 있는지를 나타내는 표시입니다.
- fit_order: 모델이 훈련된 순서.
제공된 리더보드를 살펴보면, RandomForestEntr_BAG_L1 및 RandomForestGini_BAG_L1과 같은 일부 모델은 완벽한 훈련 정확도(1.000000)를 보이지만 약간 낮은 검증 정확도를 가지며, 잠재적인 과적합을 시사합니다. 레벨 1 모델의 예측을 결합하는 WeightedEnsemble_L2는 일반적으로 베이스 모델의 강점을 균형있게 유지하여 좋은 성능을 보여줍니다.
LightGBMLarge_BAG_L1 및 XGBoost_BAG_L1과 같은 모델은 경쟁력 있는 검증 점수와 합리적인 훈련 및 예측 시간을 가지고 있어, 배포를 위한 강력한 후보 모델이 될 수 있습니다.
fit_time 및 pred_time 열은 각 모델의 계산 효율성에 대한 통찰을 제공하며, 이는 실용적인 응용 프로그램에 중요합니다.
리더보드 외에 AutoGluon은 균형 잡힌 데이터 세트를 처리하고 하이퍼파라미터 튜닝을 수행하며, 훈련 프로세스를 사용자 정의하는 여러 고급 기능을 제공합니다.
fit 메서드의 매개변수를 조정하여 훈련 프로세스의 다양한 측면을 사용자 정의할 수 있습니다. 예를 들어, 훈련 반복 횟수를 변경하거나 사용할 다른 알고리즘을 지정하거나 각 알고리즘에 맞춤형 하이퍼파라미터를 설정할 수 있습니다.
from autogluon.tabular import TabularPredictor, TabularDataset
# 데이터 세트 로드
train_df = TabularDataset('train.csv')
# 사용자 정의 하이퍼파라미터 정의
hyperparameters = {
'GBM': {'num_boost_round': 200},
'NN': {'epochs': 10},
'RF': {'n_estimators': 100},
}
# 사용자 정의 설정으로 모델 훈련
predictor = TabularPredictor(
label='Target',
eval_metric='accuracy',
verbosity=2
).fit(
train_data=train_df,
hyperparameters=hyperparameters
)
불균형 데이터셋은 도전적일 수 있지만 AutoGluon은 이를 효과적으로 처리할 수 있는 도구를 제공합니다. 소수 클래스의 오버샘플링, 다수 클래스의 언더샘플링, 또는 비용 민감한 학습 알고리즘 적용과 같은 기술을 사용할 수 있습니다. AutoGluon은 데이터셋에서 불균형을 자동으로 감지하고 처리할 수 있습니다.
Markdown 형식의 표로 변경하였습니다.
from autogluon.tabular import TabularPredictor, TabularDataset
# 데이터셋 로드
train_df = TabularDataset('train.csv')
# 사용자 지정 매개변수 지정하여 불균형 데이터셋 처리
# AutoGluon이 내부적으로 처리할 수 있지만 명확히하기 위해 여기서 지정
hyperparameters = {
'RF': {'n_estimators': 100, 'class_weight': 'balanced'},
'GBM': {'num_boost_round': 200, 'scale_pos_weight': 2},
}
# 불균형 처리를 위한 설정으로 모델 훈련
predictor = TabularPredictor(
label='Target',
eval_metric='accuracy',
verbosity=2
).fit(
train_data=train_df,
hyperparameters=hyperparameters
)
모델 성능 최적화를 위해 하이퍼파라미터 튜닝이 중요합니다. AutoGluon은 베이지안 최적화와 같은 고급 기술을 사용하여 이 과정을 자동화합니다. 하이퍼파라미터 튜닝을 활성화하려면 fit 메서드에서 hyperparameter_tune=True로 설정할 수 있습니다.
from autogluon.tabular import TabularPredictor, TabularDataset
# 데이터셋 로드
train_df = TabularDataset('train.csv')
# 하이퍼파라미터 튜닝을 적용하여 모델 훈련
predictor = TabularPredictor(
label='Target',
eval_metric='accuracy',
verbosity=2
).fit(
train_data=train_df,
presets=['best_quality'],
hyperparameter_tune=True
)
자동 머신 학습 모델을 능가할 수 있는 방법에 대해 알아보겠습니다. 손실 지표를 개선하는 것을 주요 목표로 삼고, 지연 시간, 계산 비용 또는 다른 지표에 초점을 맞추는 대신 고려해 보겠습니다.
딥러닝에 적합한 대규모 데이터셋이 있다면, 딥러닝 아키텍처를 실험하는 것이 더 쉬울 수 있습니다. 자동 머신 학습 프레임워크는 이 영역에서 어려움을 겪을 수 있습니다. 딥러닝은 데이터셋에 대한 깊은 이해를 필요로 하며, 모델을 맹목적으로 적용하는 것은 많은 시간과 자원을 소비할 수 있습니다. 다음은 딥러닝을 시작하는 데 도움이 되는 몇 가지 자료입니다:
그러나 실제 도전은 전통적인 머신 러닝 작업에서 자동 머신 학습 모델을 능가하는 데 있습니다. 자동 머신 학습 시스템은 일반적으로 앙상블을 사용하므로, 결과적으로 마찬가지일 가능성이 높습니다. 좋은 시작 전략은 먼저 AutoML 모델을 맞추는 것일 수 있습니다. 예를 들어, AutoGluon을 사용하여 어떤 모델이 가장 잘 수행되었는지 확인할 수 있습니다. 그런 다음 이러한 모델을 가져와 AutoGluon이 사용한 앙상블 아키텍처를 재현할 수 있습니다. Optuna와 같은 기술로 이러한 모델을 더 최적화하여 더 나은 성능을 달성할 수도 있습니다. Optuna를 정복하는 포괄적인 안내서:
또한 특성 엔지니어링에 도메인 지식을 적용하는 것이 도움이 될 수 있습니다. 데이터의 구체적인 내용을 이해하면 의미 있는 특성을 생성할 수 있어 모델의 성능을 크게 향상시킬 수 있습니다. 적용 가능한 경우, 데이터셋을 확장하여 더 다양한 학습 예제를 제공함으로써 모델의 견고성을 향상시킬 수 있습니다.
위 전략들을 초기 AutoML 모델로부터 얻은 통찰과 결합하여, 자동화된 방식을 능가하고 뛰어난 결과를 달성할 수 있습니다.
결론
AutoGluon은 데이터 전처리부터 모델 배포까지 모든 것을 자동화하여 머신러닝 프로세스를 혁신합니다. 최첨단 아키텍처, 강력한 앙상블 학습 기술 및 정교한 하이퍼파라미터 최적화를 통해, AutoGluon은 초보자와 경험 많은 데이터 과학자에게 필수 도구로 자리매김하고 있습니다. AutoGluon을 사용하면 복잡하고 시간 소모적인 작업을 간소화된 워크플로우로 변환하여, 전례없는 속도와 효율성으로 최고 수준의 모델을 구축할 수 있습니다.
그러나 머신러닝에서 진정으로 뛰어나기 위해서는 AutoGluon에만 의존하는 것이 아닌, 핵심 모델 전략에 대한 통찰을 얻고 프로젝트를 가속화하기 위한 토대로 활용해야 합니다. 거기서부터 데이터를 이해하고 효과적인 모델 전략을 적용하기 위해 도메인 지식을 활용하세요. 사용자 지정 모델을 실험하고 AutoGluon의 초기 제안을 넘어서 세밀하게 조정해보세요.
참고 문헌
- Erickson, N., Mueller, J., Charpentier, P., Kornblith, S., Weissenborn, D., Norris, E., … & Smola, A. (2020). AutoGluon-Tabular: Structured Data에 대한 견고하고 정확한 AutoML. arXiv 사전 인쇄 arXiv:2003.06505.
- Snoek, J., Larochelle, H., & Adams, R. P. (2012). 머신러닝 알고리즘의 실용적인 베이지안 최적화. 신경 정보 처리 시스템 발전, 25.
- Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., … & Duchesnay, É. (2011). Scikit-learn: Python에서 머신러닝. 기계 학습 연구 저널, 12(Oct), 2825–2830.
- AutoGluon 팀. “AutoGluon: 텍스트, 이미지 및 테이블 데이터용 AutoML.” 2020.
- Feurer, Matthias 등. “효율적이고 견고한 자동화된 머신러닝.” 2015.
- He, Xin 등. “AutoML: 최신 기술 조사.” 2020.
- Hutter, Frank 등. “자동화된 머신러닝: 방법, 시스템, 도전과제.” 2019.
- H2O.ai. “H2O AutoML: 확장 가능한 자동 머신러닝.” 2020.